
스키마와 데이터 필드
스키마
- 컬렉션의 데이터 구조를 정의하는 설계도.
- 컬렉션을 만들기 전에 반드시 설계해야 함.
- 관계형 DB의 테이블 스키마와 유사한 개념.
- 스키마를 잘 설정하면 저장 효율, 검색 효율로 이어지기 때문에 굉장히 중요함.
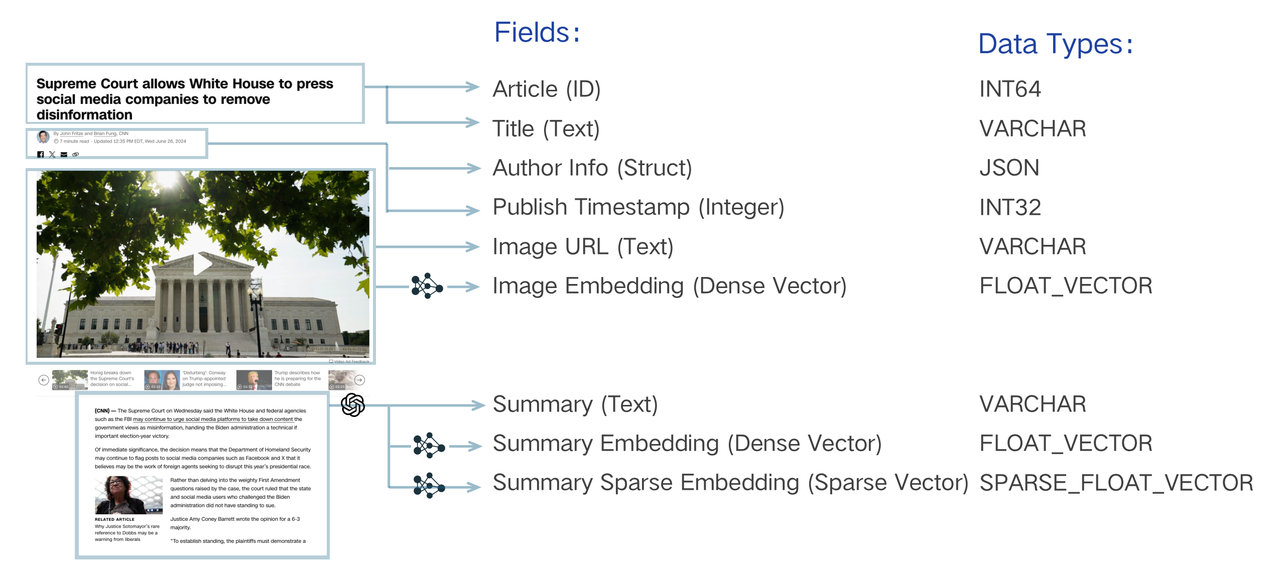
스키마 설계 예시 - https://milvus.io/docs/v2.5.x/assets/schema-design-anatomy.png
{kind=link}
데이터 필드
데이터 필드 설명
- 컬렉션 안에 저장될 데이터의 속성을 정의하는 요소
- RDB 에서 컬럼에 해당됨.
