
Milvus 의 아키텍처
설계 개요
- milvus 는 수많은 벡터가 포함된 고밀도 데이터 세트에 대한 유사도 검색을 고려해 설계됨
- Faiss, HNSW, DiskANN, SCANN 등 널리 사용되는 벡터 검색 라이브러리를 기반으로 구축
- 컴퓨팅 노드에 스토리지 및 컴퓨팅 분리와 수평적 확장성을 갖춘 공유 스토리지 아키텍처
- 제어 플레인 분리 원칙에 따라 액세스 레이어, 코디네이터 서비스, 워커 노드, 스토리지 네 가지 레이어로 구성됨
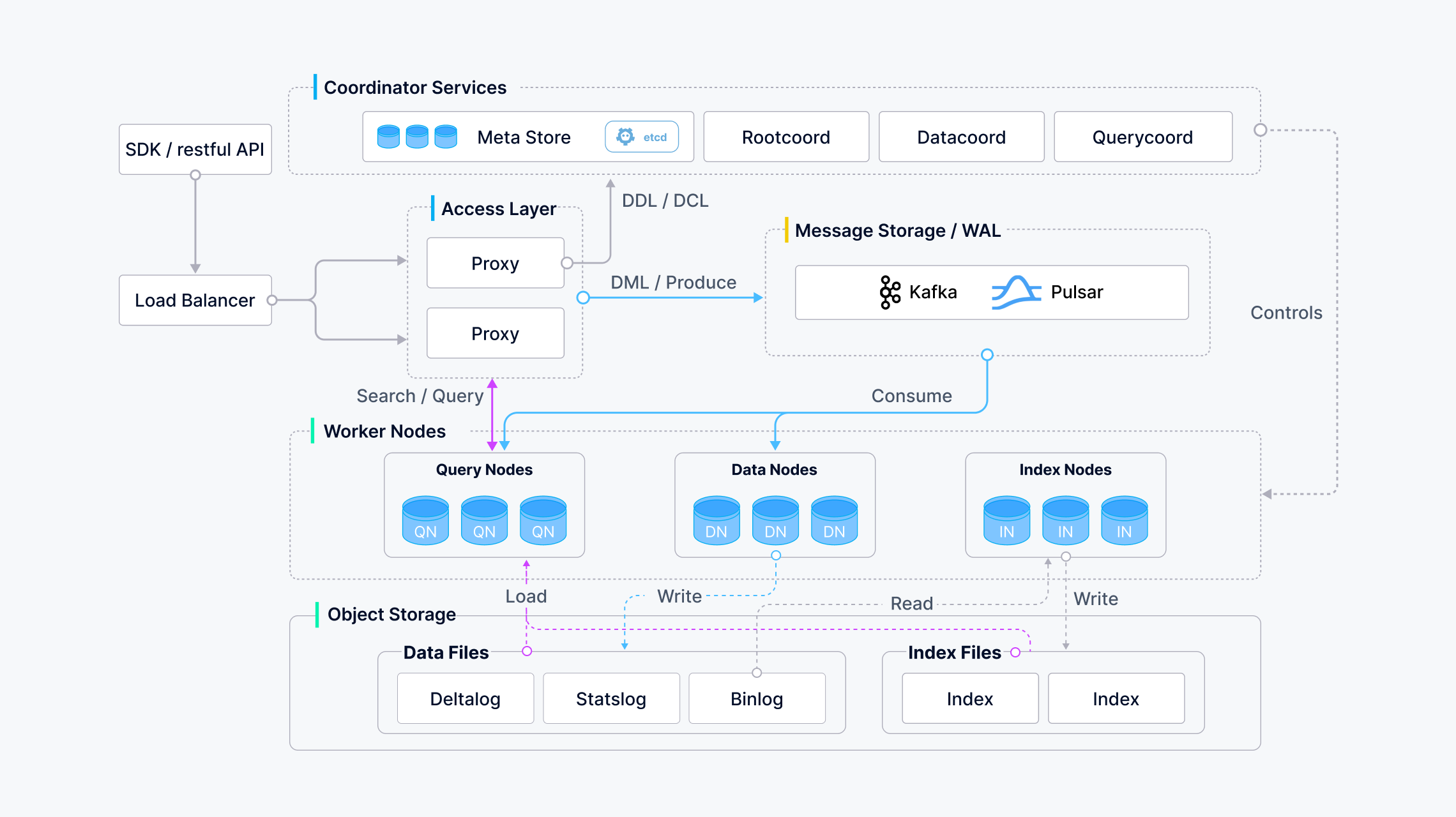
아키텍처 도식
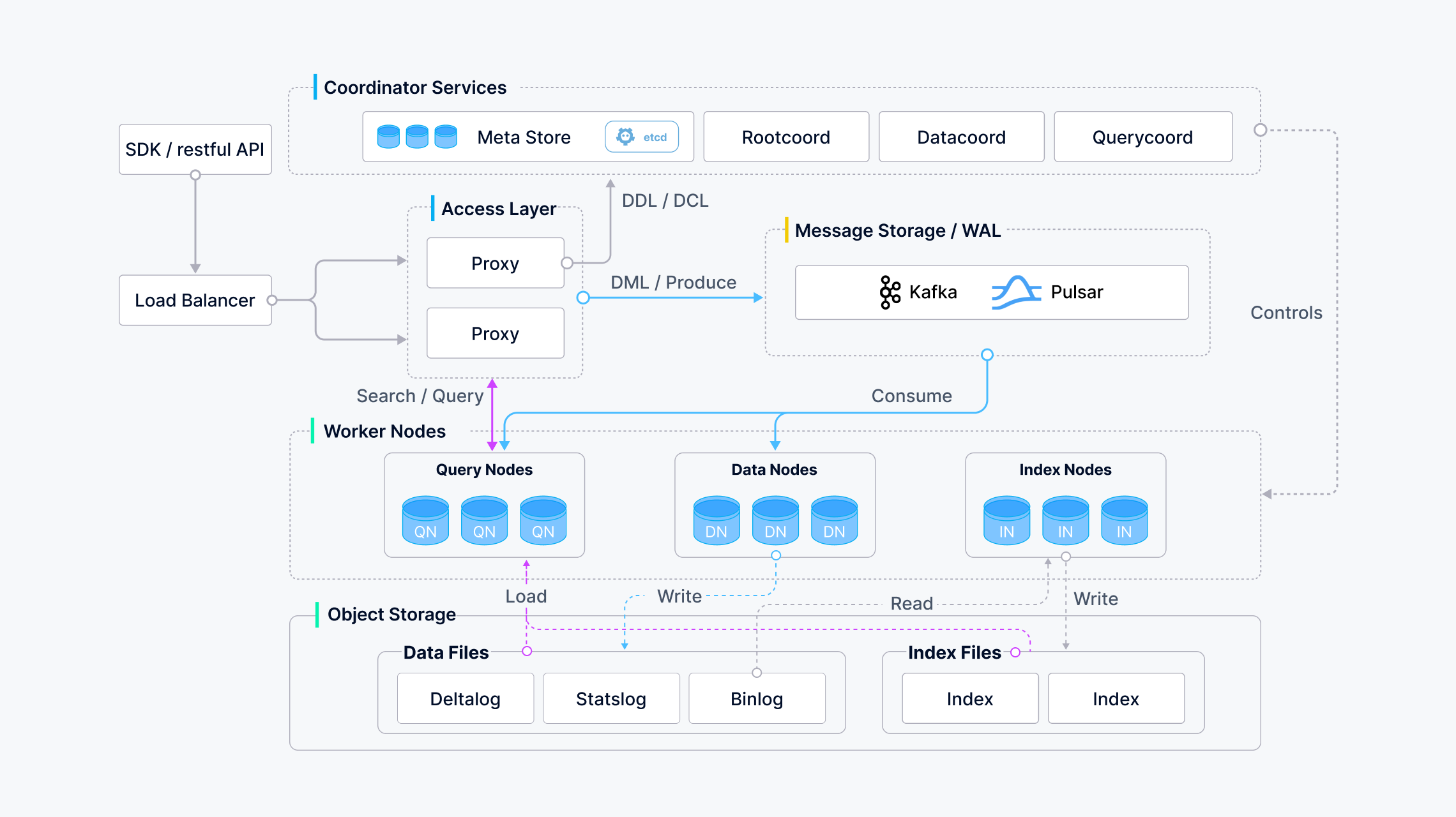
https://milvus.io/docs/v2.5.x/assets/milvus_architecture.png
{kind=link}
아키텍처 레이어 구성
- 데이터 플레인과 제어 플레인 분리 원칙에 따라
- 확장성 및 재해 복구 측면에서 상호 독립적인 4개의 레이어로 구성됨
| 레이어 | 레이어(번역) | 설명 |
|---|---|---|
| Access Layer 액세스 레이어 |
