fromsqlalchemyimportcreate_engine,String,selectfromsqlalchemy.ormimportDeclarativeBase,Mapped,mapped_column,sessionmaker# 1. DB 연결 설정
engine=create_engine("sqlite:///app.db",echo=True)# 2. ORM Base 선언
classBase(DeclarativeBase):pass# 3. 모델 선언
classUser(Base):__tablename__="users"id:Mapped[int]=mapped_column(primary_key=True)name:Mapped[str]=mapped_column(String(50))email:Mapped[str]=mapped_column(String(100),unique=True)# 4. 테이블 생성
Base.metadata.create_all(engine)# 5. Session 생성기
SessionLocal=sessionmaker(bind=engine)# 6. 데이터 추가
withSessionLocal()assession:user=User(name="Kim",email="kim@example.com")session.add(user)session.commit()# 7. 데이터 조회
withSessionLocal()assession:stmt=select(User).where(User.email=="kim@example.com")user=session.scalars(stmt).first()print("---- Result ----")print(user.id,user.name,user.email)
1
2
---- Result ----
1 Kim kim@example.com
(3) DB와 연결하기 Engine
DB와의 연결은 보통 sqlalchemy.create_engine() 을 통해 수행한다.
해당 함수에 DB URL 파라미터를 꼭 제공해야 한다.
해당 함수는 engine 이라는 객체를 반환하는데, 하나의 engine 은 여러 DB API connection을 관리한다.
fromsqlalchemyimportcreate_engine# SQLite (파일 기반 작동시)
sqlite_url="sqlite:///app.db"engine=create_engine(sqlite_url)# SQLite (메모리 기반 작동시)
sqlite_url="sqlite:///:memory:"engine=create_engine(sqlite_url)# PostgreSQL
p_url="postgresql+psycopg://user:password@서버ip:포트번호/DB이름"engine=create_engine(p_url)# MySQL / MariaDB
m_url="mysql+pymysql://user:password@서버ip:포트번호/DB이름?charset=utf8mb4"engine=create_engine(m_url)# Oracle
o_url="oracle+oracledb://user:password@서버ip:포트번호/?service_name=서비스이름"o_url="oracle+oracledb://user:password@서버ip:포트번호/SID"# sid 방법
echo=True 옵션을 주면, 트랜잭션 실행시 발생하는 로그가 출력된다.
1
2
3
4
fromsqlalchemyimportcreate_engineengine=create_engine("DB_URL",echo=True)# echo : 트랜잭션 실행에 따른 로그 출력 여부
(4) 데이터 모델
a. 데이터모델의 선언
SQLAlchemy 그리고 ORM의 핵심적인 부분
데이터 모델을 파이썬의 Class 형식으로 표현하는 방법이다.
보통 DeclarativeBase 클래스를 상속받아 사용. (SQLAlchemy ORM 모델 클래스들이 상속받는 기준 클래스)
즉, Base 는 ORM 모델들을 SQLAlchemy가 인식할 수 있도록 등록하는 중심점이라고 볼 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
fromsqlalchemy.ormimportDeclarativeBaseclassBase(DeclarativeBase):passclassUser(Base):# 테이블 이름
__tablename__="users"# 컬럼
id:Mapped[int]=mapped_column(primary_key=True)name:Mapped[str]=mapped_column(String(50))email:Mapped[str]=mapped_column(String(100),unique=True)# 그 외 테이블 설정
__table_args__={"schema":"service_a"# e.g. postgres : 이 테이블이 속한 스키마 지정
"mysql_collate":"utf8mb4_bin"# e.g. mysql : 이 테이블의 collation
}
b. 테이블이름
테이블 이름은 데이터모델 클래스의 __tablename__ 속성값에 할당한다.
1
2
3
classUser(Base):# 테이블 이름
__tablename__="users"
c. 컬럼 선언
RDB의 컬럼은 데이터모델 클래스의 “속성(attribute)”로 표현한다.
이 때, 각 속성에 대응해 mapped_column() 함수를 할당함으로써 해당 속성이 컬럼임을 설정한다.