- 기본(Primary) 필드, 벡터 필드, 스칼라 필드로 구분됨
데이터 필드의 종류
| 구분 | 필드 | 설명 |
|---|---|---|
| 기본 필드 | Primary Field | - 엔티티를 고유하게 식별하기 위한 목적의 필드 - Int64 또는 VarChar 값만 허용 - is_primary 속성값 옵션에 설정 |
| 벡터 필드 | FLOAT_VECTOR | - 32비트 부동 소수점 데이터 - 과학 계신 및 머신러닝에서 일반적으로 사용 - 유사 벡터 조회 등 높은 정밀도가 필요한 경우 사용 |
| 벡터 필드 | FLOAT16_VECTOR | - 16비트 반정밀도 부동 소수점 데이터 - 일반적으로 메모리 또는 대역폭이 제한된 상황에서 - 딥 러닝 또는 GPU 기반 컴퓨팅 시나리오에 적용 |
| 벡터 필드 | BFLOAT16_VECTOR | - 한 16비트 부동 소수점 숫자 데이터 - 정밀도는 떨어지지만 지수 범위는 Float32와 동일 - 정확도에 큰 영향을 주지 않으면서 - 메모리 사용량을 줄이기 때문에 - 딥러닝 시나리오에서 일반적으로 사용 |
| 벡터 필드 | BINARY_VECTOR | - 0과 1로 이루어진 데이터 - 이미지 처리 및 정보 검색 시나리오에서 - 데이터를 표현하기 위한 간결한 기능으로 사용 |
| 벡터 필드 | SPARSE_FLOAT_VECTOR | - 0이 아닌 숫자의 목록과 그 시퀀스 번호를 저장 - 희소 벡터 임베딩 |
| 스칼라 필드 | 문자열 필드 (VarChar) | - 문자열 값 저장용 - 주로 태그, 이름, 설명 등의 메타데이터 저장에 사용 |
| 스칼라 필드 | 숫자 필드 (Int, Float) | - 정수 또는 실수 값 저장용 - 예: 나이, 점수, 가격 등 숫자 기반 메타데이터 저장 |
| 스칼라 필드 | 부울 필드 (Bool) | - 참/거짓 값 저장용 - 예: 활성/비활성, true/false 상태 플래그 저장 |
| 스칼라 필드 | JSON 필드 (JSON) | - 복잡한 구조화 데이터를 JSON 형태로 저장 - 유연한 메타데이터나 중첩 구조 저장 시 유용 |
| 스칼라 필드 | 배열 필드 (Array) | - 동일한 타입 값들의 배열 형태로 저장 - 예: 다중 태그, 여러 숫자 값 등 |
데이터 필드의 속성값
| 속성 이름 | 적용 대상 | 설명 |
|---|---|---|
| name | 모든 필드 | - 필드 이름 (필수). |
| description | 모든 필드 | - 필드 설명 (선택). |
| datatype | 모든 필드 | - 데이터 타입 (예: Int64, Float, FloatVector 등) (필수). |
| is_primary | Primary Key 필드 | - 해당 필드를 컬렉션의 primary key로 지정 (bool). |
| auto_id | Primary Key 필드 | - Int64 primary key일 때만 사용 - ID를 자동 생성할지 여부 (bool). |
| dim | Vector 필드 | - 벡터 필드 차원 (예: 128, 512). 벡터 필드에서 필수. |
| metric | Vector 필드 | - 벡터 간 유사성 측정 기준 |
| is_partition_key | Partition Key 필드 | - 파티셔닝용 필드로 사용할지 여부 (bool). |
| nullable | 스칼라 필드 | - 해당 필드가 null 값을 허용할지 여부 |
| default | 스칼라 필드 | - 값이 없을 경우 기본값으로 넣을 값 |
| max_length | VARCHAR 필드 | - 저장 가능한 문자열의 최대 길이 |
| max_capacity | 배열 필드 | - 배열 내 최대 원소 개수 |
스키마
스키마 만들기
create_schema()메서드를 이용해서 스키마 생성 가능.
1
2
3
from pymilvus import MilvusClient, DataType
schema = MilvusClient.create_schema()
- Dynamic Field(동적 필드) 를 허용하려면
enable_dynamic_field옵션을 True 로 설정
1
2
# 스키마 생성 (enable_dynamic_field=True 지정)
schema = MilvusClient.create_schema(enable_dynamic_field=True)
데이터 필드
기본 필드 추가
is_primary필드를 True 로.datatype은DataType.INT64혹은DataType.VARCHAR만 가능.auto_id는 자동으로 id 를 부여할지, 수동으로 지정할지에 대한 옵션.