접근 계층 | - 사용자의 요청을 받고 결과를 돌려주는 앞단의 계층 - 여러 개의 Proxy로 구성 - Proxy는 상태를 저장하지 않고(stateless), - 들어오는 요청을 확인하고 결과를 모아서 사용자에게 전달 |
| Coordinator Service 코디네이터 서비스 |
조율 서비스 | - 시스템의 ‘두뇌’ 역할 - 워커 노드에게 작업 할당, 클러스터 관리, 부하 분산 - 시간 관리, 데이터 관리 등을 담당 |
| Worker Node 워커 노드 |
작업 노드 | - 실제 작업을 수행하는 노드 - 코디네이터의 지시에 따라 데이터 작업을 수행 |
| Storage 스토리지 |
저장 공간 | - 데이터의 지속성을 담당 (=데이터 저장 공간) - 시스템의 뼈대 |
액세스 레이어
- 사용자와의 상호작용을 담당하는 앞단
- Nginx, K8s, 인그레스, NodePort, LVS 와 같은 부하 분산 구성 요소 사용
코디네이터 서비스
- 시스템의 두뇌. 작업 할당, 클러스터 관리, 부하 분산.. 등
| 코디네이터 서비스 | 설명 |
|---|---|
| 루트 코디네이터 | 시스템 전반과 데이터 구조 총괄- DDL(데이터 정의), DCL(데이터 제어) 요청을 처리함 - 컬렉션, 파티션 또는 인덱스의 생성 및 삭제와 같은 작업 관리 - TSO(타임 스탬프 오라클) 및 시간 티커 발행을 관리 - 즉, 분산 시스템에서 고유하고 순차적인 타임스탬프를 생성하고 관리 |
