
Intro
최근에 맡게 된 프로젝트는 바로 추천 서비스입니다. 여러 가지 추천 모델을 개발하고, 이를 결합해 앙상블 모델을 만드는 작업을 진행하고 있습니다. 그러다가 추천 서비스에서 가장 어려운 부분을 만났는데요, 바로 추천 품질에 대한 정량적인 평가를 수행하는 것입니다. 추천의 본질이 실제 사용자의 만족도와 같은 정성적 평가지표에 크게 의존하기 때문에 정량적 평가에 대한 어려움을 크게 느끼고 있는 것 같습니다.
하지만 사업에서는 상대 업체의 신뢰를 얻고 설득력을 높이기 위해 정량적 평가만큼 중요한 것도 없습니다.
이번 포스트에서는 추천 서비스에 적용하기 좋을 정량적 평가 지표 4가지를 알아보고자 합니다. 여기저기서 다양한 자료를 찾아 참고해본 자료이므로 다소의 오류가 포함될 수 있음을 알립니다.
정량적 평가지표 4가지 요약
| 평가 방법 | 구분 | 설명 | 값의 범위 |
|---|---|---|---|
| HIT RATE | 추천 포함 여부 | 사용자가 선호하는 아이템 중 추천리스트에 포함된 비율. | 0 ~ 1 |
| RR & MRR | 랭킹 평가 | 사용자가 선호하는 아이템이 추천 리스트 중 상위에 노출되는 정도를 평가. | 0 ~ 1 |
| AP & MAP | 랭킹 평가 | 사용자의 모든 선호 아이템이 추천 리스트에 일관되게 상위에 노출되는지 평가. | 0 ~ 1 |
| DCG & NDCG | 랭킹 평가 | 사용자의 선호 정도(평점)와 추천의 순위를 복합하여 추천 리스트의 품질을 평가. | 0 ~ 1 |
단어 사용에 대한 안내
본 포스트에서는 “소비하다”와 “선호하다”를 비슷한 의미로 사용할 예정입니다. 참고해주세요.
-소비하다 : 사용자가 특정 아이템을 이용, 구매하거나 혹은 컨텐츠를 클릭하거나 시청한 것을 가리킵니다.
-(사용자가)선호하다 : 정량적 평가의 대상이 되는 실제 사용자의 소비 이력에 포함된 아이템. 본 포스트에서는 소비하다와 동일한 단어로 쓰일 수도 있습니다.
HIT RATE 히트 레이트
HIT RATE 개념과 계산법
히트 레이트를 직역하면 타율이라고 할 수 있습니다. 야구에서 타율은 타자가 들어선 총 타석 중에서 공을 쳐서 인플레이 상황을 만들고, 타자가 최소 1루를 밟은 비율을 의미합니다. 즉, 쉽게 말해 타자가 투수의 공을 맞춰 살아간 비율이라고 이해할 수 있습니다.
HIT RATE는 사용자가 실제로 소비한 항목이 추천 리스트에 포함되는 비율 을 측정합니다. 이 비율이 높을수록 추천 시스템이 사용자에게 적합한 추천을 했다고 볼 수 있는 것이죠.
HIT RATE는 두 가지 방향을 가질 수 있습니다.
(1) 사용자가 실제로 소비(선호)한 아이템 중 추천리스트에 포함된 아이템의 비율
(2) 추천리스트의 아이템 중 사용자가 실제로 소비(선호)한 아이템의 비율
(이해를 돕기 위한 그림을 아래에 준비했습니다.)
