importpymilvusmilvus_host='milvus 실행중인 서버 IP'milvus_port='19530'database_name='my_database_1'milvus_username='root'# milvus 기본 계정
milvus_password='Milvus'# milvus 기본 비밀번호
# 데이터베이스 만들기
frompymilvusimportMilvusClient# milvus client 인스턴스 생성
client=MilvusClient(uri=f"http://{milvus_host}:{milvus_port}",token=f"{milvus_username}:{milvus_password}")# database 생성
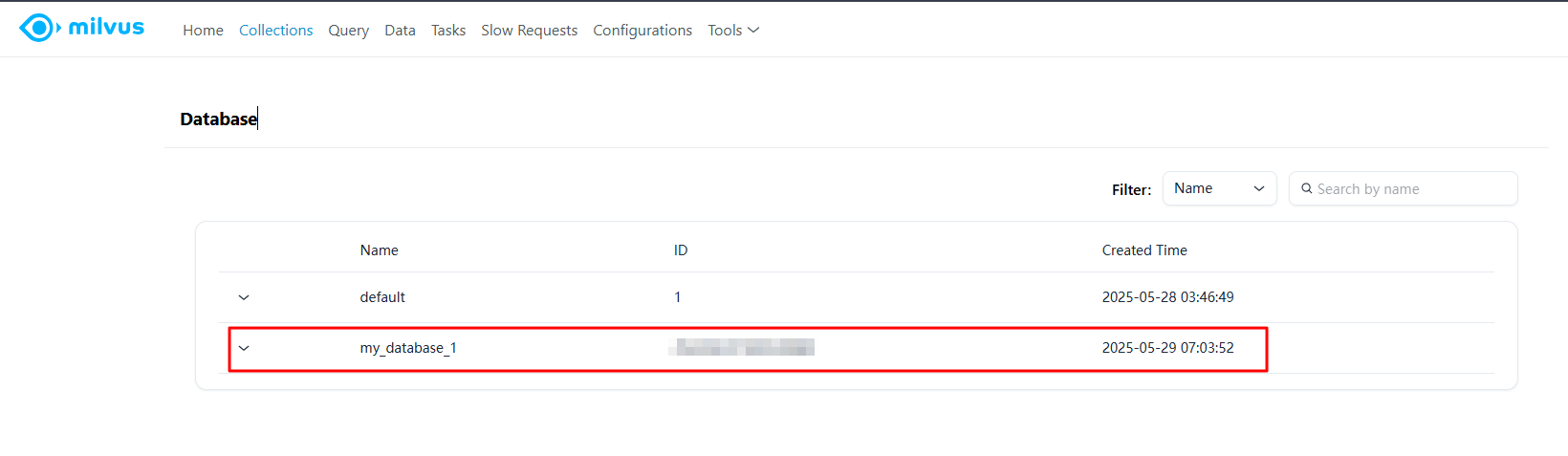
client.create_database(db_name="my_database_1")
# 스키마 생성
frompymilvusimportMilvusClient,DataTypeimportdotenvmilvus_host=os.getenv('MILVUS_HOST')milvus_port=os.getenv('MILVUS_PORT')database_name='my_database_1'milvus_username='root'# milvus 기본 계정
milvus_password='Milvus'# milvus 기본 비밀번호
# milvus client 인스턴스 생성
client=MilvusClient(uri=f"http://{milvus_host}:{milvus_port}",token=f"{milvus_username}:{milvus_password}")# Create schema
schema=MilvusClient.create_schema(auto_id=False,enable_dynamic_field=True,)# Add fields to schema
schema.add_field(field_name="my_id",datatype=DataType.INT64,is_primary=True)schema.add_field(field_name="my_vector",datatype=DataType.FLOAT_VECTOR,dim=5)schema.add_field(field_name="my_varchar",datatype=DataType.VARCHAR,max_length=512)
