
집계 함수 종류
| 함수 | 설명 |
|---|---|
| COUNT(컬럼명) | NULL이 아닌 레코드의 개수를 반환 |
| COUNT(DISTINCT) | NULL이 아닌 레코드의 개수를 반환 (중복은 1개만 인정) |
| SUM(컬럼명) | 합계를 반환 |
| AVG(컬럼명) | 평균을 반환 |
| MAX(컬럼명) | 최대값을 반환 |
| MIN(컬럼명) | 최소값을 반환 |
| GROUP BY | 데이터를 그룹화 |
| HAVING | 그룹화 한 데이터에 대한 조건식. GROUP BY에 대한 WHERE 절. |
샘플 데이터
아래는 집계함수에서 사용할 샘플 데이터입니다.
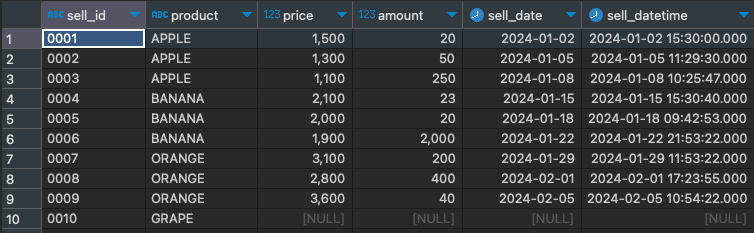
샘플 데이터 sql (열기/접기)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
DROP TABLE IF EXISTS `math_sample`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `math_sample` (
`sell_id` varchar(100) DEFAULT NULL,
`product` varchar(20) DEFAULT NULL,
`price` int(11) DEFAULT NULL,
`amount` int(11) DEFAULT NULL,
`sell_date` date DEFAULT NULL,
`sell_datetime` datetime DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1 COLLATE=latin1_swedish_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `math_sample`
--
LOCK TABLES `math_sample` WRITE;
/*!40000 ALTER TABLE `math_sample` DISABLE KEYS */;
INSERT INTO `math_sample` VALUES
('0001','APPLE',1500,20,'2024-01-02','2024-01-02 15:30:00'),
('0002','APPLE',1300,50,'2024-01-05','2024-01-05 11:29:30'),
('0003','APPLE',1100,250,'2024-01-08','2024-01-08 10:25:47'),
('0004','BANANA',2100,23,'2024-01-15','2024-01-15 15:30:40'),
('0005','BANANA',2000,20,'2024-01-18','2024-01-18 09:42:53'),
('0006','BANANA',1900,2000,'2024-01-22','2024-01-22 21:53:22'),
('0007','ORANGE',3100,200,'2024-01-29','2024-01-29 11:53:22'),
('0008','ORANGE',2800,400,'2024-02-01','2024-02-01 17:23:55'),
('0009','ORANGE',3600,40,'2024-02-05','2024-02-05 10:54:22'),
('0010','GRAPE',NULL,NULL,NULL,NULL);
/*!40000 ALTER TABLE `math_sample` ENABLE KEYS */;
UNLOCK TABLES;
집계 함수
COUNT
레코드의 개수를 반환합니다. 값이 NULL 인 경우는 COUNT에서 제외됩니다.
1
2
3
4
5
SELECT COUNT(*) FROM math_sample;
-- >> 10
SELECT COUNT(price) FROM math_sample;
-- >> 9
-- 0010 의 price 는 Null 이기 때문에 count에서 제외
DISTINCT는 중복된 값은 한 번만 카운팅합니다.
1
2
3
4
5
6
SELECT COUNT(DISTINCT product) FROM math_sample;
-- >> 4
-- APPLE, BANANA, ORANGE, GRAPE
SELECT COUNT(product) FROM math_sample;
-- >> 10
-- APPLE, APPLE, APPLE, BANANA, BANANA, BANANA, ORANGE, ORANGE, ORANGE, GRAPE
모든 컬럼에 대한 레코드 수를 조회할 때에는 * 을 사용합니다.
1
2
SELECT COUNT(*) FROM math_sample;
-- >> 10
SUM
지정한 컬럼의 합계를 반환합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
SELECT product, SUM(price) FROM math_sample
GROUP BY product;
+---------+------------+
| product | SUM(price) |
+---------+------------+
| APPLE | 3900 |
| BANANA | 6000 |
| GRAPE | NULL |
| ORANGE | 9500 |
+---------+------------+
SELECT product, SUM(price) FROM math_sample;
+---------+------------+
| product | SUM(price) |
+---------+------------+
| APPLE | 19400 |
+---------+------------+
DATE 혹은 DATETIME 형식도 합계가 가능합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
SELECT SUM(sell_date) FROM math_sample;
+----------------+
| SUM(sell_date) |
+----------------+
| 182161205 |
+----------------+
SELECT SUM(sell_datetime) FROM math_sample;
+--------------------+
| SUM(sell_datetime) |
+--------------------+
| 182161206224191 |
+--------------------+
연산할 수 있는 데이터 형식만 다룰 수 있으며, varchar와 같은 문자열은 0을 반환합니다.