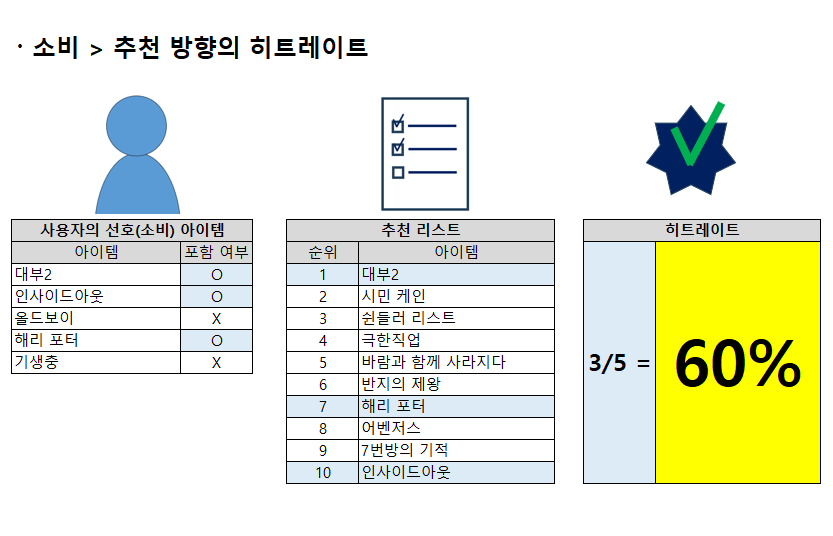
첫 번째는 사용자의 소비 아이템 중, 추천리스트에도 포함된 아이템의 비율을 계산하는 방법입니다. 히트레이트는 소비 아이템 리스트와 추천 리스트의 교집합을 분자로 하고, 사용자의 소비 아이템 개수를 분모로 하여 계산됩니다.
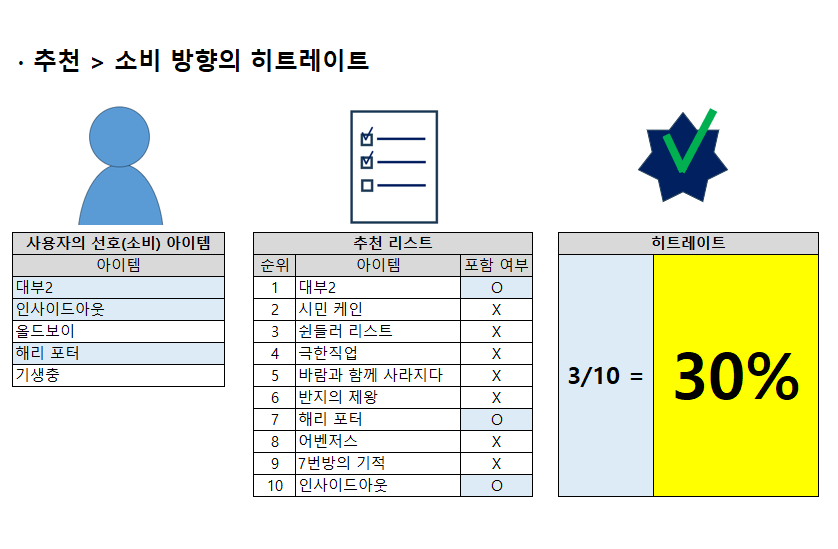
두 번째는 추천 리스트 중, 사용자의 소비 아이템에 포함된 아이템의 비율을 계산하는 방법입니다. 히트레이트는 소비 아이템 리스트와 추천 리스트의 교집합을 분자로 하는 것은 동일하지만, 분모는 추천 리스트의 아이템 개수가 됩니다.
보통은 두 번째 계산 방법을 히트레이트라고 하지만, 개인적으로는 두 계산법 중 무엇이 맞다고 할 수는 없다고 생각합니다. 프로젝트의 특성과 상황에 맞춰 방법을 택하는 것이 좋을 것 같습니다.
HIT RATE 사용시 주의할 점
Hit-Rate 방식에서 주의할 점이 있습니다. 바로 추천 리스트의 아이템 개수를 제한해야 한다는 것입니다. 만약 추천 리스트의 아이템 개수를 제한하지 않으면, 사용자가 선호하는는 아이템이 모두 추천 리스트에 포함되어 100%의 완벽한 추천처럼 보일 위험이 있습니다.
