
1. MLflow Server의 구조
주요 구성 요소
- MLflow Tracking Server : 실행(Run) 및 실험(Experiment)에 대한 정보를 수신하고, 이를 각 저장소에 알맞게 저장하는 중앙 관제탑. 그리고 사용자가 실행 이력 등을 볼 수 있는 UI.
- Backend Store : 각 실행(Run)과 실험(Experiment)에 대한 정보를 저장하는 RDB
- Artifact Stroe : 학습된 모델 가중치 파일, 데이터, 이미지와 같은 Run의 결과물(Artifact)을 저장하는 저장소
(1) MLflow Server
- 모델 학습과 같은 실행(Run)이나 실험(Experiment) 에 대한 정보를 수신하는 서버
- 수신한 정보를 각 저장소(Backend Store나 Artifact Store)에 저장하는 중앙 관제탑
- 사용자가 실행과 실험 이력, 그리고 저장된 모델에 대한 정보를 볼 수 있는 UI 제공
(2) Backend Store
- 실행에 대한 메타데이터 저장 : 실행(Run)의 ID, 시작 및 종료 시각, 파라미터, 메트릭(평가지표) 등
- 주로 구조화된 데이터들이므로 RDB 형태로 저장된다.
| 지원되는 Backend Store |
구분 | 설명 |
|---|---|---|
| sqlite | RDB | 가볍고 설정이 필요 없는 파일 기반 DB. 주로 개인 개발 및 테스트용으로 사용됨. 기본값. |
| postgresql | RDB | MLflow에서 가장 권장하는 운영용 DB. 확장성이 뛰어나고 대규모 트래킹에 적합함. |
| mysql | RDB | 널리 사용되는 오픈소스 DB. 안정적인 메타데이터 관리가 가능함. |
| mssql | RDB | 기업 환경에서 주로 사용되는 SQL Server 지원. SQLAlchemy를 통해 연결됨. |
| local file system | file | 서버 없이 ./mlruns 폴더 내에 JSON/YAML 형태로 저장하는 방식. |
(3) Artifact Store
- 결과물 저장 : 학습된 모델 가중치 파일, 데이터, 이미지 등
- 각 실행(Run)에 대한 결과물(Artifact)를 저장하며, 이들은 일반적으로 대용량이다.
- 기본적으로 로컬 파일(
mlruns)에 아티팩트를 저장하지만, Amazon S3 및 호환 저장소에도 저장 가능 - MLflow에 Artifact로 기록된 모델에 대해
models:/<model_id>형식의 URI로 모델을 참조할 수 있음 - MLflow Model Registry에 등록된 모델은
models:/<model-name>/<model-version>형식의 URI로 참조 가능
| 지원되는 Artifact Store | 구분 | 설명 |
|---|---|---|
| local file system | file | 로컬 디렉토리에 아티팩트를 저장. 서버와 클라이언트가 동일한 물리적 경로를 공유해야 함. 기본값. |