1
2
3
4
5
6
SELECT SUM(product) FROM math_sample;
+--------------+
| SUM(product) |
+--------------+
| 0 |
+--------------+
AVG
평균을 반환합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
SELECT product, AVG(price), SUM(amount)
FROM math_sample GROUP BY product;
+---------+------------+-------------+
| product | AVG(price) | SUM(amount) |
+---------+------------+-------------+
| APPLE | 1300.0000 | 320 |
| BANANA | 2000.0000 | 2043 |
| GRAPE | NULL | NULL |
| ORANGE | 3166.6667 | 640 |
+---------+------------+-------------+
SELECT product, AVG(price), SUM(amount)
FROM math_sample;
+---------+------------+-------------+
| product | AVG(price) | SUM(amount) |
+---------+------------+-------------+
| APPLE | 2155.5556 | 3003 |
+---------+------------+-------------+
SUM과 같이 DATE, DATETIME과 같은 형식도 연산이 가능합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
SELECT AVG(sell_date) FROM math_sample;
+----------------+
| AVG(sell_date) |
+----------------+
| 20240133.8889 |
+----------------+
SELECT AVG(sell_datetime) FROM math_sample;
+---------------------+
| AVG(sell_datetime) |
+---------------------+
| 20240134024910.1111 |
+---------------------+
연산할 수 있는 데이터 형식만 다룰 수 있으며, varchar와 같은 문자열은 0을 반환합니다.
1
2
3
4
5
6
SELECT AVG(product) FROM math_sample;
+--------------+
| AVG(product) |
+--------------+
| 0 |
+--------------+
MAX, MIN
MAX 는 최대값을, MIN 은 최소값을 반환합니다.
1
2
3
4
5
6
7
8
9
10
SELECT product, MAX(price), MIN(price)
FROM math_sample GROUP BY product;
+---------+------------+------------+
| product | MAX(price) | MIN(price) |
+---------+------------+------------+
| APPLE | 1500 | 1100 |
| BANANA | 2100 | 1900 |
| GRAPE | NULL | NULL |
| ORANGE | 3600 | 2800 |
+---------+------------+------------+
DATE, DATETIME 의 경우 MIN은 가장 빠른 날짜, MAX는 가장 늦은 날짜를 반환합니다.
1
2
3
4
5
6
7
8
9
10
SELECT product, MAX(sell_date), MIN(sell_datetime)
FROM math_sample GROUP BY product;
+---------+----------------+---------------------+
| product | MAX(sell_date) | MIN(sell_datetime) |
+---------+----------------+---------------------+
| APPLE | 2024-01-08 | 2024-01-02 15:30:00 |
| BANANA | 2024-01-22 | 2024-01-15 15:30:40 |
| GRAPE | NULL | NULL |
| ORANGE | 2024-02-05 | 2024-01-29 11:53:22 |
+---------+----------------+---------------------+
문자열의 경우 사전적 순서에 따라서 MAX는 가장 큰 값(정렬시 마지막)을, MIN은 가장 작은 값(정렬시 처음)을 반환합니다.
1
2
3
4
5
6
SELECT MAX(product), MIN(product) FROM math_sample;
+--------------+--------------+
| MAX(product) | MIN(product) |
+--------------+--------------+
| ORANGE | APPLE |
+--------------+--------------+
GROUP BY
GROUP BY는 데이터를 그룹화grouping 하는 함수입니다.
위 예시 데이터를 보면 product가 APPLE, BANANA, ORANGE 인 레코드가 여러 개가 있습니다. 집계(혹은 통계)를 내기 위해 각각의 product로 묶어야 할 경우 GROUP BY product 라는 절을 추가하면 됩니다.
1
2
3
4
5
6
7
8
9
10
SELECT product, SUM(amount)
FROM math_sample GROUP BY product;
+---------+-------------+
| product | SUM(amount) |
+---------+-------------+
| APPLE | 320 |
| BANANA | 2043 |
| GRAPE | NULL |
| ORANGE | 640 |
+---------+-------------+
HAVING
HAVING 은 그룹화grouping 한 데이터에 대해 조회 조건을 적용하는 기능을 합니다. 즉 GROUP BY에 대한 WHERE 절이라고 보면 되겠습니다.
1
2
3
4
5
6
7
8
9
10
11
SELECT product, SUM(amount)
FROM math_sample
GROUP BY product
HAVING SUM(amount) > 600;
+---------+-------------+
| product | SUM(amount) |
+---------+-------------+
| BANANA | 2043 |
| ORANGE | 640 |
+---------+-------------+
Reference
혼자 공부하는 SQL (우재남)
연습용 데이터베이스 : https://www.mysqltutorial.org/
Math 함수 : https://inpa.tistory.com/
Comments