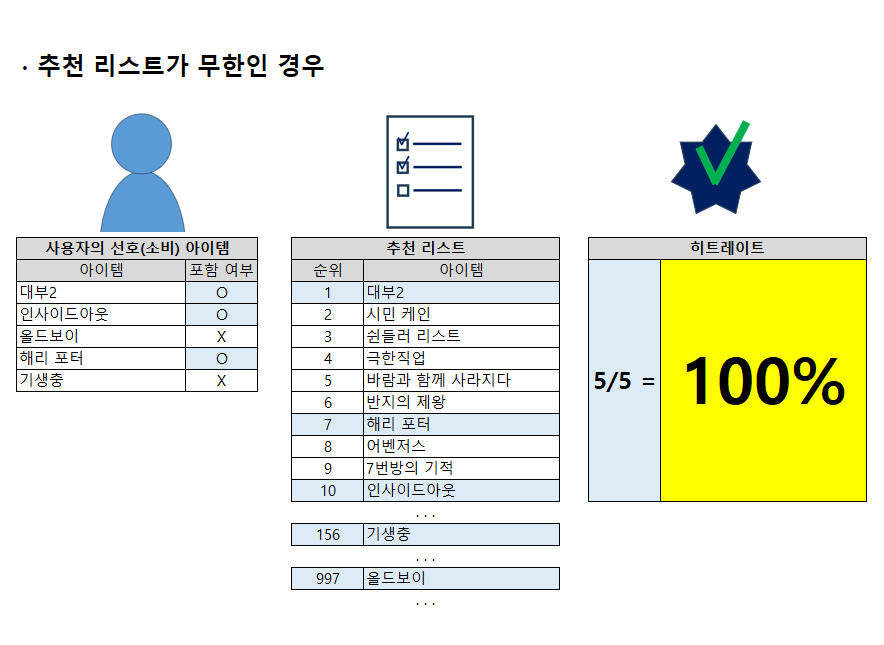
따라서 적정한 수의 추천 리스트 개수를 한정하길 바라며, 테스트 케이스의 데이터 양, 프로젝트의 특성, 혹은 아이템의 소비 속도와 패턴 등을 고려하여 결정해야 할 것으로 생각합니다.
랭킹 기반 평가
랭킹 기반 평가는 사용자가 선호하는 항목이 추천 리스트에서 얼마나 상위에 위치하는지를 평가하는 방법입니다. 히트 레이트가 추천의 적중률을 나타낸다면, 랭킹 기반 평가는 추천 순위의 성능을 측정하는 지표라고 할 수 있습니다.
랭킹 기반 평가에서는 크게 세 가지 지표를 알아보겠습니다. RR, AP 그리고 NDCG 입니다.
RR & MRR
RR (Reciprocal Rank) 은 사용자가 가장 선호하는 항목이 추천리스트에서 얼마나 빠르게(즉, 상위에) 노출되는지를 평가합니다. 사용자가 가장 선호한 아이템 A 가 추천 리스트의 k번째에 있을 경우, RR은 1/k 의 점수를 갖습니다.
사용자가 선호한 아이템이 여러 개일 경우, 사용자가 가장 먼저 선호한 아이템(처음 선택한 아이템) 또는 가장 선호하는 아이템(선호 정도가 높은 아이템)을 기준으로 점수를 산정합니다. 만약 선호 아이템들 간의 순서성(=선호 정도의 차이)이 없다면, 사용자가 선호한 아이템 중 추천 리스트의 가장 상위에 있는 아이템을 기준으로 점수를 산정합니다.
정리하자면 (1)사용자 선호 정도가 가장 높거나 소비 순서가 가장 빠른 아이템 (2)순서성이 없는 경우 추천 순서가 가장 빠른 아이템 을 기준으로 점수를 산정하는 것입니다.
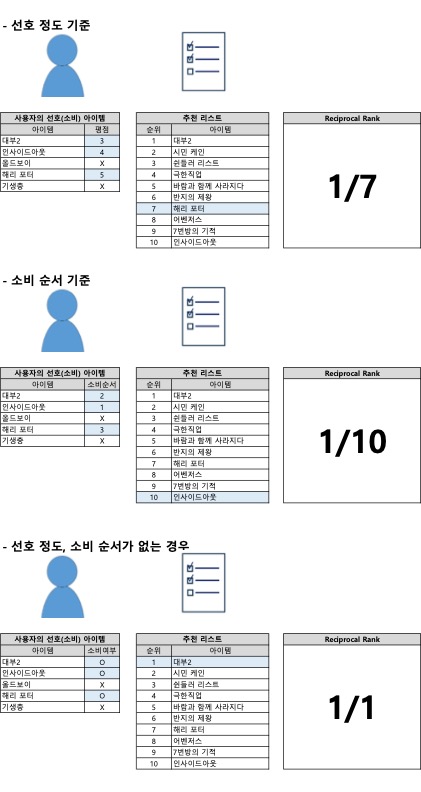
MRR (Mean Reciprocal Rank) 은 이러한 RR들의 평균값(Mean) 을 뜻합니다. 테스트의 대상이 되는 사용자 각각의 RR을 모두 더한 후, 이를 테스트 대상의 수로 나눈 값이 MRR입니다. 아래에서는 RR과 MRR에 대해 구체적인 예시와 함께 계산 방법을 알아보도록 하겠습니다.