또한 Mapped 를 사용해 속성의 데이터타입과, 이와 매핑되는 RDB 컬럼이나 관계를 표시하는 타입힌팅을 할 수 있다.
주의
server_onupdate는 SQLAlchemy가 “이 컬럼은 DB에서 UPDATE 때 바뀔 수 있다”고 인식하게 해주는 설정에 가깝다.
따라서 DB가 실제로 UPDATE 때 값을 바꾸려면 DB 자체에 ON UPDATE CURRENT_TIMESTAMP, trigger 같은 설정이 필요할 수 있다.
h. 외래키(Foreign Key)
외래키 관계를 선언할 때에는 sqlalchemy.ForeignKey 를 사용해 컬럼을 선언한다.
fromsqlalchemyimportcreate_enginefromsqlalchemy.ormimportDeclarativeBase,Mapped,mapped_columnfromsqlalchemyimportString,Integer,DateTimeengine=create_engine("DB URL",echo=True)classBase(DeclarativeBase):passclassUsers(Base):__tablename__="users"id:Mapped[int]=mapped_column(Integer,comment="user id",primary_key=True,autoincrement=True)name:Mapped[str]=mapped_column(String(200),comment="real name of user")email:Mapped[str]=mapped_column(String(200),comment="email address of user")age:Mapped[int]=mapped_column(Integer,comment="age of user")classPlants(Base):__tablename__="plants"id:Mapped[int]=mapped_column(Integer,comment="plant id",primary_key=True,autoincrement=True)name:Mapped[str]=mapped_column(String(200),comment="nickname of plant")birthday:Mapped[str]=mapped_column(DateTime,comment="birthday of plant",nullable=True)user_id:Mapped[int]=mapped_column(Integer,comment="owner of plant")Base.metadata.create_all(bind=engine)
아래와 같이 생성됨
c. 단일 테이블 생성하기
단일 테이블을 생성할 때에는 데이터모델클래스.__table__.create() 메서드를 사용하면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
fromsqlalchemyimportcreate_enginefromsqlalchemy.ormimportDeclarativeBase,Mapped,mapped_columnfromsqlalchemyimportString,Integer,DateTimeengine=create_engine("DB URL",echo=True)classBase(DeclarativeBase):passclassUsers(Base):__tablename__="users"...(생략)classPlants(Base):__tablename__="plants"...(생략)Users.__table__.create(bind=engine)# <-- 이렇게