| Amazon S3 및 호환 저장소 | object | AWS S3 및 RustFS, MinIO 등 S3 API를 사용하는 모든 오브젝트 스토리지 지원. |
| Azure Blob Storage | object | Microsoft Azure의 저장소(WASBS). 대규모 엔터프라이즈 환경에서 선호됨. |
| Google Cloud Storage | object | GCP의 오브젝트 스토리지(GCS).gs:// URI를 통해 접근 가능함. |
| Backblaze B2 | object | 저비용 오브젝트 스토리지 솔루션. S3 호환 API를 통해 연동 가능. |
| SFTP 서버 | network | SSH 파일 전송 프로토콜을 이용한 원격 서버 저장 방식. |
| NFS | network | 네트워크 공유 파일 시스템. 여러 노드에서 공통 경로로 마운트하여 사용. |
구조 설계 방안
세 가지 구조 설계 방안
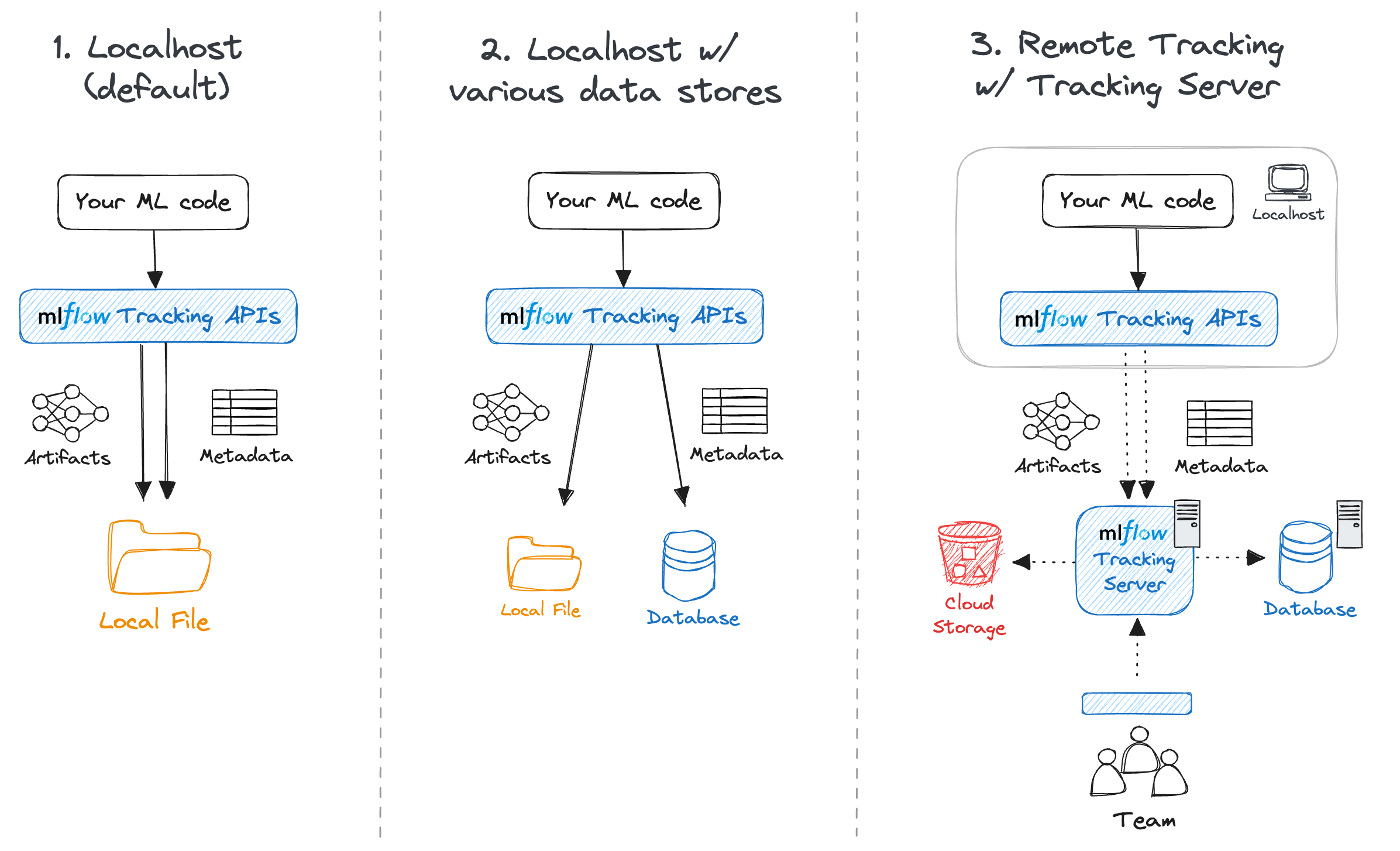
(이미지 출처 : MLflow DOC https://mlflow.org/docs/latest/self-hosting/architecture/overview/)
- (1) Localhost
- (2) Local Tracking with Local Database
- (3) Remote Tracking with MLflow Tracking Server
| 구분 | 1. Localhost (기본값) | 2. Local Tracking with Local DB | 3. Remote Tracking with Server |
|---|---|---|---|
| 권장 상황 | 개인 개발 / 입문 단계 | 개인 개발 (데이터 관리 중심) | 팀 단위 협업 / 운영 환경 |
| 사용 사례 | 별도의 서버, DB 설정 없이 mlruns 폴더에 메타데이터와 아티팩트를 기록. |
SQLite, PostgreSQL 등 DB를 백엔드로 연결하여 실험 데이터를 체계적으로 관리. | 아티팩트 HTTP 프록시를 통해 서버가 모든 기록과 파일 전송을 대행. |
| 핵심 장점 | 설정 없이 즉시 시작 가능 | 서버 없이도 깔끔한 데이터 관리 | 보안성, 공유 가능, 중앙 제어 |
| 스토리지 | 로컬 파일 시스템 | 로컬 DB + 로컬 파일 시스템 | 원격 DB + 오브젝트 스토리지(S3 등) |
(1) Localhost
- 가장 단순한 형태로, 별도의 설정 없이 import mlflow를 사용하는 경우
- Backend Store: 로컬 디렉토리 (./mlruns)
- Artifact Store: 로컬 디렉토리 (./mlruns)
- 혼자서 빠르게 테스트할 때 좋지만, 협업은 어려움
(2) Local Tracking with Local Database