(1) 선호에 대한 순서가 있을 경우
| 사용자 | 선호 아이템 | 추천 리스트 | RR 계산 | RR |
|---|---|---|---|---|
| 사용자1 | A, B | D, A, B, C | 1/2 | 0.5000 |
| 사용자2 | C | C, D, A, B | 1/1 | 1.0000 |
| 사용자3 | A, D | D, B, C, A | 1/4 | 0.2500 |
| 사용자4 | B, C, D | A, C, B, D | 1/3 | 0.3333 |
| MRR | 0.5208 |
(2) 선호에 대한 순서가 없을 경우
| 사용자 | 선호 아이템 | 추천 리스트 | RR 계산 | RR |
|---|---|---|---|---|
| 사용자1 | A, B | D, A, B, C | 1/2 | 0.5000 |
| 사용자2 | C | C, D, A, B | 1/1 | 1.0000 |
| 사용자3 | A, D | D, B, C, A | 1/1 | 1.0000 |
| 사용자4 | B, C, D | A, C, B, D | 1/2 | 0.5000 |
| MRR | 0.7500 |
AP & MAP
AP (Average Precision) 는 사용자가 선호하는 모든 아이템이 추천 리스트에서 얼마나 일관되게 상위에 노출되는지를 평가하는 지표입니다. AP는 ‘평균 정밀도’ 라고 번역할 수 있는데요, 이 지표는 에러율을 평가할 때 상위의 추천 항목이 틀린 경우, 하위에 위치한 틀린 항목보다 더 높은 점수가 깎이게끔 설계되어 상위 노출에 가중치를 부여합니다.
예를 들어, 사용자가 선호하는 아이템이 A, B 두 개이고, 추천 리스트가 D, A, B, C 순서로 구성되어 있다고 가정해봅시다. 선호 아이템 A에 대한 정밀도는 1/2로 계산됩니다. A는 추천 리스트에서 2번째로 등장하며, 추천 리스트의 1 ~ 2번째 항목 중 사용자가 선호하는 아이템은 A 하나이기 때문입니다. 다음으로 선호 아이템 B에 대한 정밀도는 2/3 으로 계산됩니다. B는 추천 리스트에서 3번째로 등장하며, 추천 리스트의 1 ~ 3번째까지 항목 중에서 사용자가 선호하는 아이템은 A, B 두 개가 있기 때문입니다. 이 두 개의 정밀도를 더한 후 아이템의 개수로 나눈 값인 0.583333… 이 사용자에 대한 AP 점수가 됩니다.
정리하자면 Average Precision 은 사용자의 선호 아이템 각각에 대해 정밀도를 계산한 뒤, 모두 더하고 이를 선호 아이템의 개수로 나눈 평균값 입니다.
그리고 MAP (Mean Average Precision) 는 여러 사용자의 AP를 모두 더한 뒤 평균(Mean)을 내는 값이죠.
| 사용자 | 선호 아이템 | 추천 리스트 | AP 계산 | AP |
|---|---|---|---|---|
| 사용자1 | A, B | D, A, B, C | (1/2 + 2/3) / 2 | 0.5833 |
| 사용자2 | C | C, D, A, B | (1/1) / 1 | 1.0000 |
| 사용자3 | A, D | D, B, C, A | (2/4 + 1/1) / 2 | 0.7500 |
| 사용자4 | B, C, D | A, C, B, D | (2/3 + 1/2 + 3/4) / 3 | 0.6389 |
| MAP | 0.7431 |
DCG, NDCG
DCG (Discounted Cumulative Gain) 는 사용자의 선호 정도와 추천의 순위를 복합하여 추천 리스트의 품질을 평가하는 지표입니다. 아이템 A에 대해 사용자가 평가한 선호 점수를 r, 추천 리스트에서 A의 등장 순서를 k라고 했을 때 r / log2( 1+ k ) 로 점수를 계산됩니다. 모든 아이템에 대해 이 점수를 계산한 후, 더한 것이 바로 DCG 입니다. 아래 풀이식을 함께 보시죠.