# Create a collection with the index loaded simultaneously
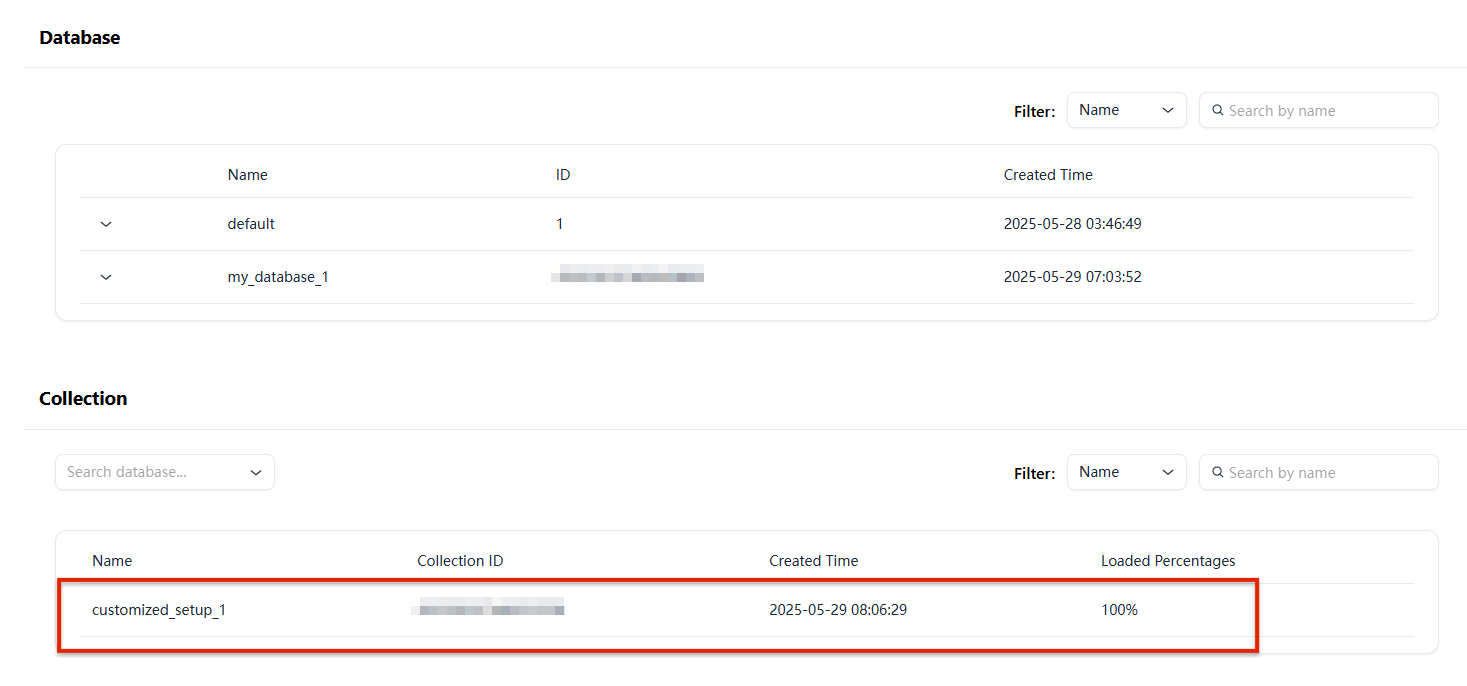
client.create_collection(collection_name="customized_setup_1",schema=schema,index_params=index_params)res=client.get_load_state(collection_name="customized_setup_1")
response 를 출력해보면 아래와 같음.
1
2
3
4
print(res)# Output
{'state':<LoadState:Loaded>}
Milvus WebUI 에서 확인해보면
컬렉션 전환
다른 컬렉션으로 전환할 때에는 get_load_state 메서드를 사용
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 3.6. Create a collection and index it separately
client.create_collection(collection_name="customized_setup_2",schema=schema,)res=client.get_load_state(collection_name="customized_setup_2")print(res)# Output
#
# {
# "state": "<LoadState: NotLoad>"
# }
컬렉션 속성 설정
샤드 번호 설정
컬렉션을 만들 때 분산 처리를 위한 샤드 설정을 할 수 있음.
샤드는 해당 컬렉션에 인입되는 데이터를 얼마나 분산해서 저장할지에 대한 설정임.
복제(replica) 와는 다른 개념임.
▶ 샤드를 늘리는 기준
아래는 일반적으로 권장되는 (공식DOC) 샤드 증설 기준이다.
(1) 예상 처리량이 500MB/s 증가하거나
(2) 삽입할 데이터의 양이 100GB 증가할 때마다
1
2
3
4
5
6
# With shard number
client.create_collection(collection_name="customized_setup_3",schema=schema,num_shards=1)
mmap 활성화
mmap : 컬렉션을 로드하는 방식 중 하나. 메모리 매핑 방식.