| 쿼리 코디네이터 | 쿼리(검색) 요청 및 검색 데이터 상태 관리- 쿼리 노드 (검색을 담당하는 노드)의 상태를 관리 - 쿼리 작업에 대한 로드 밸런싱 (부하 분산) - 세그먼트 핸드 오프 (증가하는 세그먼트 -> 봉인된 세그먼트 상태 전환) |
| 데이터 코디네이터 | 데이터 처리, 저장 최적화 담당- 데이터 노드(새로운 데이터 받는), 인덱스 노드(검색 위한 인덱스) 관리 - 메타데이터 관리 - 데이터 처리, 저장 최적화 (플러시, 압축, 인덱스 생성) |
세그먼트의 상태 전환
Milvus는 데이터가 아래와 같은 두 가지 상태로 구분됨
(1) 증가하는 세그먼트(growing segment) : 실시간으로 쓰여지고 있는 데이터
(2) 봉인된 세그먼트(sealed segment) : 쓰기가 끝나고 읽기 전용으로 전환된 데이터
이 중 “봉인된 세그먼트”가 검색/쿼리의 대상이 됨
– 쿼리 코디네이터는 데이터의 세그먼트(상태) 전환을 조율함
– 이런 상태 전환을 핸드 오프(Hand-off)라고 부름
데이터 노드와 인덱스 노드
– 데이터 노드 : 새로운 벡터 데이터를 받아서 저장하는 역할.