INT64 형 기본(Primary) 필드
datatype은DataType.INT64
1
2
3
4
5
6
schema.add_field(
field_name="my_id",
datatype=DataType.INT64,
is_primary=True,
auto_id=False,
)
VARCHAR 형 기본(Primary) 필드
- 기본 키가 중복되면 안되는 점을 주의!
- 해싱을 이용하거나
my_entity_1234와 유사한 형태로 지정하는 것을 권장. max_length: 기본 필드로 사용할 필드의 최대 문자열 길이.
1
2
3
4
5
6
7
schema.add_field(
field_name="my_id",
datatype=DataType.VARCHAR,
is_primary=True,
auto_id=True,
max_length=512,
)
벡터 필드 추가
벡터 필드 추가
datatype에 벡터 타입의 데이터타입을 지정.dim에 벡터의 차원 수를 지정.- 컬렉션, 스키마에는 최소 하나의 벡터 필드가 존재해야 한다.
metric에 벡터 유사도 계산 기준 방식을 지정한다.
1
2
3
4
5
schema.add_field(
field_name="my_vector",
datatype=DataType.FLOAT_VECTOR,
dim=5
)
| 파라미터 | 설명 | 예시 |
|---|---|---|
| field_name | 필드명 | |
| datatype | 데이터타입 | |
| dim | 차원 수. 768차원 임베딩의 경우 dim=768 | dim=768 |
| metric | 벡터간 유사도 계산 방식 | metric=”COSINE” |
벡터 필드 data type
| 구분 | 필드 | 설명 |
|---|---|---|
| 벡터 필드 | FLOAT_VECTOR | - 32비트 부동 소수점 데이터 - 과학 계신 및 머신러닝에서 일반적으로 사용 - 유사 벡터 조회 등 높은 정밀도가 필요한 경우 사용 |
| 벡터 필드 | FLOAT16_VECTOR | - 16비트 반정밀도 부동 소수점 데이터 - 일반적으로 메모리 또는 대역폭이 제한된 상황에서 - 딥 러닝 또는 GPU 기반 컴퓨팅 시나리오에 적용 |
| 벡터 필드 | BFLOAT16_VECTOR | - 한 16비트 부동 소수점 숫자 데이터 - 정밀도는 떨어지지만 지수 범위는 Float32와 동일 - 정확도에 큰 영향을 주지 않으면서 - 메모리 사용량을 줄이기 때문에 - 딥러닝 시나리오에서 일반적으로 사용 |
| 벡터 필드 | BINARY_VECTOR | - 0과 1로 이루어진 데이터 - 이미지 처리 및 정보 검색 시나리오에서 - 데이터를 표현하기 위한 간결한 기능으로 사용 |
| 벡터 필드 | SPARSE_FLOAT_VECTOR | - 0이 아닌 숫자의 목록과 그 시퀀스 번호를 저장 - 희소 벡터 임베딩 |
metric 옵션
| 필드 타입 | 차원 범위 | 지원되는 메트릭 타입 | 기본 메트릭 타입 |
|---|---|---|---|
FLOAT_VECTOR |
2-32,768 | COSINE, L2, IP |
COSINE |
FLOAT16_VECTOR |
2-32,768 | COSINE, L2, IP |
COSINE |
BFLOAT16_VECTOR |
2-32,768 | COSINE, L2, IP |
COSINE |
SPARSE_FLOAT_VECTOR |
차원 지정 불필요 | IP, BM25 (전체 텍스트 검색용만) |
IP |
BINARY_VECTOR |
8-32,768*8 | HAMMING, JACCARD |
HAMMING |
메트릭별 유사성 거리 특성
| 메트릭 타입 | 유사성 거리 값 특성 | 유사성 거리 값 범위 |
|---|---|---|
L2 |
작은 값일수록 유사성이 높음 | [0, ∞) |
IP |
큰 값일수록 유사성이 높음 | [-1, 1] |
COSINE |
큰 값일수록 유사성이 높음 | [-1, 1] |
JACCARD |
작은 값일수록 유사성이 높음 | [0, 1] |
HAMMING |
작은 값일수록 유사성이 높음 | [0, dim(vector)] |
BM25 |
TF(용어 빈도), IDF(역문서 빈도), 문서 정규화 기반 | [0, ∞) |
스칼라 필드 추가
문자열(VARCHAR) 필드 추가
datatype은DataType.VARCHARmax_length: 최대 문자열 길이를 지정할 수 있음.max_length의 최소값은 1, 최대값은 65535.nullable(옵션): null 을 허용할지 여부. 기본값은 Falsedefault(옵션): 데이터가 null 인 경우 기본적으로 넣을 값.