- 트래킹 서버 프로세스를 띄우지는 않고, 메타데이터 관리를 위한 DB만 연결한 형태
- Backend Store: SQLAlchemy 호환 DB (예: SQLite, MySQL)
- Artifact Store: 로컬 디렉토리 (./mlruns)
- 실험 결과(Metric, Parameter)을 RDB 형태로 체계적으로 관리 가능, 결과 조회 쉬움
- 실험 결과물(Artifact)에 대한 공유와 접근이 어려움
(3) Remote Tracking with MLflow Tracking Server
요약
- 실험 결과를 저장하는 RDB 저장소와, 실험 결과물을 저장하고 공유하는 Artifact 저장소가 존재
- 저장 및 조회 등 다양한 API를 담당하는 서버(Tracking Server 존재)
- 머신러닝 서비스와 관련된 다양한 이해관계자 간 협업이 가능한 구조
- 운영환경에 적용 가능한 Production-ready 구조
구성 요소
- Tracking Server: 모든 요청의 중앙 관제탑 (MLflow Server)
- Backend Store: 원격 데이터베이스 (postgres 서비스)
- Artifact Store: 원격 오브젝트 스토리지 (storage/rustfs 서비스)
각 이해관계자 관점에서
- 클라이언트(모델러와 서비스제공자측 모두)는 MLflow 서버 주소만 알면 됨
- 모델러는 코드가 실행되는 위치에 상관 없이 학습시킨 모델을 모델 저장소에 등록이 가능함
- 서비스 제공자는 원격 서버에서 학습된 모델을 이용할 수 있음
- 모델 관리자는 실험의 이력과 등록 모델 현황을 Tracking Server를 통해 모니터링 가능
Outro
- 다음 포스팅들에서는 mlflow tracking server 및 저장소들에 대해 더 자세히 알아볼 것임
- 환경 구성(설치)의 관점에 맞게 Backend Store 부터 Artifact Store, Tracking Server 순으로 진행할 예정
- (설치는 docker compose 방식을 기준으로 함)
Reference
https://mlflow.org/docs/latest/ml/tracking/#tracking-server
https://mlflow.org/docs/latest/ml/docker/
https://github.com/mlflow/mlflow/pkgs/container/mlflow
https://mlflow.org/docs/latest/self-hosting/architecture/backend-store/
https://mlflow.org/docs/latest/self-hosting/architecture/artifact-store/
https://mlflow.org/docs/latest/self-hosting/architecture/artifact-store/#artifacts-store-supported-storages
Comments