애플리케이션이나 시스템의 성능을 실시간으로 모니터링하고, 문제 발생 시 빠르게 대응하는 것은 매우 중요합니다. 이를 위해 많이 사용되는 오픈소스 툴이 바로 Prometheus와 Grafana 입니다. 이번 포스팅 시리즈에서는 이 두 가지 툴의 역할과 설치 및 연동 방식에 대해 소개하겠습니다.
Grafana

Grafana
Grafana Open Source Software (OSS) enables you to query, visualize, alert on, and explore your metrics, logs, and traces wherever they’re stored. Grafana data source plugins enable you to query data sources including time series databases like Prometheus and CloudWatch, logging tools like Loki and Elasticsearch, NoSQL/SQL databases like Postgres, CI/CD tooling like GitHub, and many more. Grafana OSS provides you with tools to display that data on live dashboards with insightful graphs and visualizations.
그라파나는 메트릭이나 로그에 대해 쿼리(질의문)한 결과를 시각화하거나, 알림을 주거나 탐색할 수 있게 해주는 오픈 소스입니다.
메트릭이란?
특정 시스템이나 애플리케이션의 동장 상태나 성능 수치, 예를 들어 CPU 사용율이나 메모리 사용량, HTTP 요청 수, 응답 시간, 에러율 등을 시간의 흐름에 따라 기록한 시계열 데이터를 의미합니다. 이 데이터를 기반으로 모니터링을 하고, 문제를 탐지합니다.
그라파나는 시계열적인 데이터베이스(프로메테우스나 클라우드 워치), 로깅 툴, 엘라스틱 서치, NoSQL/SQL 데이터베이스들, CI/CD 툴 그리고 그 외의 많은 데이터베이스들의 데이터를 데이터 소스로 이용합니다. 이러한 데이터 소스들을 여러 시각화 툴을 이용해 실시간으로 데이터에 대한 인사이트를 얻을 수 있는 대시보드는 그라파나의 핵심 기능입니다.
즉, 그라파나는
- 다양한 데이터 소스를 시각화해 모니터링 대시보드를 만들 수 있는 오픈소스 툴
- 다양한 데이터소스 지원 : 프로메테우스, 클라우드워치, SQL/NoSQL, 엘라스틱서치..
- 알림 기능 또한 제공
- 그래서, DevOps, 시스템 관리자 등이 서버 상태나 애플리케이션 지표를 모니터링 할때 사용
Prometheus

Prometheus
Prometheus is an open-source systems monitoring and alerting toolkit originally built at SoundCloud.
… Prometheus joined the Cloud Native Computing Foundation in 2016 as the second hosted project, after Kubernetes.
… Features
-a multi-dimensional data model with time series data identified by metric name and key/value pairs
-PromQL, a flexible query language to leverage this dimensionality
-no reliance on distributed storage; single server nodes are autonomous
-time series collection happens via a pull model over HTTP
-pushing time series is supported via an intermediary gateway
-targets are discovered via service discovery or static configuration
-multiple modes of graphing and dashboarding support
프로메테우스는 사운드클라우드에서부터 시작된 오픈소스 모니터링 및 알림 툴킷입니다. 그리고 2016년 Cloud Native Computing Foundation(CNCF)의 두 번째 인큐베이팅 프로젝트로 등록되었습니다.
프로메테우스는 시간에 따라 변하는 시계열 데이터를 수집, 저장, 분석, 시각화 하고 알림을 제공하는 오픈소스 모니터링 도구입니다. 시스템 상태나 애플리케이션의 성능을 시계열 형태로 저장하고(메트릭이라고 합니다), 이를 기반으로 성능 저하나 장애 징후를 조기에 파악할 수 있게 해줍니다.
메트릭이란?
특정 시스템이나 애플리케이션의 동장 상태나 성능 수치, 예를 들어 CPU 사용율이나 메모리 사용량, HTTP 요청 수, 응답 시간, 에러율 등을 시간의 흐름에 따라 기록한 시계열 데이터를 의미합니다. 이 데이터를 기반으로 모니터링을 하고, 문제를 탐지합니다.