1
2
3
4
5
6
7
schema.add_field(
field_name="my_varchar",
datatype=DataType.VARCHAR,
max_length=512,
nullable=True, # 옵션
default="Unknown" # 옵션
)
- VARCHAR 형 필드의
max_length필드는 컬렉션 생성 후에도 수정 가능. - 수정시에는
alter_collection_field메서드를 사용.
1
2
3
4
5
6
7
client.alter_collection_field(
collection_name="my_collection",
field_name="my_varchar",
field_params={
"max_length": 1024
}
)
숫자 필드 추가
datatype은 아래 데이터타입들 지정 가능.nullable(옵션): null 을 허용할지 여부. 기본값은 Falsedefault(옵션): 데이터가 null 인 경우 기본적으로 넣을 값.
| 데이터타입 | 설명 |
|---|---|
| DataType.BOOL | - true 또는 false 을 저장하기 위한 부울 유형- 이진 상태를 설명하는 데 적합 |
| DataType.INT8 | - 8비트 정수형 128 ~ 127 범위. - 메모리 절약용 소형 정수 데이터에 사용. |
| DataType.INT16 | - 16비트 정수형, -32,768 ~ 32,767 범위. - 중간 크기의 정수 데이터 저장용. |
| DataType.INT32 | - 32비트 정수형, -2,147,483,648 ~ 2,147,483,647 범위. - 제품 수량이나 사용자 ID와 같은 일반적인 정수 값. |
| DataType.INT64 | - 64비트 정수형, 매우 큰 정수 값 저장 가능. - 주로 primary key나 타임스탬프로 사용. |
| DataType.FLOAT | - 32비트 부동소수점 숫자 - 소수점 값 포함 실수 데이터 저장용. - 등급이나 온도 등 일반적 정밀도가 필요한 데이터에 적합. |
| DataType.DOUBLE | - 64비트 부동소수점 숫자 - 더 높은 정밀도의 실수 값 저장용. - 재무, 과학 계산 같은 고정밀 데이터에 적합. |
1
2
3
4
5
6
schema.add_field(
field_name="my_int64",
datatype=DataType.INT64,
nullable=True, # 옵션
default=18 # 옵션
)
부울 필드 추가
datatype은DataType.BOOL을 선택nullable(옵션): null 을 허용할지 여부. 기본값은 Falsedefault(옵션): 데이터가 null 인 경우 기본적으로 넣을 값.
1
2
3
4
5
6
schema.add_field(
field_name="my_bool",
datatype=DataType.BOOL,
nullable=True, # 옵션
default=True # 옵션
)
JSON 필드 추가
datatype은DataType.JSON을 선택- JSON 필드 크기는
65,536바이트로 제한됨. - JSON 내부 키 이름은
문자, 숫자, 언더바만 사용하는 걸 권장. nullable(옵션): null 을 허용할지 여부. 기본값은 False- JSON 타입은
default(기본값)필드가 지원되지 않음.
