SUM(PRICE)-- Window Function OVER(PARTITIONBYuserORDERBYdateROWSBETWEENUNBOUNDEDPRECEDINGAND1FOLLOWING)
Window 함수의 종류
전체 종류
함수명
설명
순위 함수 (Ranking Functions)
ROW_NUMBER()
각 파티션 내에서 고유한 순차적 정수를 1부터 부여합니다.
RANK()
동일한 값에 대해 같은 순위를 부여하며, 다음 순위는 건너뜁니다.
DENSE_RANK()
동일한 값에 대해 같은 순위를 부여하며, 다음 순위를 건너뛰지 않고 연속적으로 부여합니다.
NTILE(n)
파티션을 지정된 n개의 그룹(버킷)으로 나눕니다.
PERCENT_RANK()
윈도우 내에서 백분율 순위(0과 1 사이)를 계산합니다.
CUME_DIST()
윈도우 내에서 현재 행 값보다 작거나 같은 값들의 누적 분포를 계산합니다.
분석 함수 (Analytic Functions)
LAG(expr, offset, default)
현재 행을 기준으로 지정된 오프셋만큼 이전 행의 표현식(expr) 값을 반환합니다.
LEAD(expr, offset, default)
현재 행을 기준으로 지정된 오프셋만큼 이후 행의 표현식(expr) 값을 반환합니다.
FIRST_VALUE(expr)
윈도우 프레임 내의 첫 번째 행의 표현식(expr) 값을 반환합니다.
LAST_VALUE(expr)
윈도우 프레임 내의 마지막 행의 표현식(expr) 값을 반환합니다.
NTH_VALUE(expr, n)
윈도우 프레임 내의 n번째 행의 표현식(expr) 값을 반환합니다.
집계 함수 (Aggregate Functions)
SUM(expr)
윈도우 프레임 내 표현식(expr) 값의 합계를 계산합니다.
AVG(expr)
윈도우 프레임 내 표현식(expr) 값의 평균을 계산합니다.
COUNT(expr)
윈도우 프레임 내 행 또는 널이 아닌 값의 개수를 셉니다.
MAX(expr)
윈도우 프레임 내 표현식(expr) 값 중 최댓값을 반환합니다.
MIN(expr)
윈도우 프레임 내 표현식(expr) 값 중 최솟값을 반환합니다.
VAR_POP(expr)
윈도우 프레임 내 표현식(expr) 값의 모집단 분산을 계산합니다.
STDDEV_POP(expr)
윈도우 프레임 내 표현식(expr) 값의 모집단 표준 편차를 계산합니다.
예제 데이터
emp_id
emp_name
dept_id
salary
hire_date
1
Alice
10
6000
2021-01-10
2
Bob
10
5500
2020-03-15
3
Carol
20
7000
2019-08-01
4
Dave
20
7200
2022-06-05
5
Erin
10
6200
2023-02-20
emp_id : 사원 번호
emp_name : 사원 이름
dept_id : 부서 아이디
salary : 급여
hire_date : 입사일
이전 행 혹은 다음 행 참조
함수
설명
LAG(expr, offset)
이전 행의 값을 참조
LEAD(expr, offset)
다음 행의 값을 참조
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
-- 입사일 기준으로, 바로 전에 입사한 사원의 이름을 가져오세요.-- (1) LAG 이용SELECTemp_id,emp_name,hire_date,LAG(emp_name,1)OVER(ORDERBYhire_dateASC)pre_hiredFROMTEST_EMPLOYEEte-- (2) LEAD 이용SELECTemp_id,emp_name,hire_date,LEAD(emp_name,1)OVER(ORDERBYhire_dateDESC)pre_hiredFROMTEST_EMPLOYEEte
순위 및 번호 매기기
함수
설명
ROW_NUMBER()
정렬 기준으로 순차 번호를 매김
RANK()
순위 매기기. 동순위 허용하며, 동순위인 경우 순위 건너뜀
DENSE_RANK()
순위 매기기. 동순위 허용하며, 동순위인 경우 건너뛰지 않고 바로 다음 순위로
NTILE(n)
데이터를 n개의 동일 구간으로 분할
1
2
3
4
5
6
7
8
-- 부서별로 급여 순위를 매겨 `rank_in_dept` 컬럼으로 출력하세요.SELECTemp_id,emp_name,dept_id,salary,RANK()OVER(PARTITIONBYdept_idORDERBYsalaryDESC)FROMTEST_EMPLOYEEte
누적 집계
함수
설명
SUM(expr)
누적 합
AVG(expr)
누적 평균
COUNT(expr)
누적 개수
MIN(expr)
누적 최소값
MAX(expr)
누적 최대값
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
-- 입사일 기준으로 정렬했을 때, 각 사원의 누적 급여 합계를 구하세요.SELECTemp_id,emp_name,salary,hire_date,SUM(salary)OVER(ORDERBYhire_dateASC)FROMTEST_EMPLOYEEte-- 각 사원의 급여가 부서 평균보다 얼마나 높은지(차이)를 구하세요.SELECTemp_id,emp_name,dept_id,salary,AVG(salary)OVER(PARTITIONBYdept_id)dept_avg_salary,salary-(AVG(salary)OVER(PARTITIONBYdept_id))salary_gap_with_dept_avgFROMTEST_EMPLOYEEte
비율 계산
함수
설명
PERCENT_RANK()
백분위 순위 (0-1 사이)
CUME_DIST()
누적 분포 비율
1
2
3
4
5
6
7
8
-- 부서 내 급여의 상대적 위치를 백분율로 표현하라SELECTemp_id,emp_name,dept_id,salary,PERCENT_RANK()OVER(PARTITIONBYdept_idORDERBYsalary)FROMTEST_EMPLOYEEte
OVER() 의 구성 요소
PARTITION BY
파티션(데이터 그룹)을 나누는 역할
생략하면 전체 데이터가 하나의 파티션으로 간주된다.