전통적인 모니터링 시스템들은 관측 대상인 애플리케이션이나 시스템 단에 측정기를 설치하고, 이 측정기가 중앙 모니터링 서버에 데이터를 전송하는 Push 방식이었습니다. 이와는 다르게 프로메테우스는 데이터 수집점인 exporter들에 데이터가 쌓이게 하고, 중앙 모니터링 서버인 프로메테우스 서버가 직접 exporter 들로부터 데이터를 받아오는 Pull 요청이라는 차이점을 가지고 있습니다.
즉 프로메테우스는
- 시계열적 데이터(메트릭)를 수집, 저장하고, 이를 분석, 시각화, 알람에 이용할 수 있게 제공하는 오픈소스 모니터링 툴
- Pull 방식 : 모니터링 대상(타겟)에게 HTTP 요청을 보내 데이터를 수집함
- PromQL : 수집한 시계열적 데이터를 조회하고 분석하는 데 사용되는 쿼리 언어
- 알람 : 사용자가 정의한 조건에 따라 이메일, 슬랙, 웹훅 등의 알람 전송
- 오픈소스 : Apache 2.0 라이선스
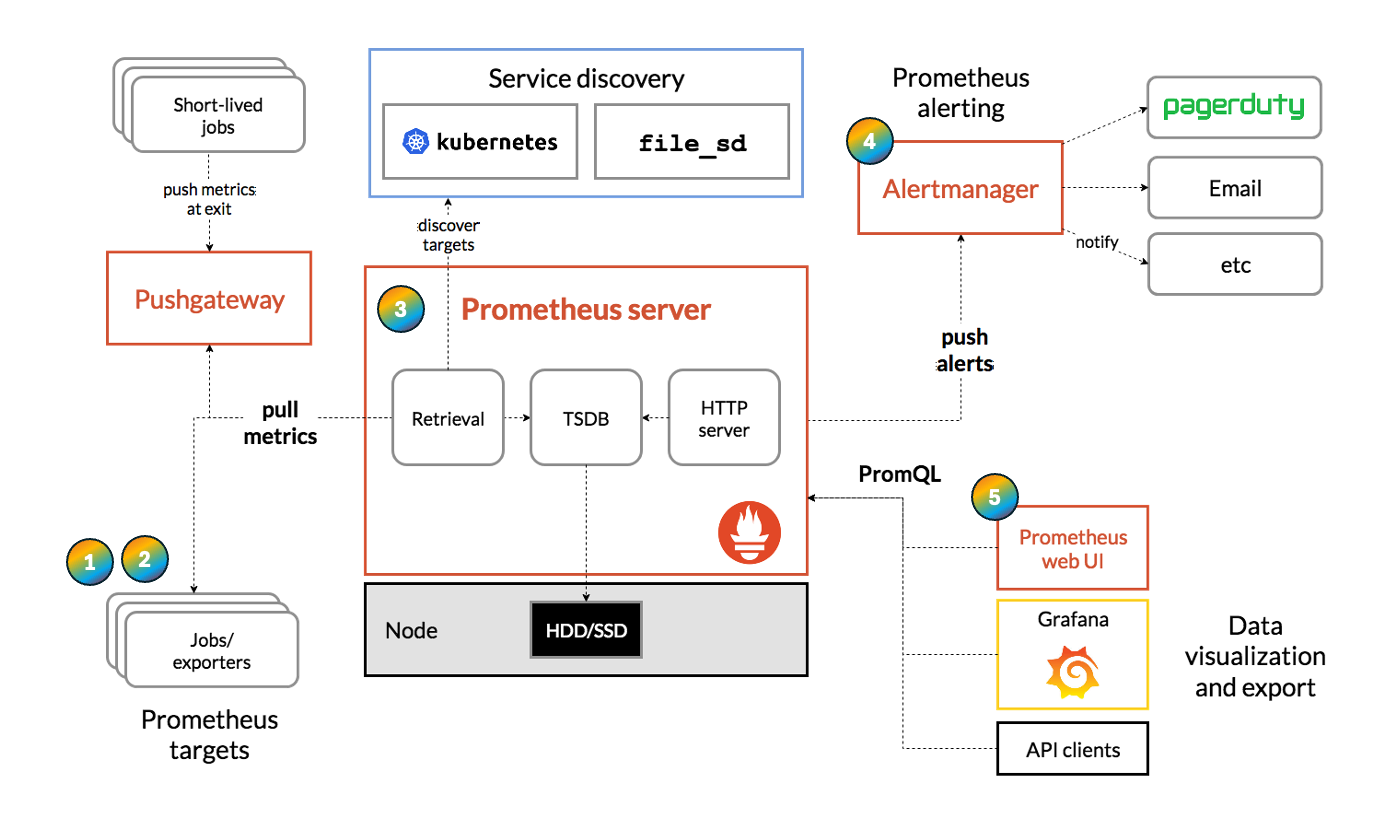
구조
{kind=link}
프로메테우스는 그 구조를 이해하기 전까지는 엄청 헷갈리지만, 그 구조만 이해한다면, 어떻게 이것을 이용해야 할지 바로 알 수 있을 정도로 그 구조가 가장 중요하다고 생각합니다.