– 인덱스 노드 : 벡터 검색을 빠르게 하기 위한 인덱스를 구축·저장하는 역할.
워커 노드
- 실제 작업을 실행하는 노드
| 노드 | 설명 |
|---|---|
| 쿼리 노드 | 검색 처리 담당- 실시간 데이터 및 과거 데이터를 로드하고, 여기에 검색 실행 - 이렇게 모은 데이터에 벡터 검색 및 스칼라 검색을 하이브리드로 실행 - 즉, 최신 + 과거 데이터에서 벡터 + 스칼라 하이브리드 검색 수행 |
| 데이터 노드 | 데이터 쓰기, 저장 담당- 실시간으로 쌓이는 데이터를 모으고, 이를 영구 저장하는 노드 - 증분 로그 데이터 구독(수집) - 클라이언트로부터 받은 변경(삽입, 삭제, 수정) 작업 수행 - 메모리 내 로그를 일정 단위로 모아 스냅샷 생성 -> 오브젝트 스토리지에 영구 저장 |
| 인덱스 노드 | 검색 속도 최적화 담당- 벡터 검색 속도를 높이기 위해 인덱스 생성 - 이를 통해 대량의 데이터 안에서 빠른 탐색이 가능케 함 - 인덱스 노드가 만든 인덱스는 저장소에 보관되고 - 쿼리 노드가 이렇게 만들어진 인덱스를 읽어 빠른 검색을 수행 - 항상 작동중일 필요가 없이, 작업이 있을 때에만 메모리에 올라서 동작하는 노드 |
✓ 쿼리 노드에서 다루는 실시간 데이터와 과거 데이터
– 실시간 데이터 : 로그 브로커로부터 수집한 증분 로그 데이터. 쿼리 노드는 증분 로그 데이터를growing segment로 전환한다.
– 과거 데이터 : 오브젝트 스토리지(minio 같은) 로부터 로드한 데이터
✓ 벡터 검색과 스칼라 검색
– 벡터 검색 : 벡터 유사도 검색. e.g. 임베딩 검색
– 스칼라 검색 : 숫자, 문자열 필터를 이용한 검색
– 하이브리드 검색 : 벡터 검색 + 스칼라 검색을 동시에 처리
스토리지
- 데이터 지속성을 담당하는 시스템의 뼈대.
| 스토리지 | 설명 |
|---|---|
| 메타 스토리지 | 메타정보 보관소- 메타데이터의 스냅샷을 저장하는 공간 - 메타데이터 : 수집 스키마, 메시지 소비 체크포인트 등 - 저장소로 etcd를 선택 (강력한 가용성, 일관성, 트랜잭션 때문) |
| 오브젝트 스토리지 | 대용량 데이터 보관소- 오브젝트는 저장하는 대상을 가리키며 - 로그의 스냅샷 파일 - 벡터, 스칼라 데이터의 인덱스 파일 - 중간 쿼리 결과를 저장함 - 저장소로 minio 를 선택 |
| 로그 브로커 | 실시간 데이터 스트림과 이벤트를 관리하는 전달자- milvus 는 데이터 삽입, 삭제를 실시간 로그로 관리함 - 이를 기반으로 데이터 지속성 및 이벤트 알림을 구현 - 시스템 장애로부터 복구될 때 증분 데이터의 무결성 보장 - 로그 브로커로 RocksDB 를 선택- Kafka 와 같은 스트리밍 데이터 저장 플랫폼으로 쉽게 대체 가능 |
로그 브로커 는 Milvus 클러스터에만 포함되며, Stand alone 에는 포함되지 않음.
Reference
https://milvus.io/docs/ko/architecture_overview.md
https://milvus.io/docs/ko/four_layers.md
https://milvus.io/docs/ko/main_components.md
Comments