GROUP BY 와 비슷하게 지정한 컬럼을 기준으로 그루핑한다.
1
2
3
4
5
6
7
8
9
10
11
-- 사용법OVER(PARTITIONBYUSER_ID)-- 부서별로 급여 순위를 매겨 `rank_in_dept` 컬럼으로 출력하세요.SELECTemp_id,emp_name,dept_id,salary,RANK()OVER(PARTITIONBYdept_idORDERBYsalaryDESC)FROMTEST_EMPLOYEEte
ORDER BY
파티션(혹은 파티션이 없다면 윈도우) 내에서 계산 순서를 정의
예) 시간순, 금액순 등 정렬 기준
1
2
3
4
5
6
7
8
9
10
-- 사용법OVER(ORDERBYCREATED_AT)-- 입사일 기준으로, 바로 전에 입사한 사원의 이름을 가져오세요.SELECTemp_id,emp_name,hire_date,LAG(emp_name,1)OVER(ORDERBYhire_dateASC)pre_hiredFROMTEST_EMPLOYEEte
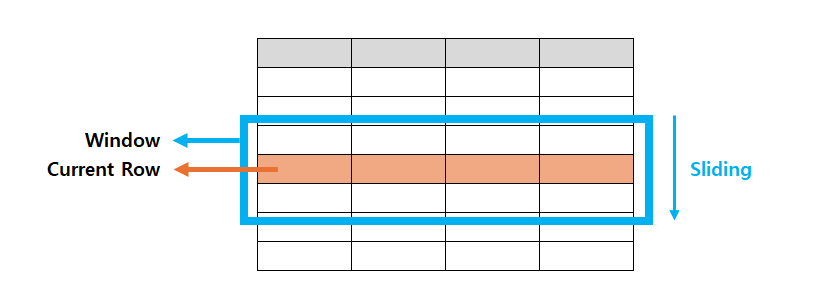
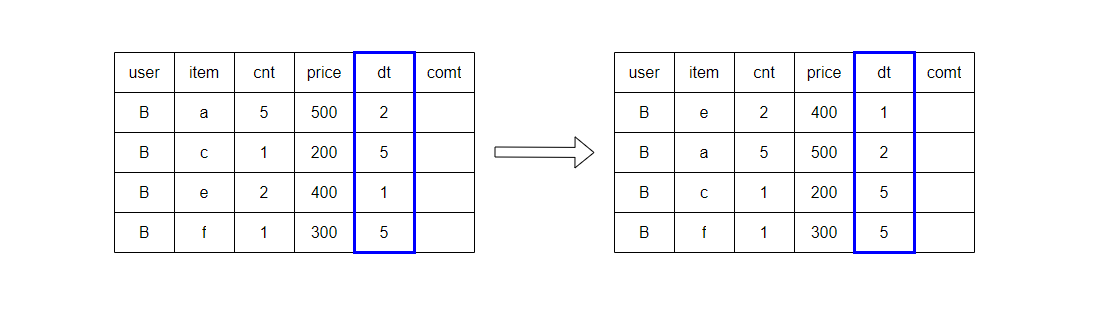
ROWS / RANGE
윈도우 프레임(Window Frame) 지정
프레임 : 정확히 몇 개의 행까지 계산에 포함할지
ORDER BY와 함께 사용되어 계산의 대상 범위를 몇 개의 행으로 할지 정의하는 것
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
-- 사용법OVER(PARTITIONBYUSER_IDORDERBYCREATED_ATROWSBETWEEN5PRECEDINGANDCURRENTROW)-- 입사일 기준 최근 2명 + 현재 사원의 급여 합 구하기SELECTemp_id,emp_name,hire_date,salary,SUM(salary)OVER(ORDERBYhire_dateROWSBETWEEN2PRECEDINGANDCURRENTROW)FROMTEST_EMPLOYEEte
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
-- 사용법RANGEBETWEENUNBOUNDEDPRECEDING-- 가장 처음 값부터 현재까지RANGEBETWEENUNBOUNDEDFOLLOWING-- 현재부터 가장 마지막 값까지RANGEBETWEENCURRENTROW-- 현재 행과 동일한 정렬값을 가진 모든 행RANGEBETWEEN<value>PRECEDING-- 현재 값보다 N만큼 작은 값 이상까지 포함RANGEBETWEEN<value>FOLLOWING-- 현재 값보다 N만큼 큰 값 이하까지 포함-- 현재 사원의 급여 이하의 사원 급여 총합 구하기SELECTemp_id,emp_name,hire_date,salary,SUM(salary)OVER(ORDERBYsalaryRANGEBETWEENUNBOUNDEDPRECEDINGANDCURRENTROW)FROMTEST_EMPLOYEEte




Comments