(1) target
프로메테우스가 관측하려는 대상입니다. 어떠한 기능을 가진 애플리케이션일 수도 있고, 웹서버일 수도 있고, 시스템이나 하드웨어일 수도 있습니다. 메트릭을 만들어내는 관측 대상이라면, 어떤 것이든 타겟이 될 수 있습니다.
단, 유의해야 할 게 있는데, 타겟이 메트릭을 생산해야한다 라는 점입니다. 프로메테우스는 메트릭을 수집하고, 저장하고, 이를 분석 가능하게 제공할 뿐, 타겟으로부터 없는 데이터를 만들어서 뽑아낼 수는 없습니다.
(2) exporter
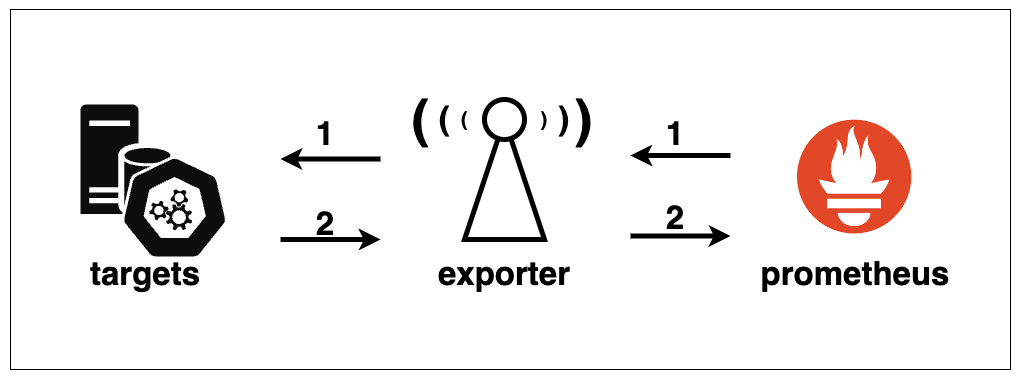
타겟의 메트릭을 생산하거나 수집하는 수집가이자, 프로메테우스 서버가 요청할 때 메트릭을 제공하는 송신처이기도 합니다. 즉, 메트릭 중계지점이라고 할 수 있습니다. 저는 아래 나열할 특징들 때문에, exporter가 프로메테우스 구조 중 가장 흥미로운 구성요소라고 생각합니다.
exporter 의 위치는 애플리케이션이나 시스템이 위치한 곳일 수도 있고, 이와는 별개로 위치할 수도 있습니다.
또한 exporter 는 메트릭을 수집할 때에는 능동적으로 수집하는 수집가이며, 수집한 메트릭을 프로메테우스 서버에 제공할 때에는 수동적으로 응답하는 송신처가 되기도 합니다.
그리고 exporter 는 만들어져있는 것을 사용할 수도 있지만, 사용자가 직접 구축할 수도 있습니다. 때문에 상황이나 데이터의 유형에 따라 굉장히 유연한 데이터 수집기를 만들 수 있습니다.
exporter 는 다양한 데이터를 다뤄야 하는 만큼, exporter 종류 자체도 많습니다. 제가 생각하는 주요 exporter 는 아래와 같습니다.