1
2
3
4
5
schema.add_field(
field_name="my_json",
datatype=DataType.JSON,
nullable=True # 옵션
)
배열 필드 추가
datatype은DataType.ARRAY를 선택element_type: 배열의 원소로 들어갈 값의 데이터타입을 지정.- 하나의 배열에는 동일한 데이터타입만 들어갈 수 있음.
max_capacity: 배열 필드의 원소 수.max_length: 배열 필드의 원소 데이터타입이 VARCHAR 일 경우 최대 길이.nullable(옵션): null 을 허용할지 여부. 기본값은 False- 배열 타입은
default(기본값)필드가 지원되지 않음.
1
2
3
4
5
6
7
8
schema.add_field(
field_name="my_array",
datatype=DataType.ARRAY,
element_type=DataType.VARCHAR,
max_capacity=5,
max_length=512,
nullable=False
)
- 배열 필드의
max_capacity속성은 컬렉션 생성 후에도 변경 가능. alter_collection_field메서드로 변경 가능.
1
2
3
4
5
6
7
client.alter_collection_field(
collection_name="my_collection",
field_name="my_array",
field_params={
"max_capacity": 64
}
)
동적 필드(Dynamic Field)
동적 필드(Dynamic Field)
- 스키마에 미리 정의되지 않으며, 데이터 적재시에 선택적으로 사용하는 필드.
- 즉, 동일 컬렉션 내 각 엔티티마다 이 동적 필드는 있을 수도 있고, 없을 수도 있다.
- 엘라스틱서치의 필드 또한 각 필드들이 있을 수도 있고, 없을 수도 있는 것과 동일.
- 동적 필드는
$meta라는 이름으로 예약되어 있음.
동적 필드 활성화
- 컬렉션 생성 시에
enable_dynamic_field옵션으로 설정 - True 면 동적 필드 기능을 활성화한 것.
1
2
3
4
5
client.create_collection(
collection_name="my_collection",
dimension=5,
enable_dynamic_field=True
)
- 현재(2025-05-30) 컬렉션 생성시 동적 필드 활성화 옵션이 적용되지 않는 이슈 있음.
- 그 경우
schema생성시에 동적 필드 활성화 옵션을 넣어주면 됨.
1
2
# 스키마 생성 (enable_dynamic_field=True 지정)
schema = MilvusClient.create_schema(enable_dynamic_field=True)
동적 필드의 장단점
동적 필드의 장점
- 유연성 : 스키마에 정의되지 않은 데이터를 추가로 저장 가능.
- 확장성 : 새 필드를 사전 설계 없이 삽입할 수 있어 빠른 실험·프로토타이핑에 유리.
- 필드 선택성 : 일부 데이터만 선택적으로 넣을 수 있어 필수/선택 데이터를 구분 가능.
- 필터링 : 동적 필드의 키도 스칼라 쿼리(조건 검색)에 사용할 수 있음.
동적 필드의 단점
- 관리 복잡성 증가 : 명시적 스키마 없이 데이터가 유입되면 관리·유지보수가 어려움.
- 성능 저하 위험 : JSON 필드로 저장됨. 검색·필터링 성능 저하 가능성.
- 데이터 무결성 부족 : 스키마에 기반하지 않아 잘못된 데이터 구조가 들어올 가능성.
Nullable 과 Default
Nullable
Nullable
- 해당 필드에 null 값 store 허용 여부를 지정하는 옵션
nullable=True지정 시 해당 필드에 null 값 저장을 허용함
제한 사항
- 스칼라 필드만 nullable 이 가능하며, 기본 필드 및 벡터 필드는 불가.
- 컬렉션 생성 당시에 지정할 수 있으며, 생성 이후에는 옵션 수정 불가.
- nullable 필드는 그룹화 검색에서
group_by_field검색으로 사용할 수 없음. - nullable 필드는 파티션 키로 사용할 수 없음.
- 인덱스 생성시 null 값은 인덱스 생성에서 제외됨.