fromsqlalchemyimportselectfromsqlalchemy.ormimportsessionmakerSession=sessionmaker(bind=engine)withSession()ass:result=select(Users.name.label("who"),Users.age.label("years_from_birth"))rows=s.execute(result).all()forrowinrows:print(row.who,row.years_from_birth)# 별칭으로 꺼내 씀 (또는 그냥 a, b)
e. Update 데이터수정
조회해온 데이터 인스턴스에 대한 속성값을 수정한 뒤, Session.commit 을 수행한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
fromsqlalchemyimportselectSession=sessionmaker(bind=engine)withSession()ass:# with get
pingoo=s.get(Users,2)pingoo.email="pingping@ex.com"# with select
result=select(Users).where(Users.name=="pengoo")pengoo=s.scalar(result)pengoo.name="pengoo"pengoo.email="king-pengoo@ex.com"# commit
s.commit()
1
2
3
# 수정 후 조회 결과
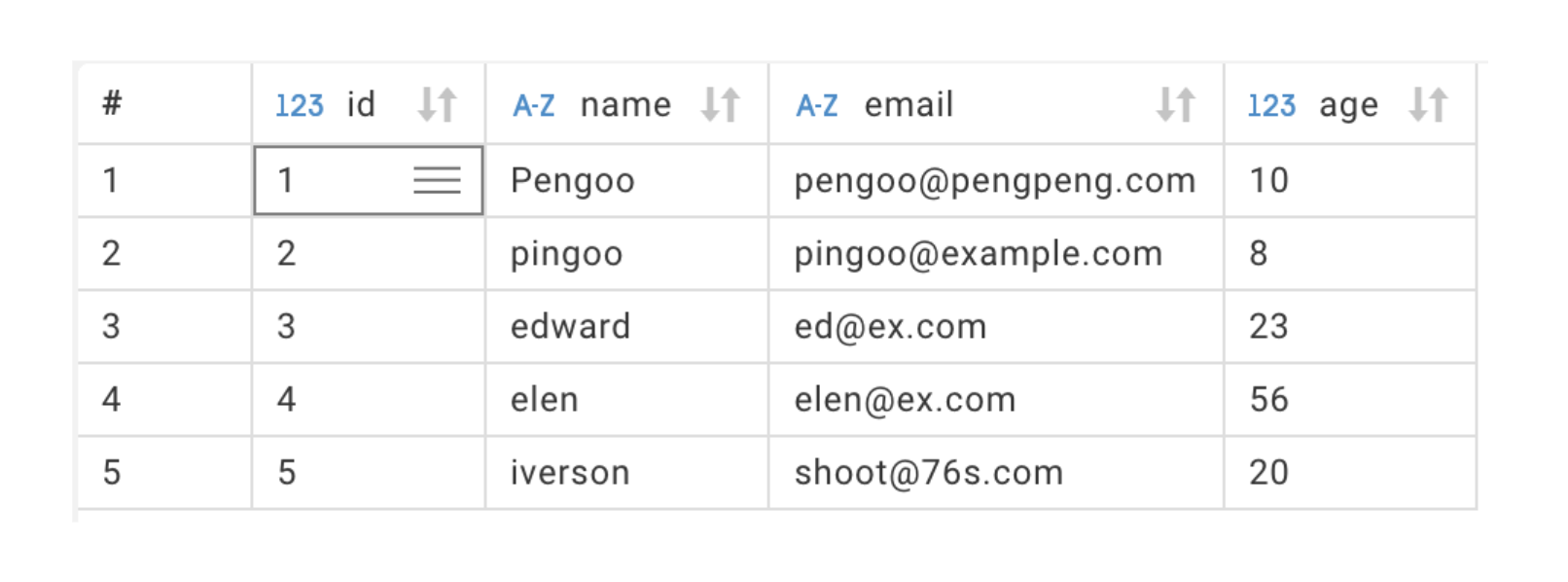
1 pengoo king-pengoo@ex.com 10
2 pingoo pingping@ex.com 8
f. Delete 데이터 삭제
Session.delete() 메서드로 데이터 삭제가 가능하며, 삭제하려는 데이터 인스턴스를 파라미터로 제공해야 한다.
1
2
3
4
5
6
7
8
9
10
fromsqlalchemyimportselectSession=sessionmaker(bind=engine)withSession()ass:# edward 를 삭제
result=select(Users).where(Users.name=="edward")ed=s.scalar(result)s.delete(ed)s.commit()
1
2
3
4
5
# 삭제 후 전체 데이터 조회 결과
1 pengoo king-pengoo@ex.com 10
2 pingoo pingping@ex.com 8
4 elen elen@ex.com 56
5 iverson shoot@76s.com 20
엔진을 생성한 뒤, engine.begin() 으로부터 반환받은 연결 컨텍스트 내에서 처리하면 되며
주의할 점은, 쿼리문을 sqlalchemy.text() 함수로 감싸줘야 한다는 것이다.
1
2
3
4
5
6
7
8
fromsqlalchemyimporttext# <-- text 함수 import
# 테이블명 변경
withtarget_engine.begin()asconn:# f-string으로 만든 문자열을 text()로 감싸줌
conn.execute(text(f"RENAME TABLE {tb1} TO {'drop_'+tb1};"))conn.execute(text(f"RENAME TABLE {tb2} TO {tb1};"))conn.execute(text(f"DROP TABLE {'drop_'+tb1};"))
데이터에 대한 CRUD의 경우, 하나의 컨텍스트 안에서 수행되는 작업은 단일 트랜잭션으로 취급된다.





Comments