| Exporter 이름 | 설명 |
|---|---|
| node_exporter | 리눅스 서버의 CPU, 메모리, 디스크, 네트워크 등 시스템 리소스를 수집 |
| cAdvisor | Docker 컨테이너의 리소스 사용량(CPU, 메모리, I/O 등) 을 수집 |
| blackbox_exporter | 외부 서비스에 대한 Ping, HTTP, DNS, TCP 포트 상태 등을 체크 |
| statsd_exporter | StatsD 포맷으로 전송된 메트릭을 Prometheus 형식으로 변환 |
| mysqld_exporter | MySQL 서버의 성능 및 상태 메트릭 수집 (쿼리 속도, 연결 수 등) |
| kube-state-metrics | Kubernetes 클러스터 상태(파드 수, 상태, 리소스 요청량 등) 수집 |
| pushgateway | 일시적인 메트릭(예: 배치 작업 결과)을 푸시해서 Prometheus에 저장 가능하게 함 |
(3) Prometheus Server
exporter 에 수집된 데이터를 가져오고, 데이터를 저장하며, 이를 분석할 수 있게 만들고, 외부의 쿼리 요청에 대해 작업을 처리하는 역할을 합니다. 프로메테우스 서비스의 중심 역할을 하는 중요한 구성요소입니다.
| 구조 | 설명 |
|---|---|
| Retrieval | exporter 에 데이터를 요청하고, 받아오는 역할을 하는 구성요소. |
| TSDB | 수집한 메트릭을 시계열로 저장하는 구성요소. 일정 기간동안은 메모리에 저장하다가, 기간이 지난 데이터는 로컬 디스크에 저장. 저장되는 데이터는 key-value 형태. |
| HTTP server | 요청받은 쿼리(PromQL)을 처리하고 결과를 제공하는 부분. |
(4) Alert Manager
알림을 관리하고 다양한 채널로 전송하는 역할을 합니다. 이메일, 슬랙, 웹훅 등 다양한 전송 수단을 가지고 있습니다.
(5) WebUI
프로모테우스는 WebUI 를 제공하며, 이곳에서 간단한 시각화 도구, 그리고 쿼리를 실행할 수 있습니다.
Pull 방식
프로메테우스는 전통적인 모니터링 툴의 Push 방식이 아닌, Pull 방식을 채택하고 있습니다. 이러한 방식의 특징과 장단점은 아래와 같습니다.
(1) Pull 방식이란?
Prometheus 서버가 주기적으로 모니터링 대상(타겟, Exporter 등)의 메트릭 엔드포인트에 요청을 보내 데이터를 가져오는 방식입니다.
(2) Pull 방식의 장점
| 장점 | 설명 |
|---|---|
| 중앙 제어 | - 어떤 데이터를, 어떤 주기로, 어떤 타겟에서 수집할지 프로메테우스 서버에서 제어 가능. - Pull 실패 여부에 대해 서버에서 바로 파악할 수 있고, 원인 파악 또한 용이한 편 |
| 유연성 | - Kube, EC2 등 동적으로 생성되는 타겟에 대해 유연하게 대처 가능 |
| 가용성 | - 동일 타겟에 대해 중복 데이터 수집을 하여, 누락되는 데이터를 방지할 수 있음. - 이를 통해 UDP 의 데이터 손실이나, 서비스 재기동으로 인한 데이터 유실 방지. - 단, 타노스 등 중복데이터 처리를 해줄 툴이 필요. |
| 확장성 | - 프로메테우스를 또 하나의 exporter 로 삼고, 상위 프로메테우스를 구축하는 게 용이 - 즉, 지역적 모니터링 도구와 이를 전체적으로 모니터링하는 계층적 모니터링 용이 |
(3) Pull 방식의 단점
Prometheus 서버나 exporter 가 타겟에 접근할 수 있어야 하므로, 네트워크 설정이 복잡해질 수 있습니다. 특히 NAT 나 방화벽이 있는 환경에서는 더욱 단점이 부각됩니다.
이를 보완하기 위해 Pushgateway 를 사용하기도 합니다.
(추가) 타노스

타노스는 여러 프로메테우스 서버의 데이터를 수집하고, 이 데이터들의 중복을 제거하며, 하나의 스토리지에 넣고 장기보관이 가능하게 해주는 확장 솔루션입니다.
동일 타겟에 두 개 이상의 프로메테우스를 붙였을 때, 타노스로 수집데이터를 하나로 통합하고, 중복데이터를 제거할 수 있습니다.
또한 프로메테우스의 데이터를 가져와 장기 보관을 할 수도 있고, 이 데이터를 외부의 스토리지에 저장하는 기능 또한 제공합니다.
다음 포스팅
다음 포스팅에서는 메트릭 수집과 보관을 위해 프로메테우스를 설치해보고, 실제 데이터를 수집해보도록 하겠습니다.