Nullable 설정 방법
1
2
3
4
5
6
7
8
9
10
11
12
13
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri='http://localhost:19530')
# Define collection schema
schema = client.create_schema(
auto_id=False,
enable_dynamic_schema=True,
)
...
schema.add_field(field_name="age", datatype=DataType.INT64, nullable=True)
데이터 삽입 시
- nullable 필드에 null 값을 삽입하거나
- 해당 필드에 대한 key-value 를 생략함으로써 null 값 삽입 가능
1
2
3
4
5
data = [
{"id": 1, "vector": [0.1, 0.2, 0.3, 0.4, 0.5], "age": 30},
{"id": 2, "vector": [0.2, 0.3, 0.4, 0.5, 0.6], "age": None},
{"id": 3, "vector": [0.3, 0.4, 0.5, 0.6, 0.7]}
]
검색 및 쿼리 시
- 검색(
search) 메서드의 결과에서 null 인 부분은 null 로 반환됨. query메서드 사용시 null 값에 대한 필더링 결과는 모두 False 로 반영됨.
Default
Default
- 기본값. 데이터가 null일 경우, 대신 store 되는 기본 값을 지정하는 옵션.
- 컬렉션 생성시
default_value파라미터에 기본값 정의.
제한 사항
- JSON 필드와 배열 필드는 Default 를 지원하지 않음.
Default 설정 방법
1
2
3
4
5
6
7
schema = client.create_schema(
auto_id=False,
enable_dynamic_schema=True,
)
schema.add_field(field_name="status", datatype=DataType.VARCHAR, default_value="active", max_length=10)
...
데이터 삽입시
- 데이터 삽입 시 필드를 생략하거나 인풋 값을 null 로 설정하면 기본값을 store 함.
1
2
3
4
5
6
data = [
{"id": 1, "vector": [0.1, 0.2, ..., 0.128], "age": 30, "status": "premium"},
{"id": 2, "vector": [0.2, 0.3, ..., 0.129]},
{"id": 3, "vector": [0.3, 0.4, ..., 0.130], "age": 25, "status": None},
{"id": 4, "vector": [0.4, 0.5, ..., 0.131], "age": None, "status": "inactive"}
]
검색 및 쿼리시
- 기본값이 포함된 엔티티는, 실제 데이터가 삽입된 엔티티와 동일하게 취급됨.
- 따라서 검색 및 쿼리에서도 데이터가 삽입된 엔티티와 동일하게 결과를 반환.
Mmap
Mmap
- mmap : 컬렉션을 로드하는 방식 중 하나. 메모리 매핑 방식.
| 컬렉션 로드 방식 | 설명 |
|---|---|
| cache 모드 | - 데이터를 메모리에 복사해서 올림 - 속도 빠름, 메모리 많이 필요 |
| mmap 모드 | - 디스크 파일을 OS의 메모리 매핑 기능으로 연결 - 실제로 접근할 때만 메모리에 읽어옴 - 메모리 절약 - I/O 속도는 장비와 OS에 의존 |
필드에 Mmap 적용하기
- 필드별로 mmap을 적용할 수 있다.
alter_collection_field메서드를 사용하며,properties파라미터에mmap.enable값을 조정함으로써 Mmap 설정 여부를 지정할 수 있다.
1
2
3
4
5
client.alter_collection_field(
collection="my_collection",
field_name="doc_chunk",
properties={"mmap.enabled": True}
)
Reference
https://milvus.io/docs/ko/schema.md
https://milvus.io/docs/ko/primary-field.md
https://milvus.io/docs/ko/string.md
https://milvus.io/docs/ko/number.md
https://milvus.io/docs/ko/use-json-fields.md
https://milvus.io/docs/ko/array_data_type.md
https://milvus.io/docs/ko/enable-dynamic-field.md
https://milvus.io/docs/ko/nullable-and-default.md
https://milvus.io/docs/ko/alter-collection-field.md
Comments