컬렉션 로드 방식
설명
cache 모드
- 데이터를 메모리에 복사해서 올림 - 속도 빠름, 메모리 많이 필요
mmap 모드
- 디스크 파일을 OS의 메모리 매핑 기능으로 연결 - 실제로 접근할 때만 메모리에 읽어옴 - 메모리 절약 - I/O 속도는 장비와 OS에 의존
이를 컬렉션에 적용할 때에는 enable_mmap 속성을 True 로 설정하면 됨.
1
2
3
4
5
6
# With mmap
client.create_collection(collection_name="customized_setup_4",schema=schema,enable_mmap=False)
컬렉션 TTL(Time-To-Live) 설정
TTL : Time-To-Live. 데이터의 수명을 설정하는 옵션.
collection.ttl.seconds 속성값을 지정함으로써 설정할 수 있음.
속성값 단위는 초(sec)
1
2
3
4
5
6
7
8
# With TTL
client.create_collection(collection_name="customized_setup_5",schema=schema,properties={"collection.ttl.seconds":86400})
일관성 수준 설정
컬렉션 검색 및 쿼리에 대한 일관성 수준 설정
일관성이란, 데이터의 읽기에 대한 최신성을 뜻함
데이터 삽입과 삭제 등의 작업이 모든 노드에서 동시에 100% 동기화가 안될 수도 있음.
따라서, 검색과 쿼리시에 최신 데이터까지 포함해서 볼지, 약간 늦더라도 성능을 우선할지 등을 설정하는 게 일관성 수준 설정임.
일관성 수준
설명
Strong
강한 일관성. 최신 데이터까지 반드시 반영. 성능 비용이 높음.
Session
현재 세션 내에서는 강한 일관성, 다른 세션과는 Eventually 수준.
Bounded
삽입 후 지정된 시간(Ts)까지 동기화된 데이터만 보장.
Eventually
최종 일관성. 최신 데이터는 보장하지 않지만 성능은 매우 빠름.
실시간 검색 서비스에서는 Strong이 필요할 수 있지만,
대규모 배치 검색이나 추천 시스템에서는 Eventually로 성능을 높이곤 함.
1
2
3
4
5
6
# With consistency level
client.create_collection(collection_name="customized_setup_6",schema=schema,consistency_level="Bounded",)
컬렉션 조회
컬렉션 목록 조회
client.list_collections() 메서드로 컬렉션 목록을 조회할 수 있음.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 컬렉션 목록 조회
frompymilvusimportMilvusClient,DataTypeimportdotenvmilvus_host=os.getenv('MILVUS_HOST')milvus_port=os.getenv('MILVUS_PORT')database_name='my_database_1'milvus_username='root'# milvus 기본 계정
milvus_password='Milvus'# milvus 기본 비밀번호
# milvus client 인스턴스 생성
client=MilvusClient(uri=f"http://{milvus_host}:{milvus_port}",token=f"{milvus_username}:{milvus_password}")res=client.list_collections()print(res)
1
2
# Output
['customized_setup_1']
컬렉션 정보 조회
client.describe_collection() 메서드로 컬렉션의 정보(메타데이터) 를 조회할 수 있음.
frompymilvusimportMilvusClient,DataTypeimportdotenvmilvus_host=os.getenv('MILVUS_HOST')milvus_port=os.getenv('MILVUS_PORT')database_name='my_database_1'milvus_username='root'# milvus 기본 계정
milvus_password='Milvus'# milvus 기본 비밀번호
# Load the collection
client.load_collection(collection_name="customized_setup_1")# Check Load State
res=client.get_load_state(collection_name="customized_setup_1")print(res)
1
2
# Output
{'state':<LoadState:Loaded>}
특징 필드 로드
특정 필드만 로드할 수 있음
이에 따라 메모리 사용량을 줄이고 검색 성능 개선 가능.
load_collection 의 load_fields 속성값을 통해 지정 가능.
1
2
3
4
5
6
7
8
9
10
11
client.load_collection(collection_name="customized_setup_1",load_fields=["my_id","my_vector"],# Load only the specified fields
skip_load_dynamic_field=True# Skip loading the dynamic field
)res=client.get_load_state(collection_name="customized_setup_1")print(res)
만약 필드 로드 에러가 난다면, 해당 컬렉션을 release한 뒤, 다시 load 해보길 권장함.

Comments