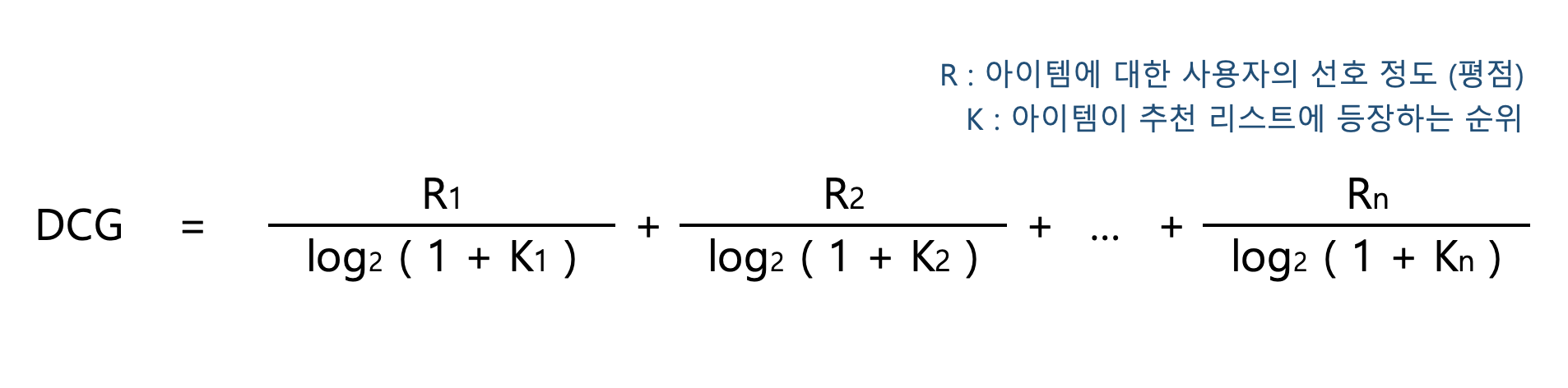
DCG의 풀이식을 아래와 같이 줄여서 표현합니다. 여기서 i는 추천 리스트에서의 아이템 순서를 의미합니다. 즉, 추천 리스트에 포함된 모든 아이템에 대해 점수를 계산하는 방법입니다. 하지만 사용자의 평점이 없는 경우엔 0을 log2(i+1) 로 나누는 것이므로 결국 점수는 0이 됩니다. 저는 이러한 불필요한 계산을 피하기 위해 사용자가 선호하는 아이템만 점수를 계산하는 방식을 선호합니다. 하지만 두 방식 중 어떤 방식으로 계산하더라도 결과값은 동일하므로 큰 문제는 없습니다.
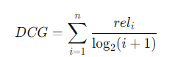
아래 코드는 두 가지 계산 방법을 비교해본 예시입니다. 계산시간에서 꽤 큰 차이가 보임을 알 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 실제 소요 시간 계산
# 유저는 5개의 랜덤한 아이템을 소비, 추천 아이템의 개수는 10,000,000 개
cnt = 10000000
user = { random.randrange(1, cnt, 1) : random.randint(1, 5) for x in range(0, 5) }
reco = { x:x for x in range(0, cnt) }
# 모든 아이템을 돌면서 DCG 계산
start = time.time()
dcg = 0.0
for i, r in enumerate(reco):
try:
dcg += user[r]/math.log2(1+(i+1))
except:
dcg += 0
print(f'모든 아이템 계산 / DCG = {dcg:.5f} / 소요 시간 : {time.time() - start:.5f}')
# 사용자가 소비한 아이템만 DCG 계산
start = time.time()
dcg = 0.0
for u in user:
dcg += user[u]/math.log2(1+(reco[u]+1))
print(f'소비 아이템만 계산 / DCG = {dcg:.5f} / 소요 시간 : {time.time() - start:.5f}')
# 출력 결과
>> 모든 아이템 계산 / DCG = 0.66229 / 소요 시간 : 2.02988
>> 소비 아이템만 계산 / DCG = 0.66229 / 소요 시간 : 0.00014
만약 추천 아이템이 평점을 매길 수 있는 게 아니라면 어떻게 될까요? 영화나 제품 등에는 리뷰와 함께 5점 만점에 4.5점과 같은 평점을 줄 수 있습니다. 하지만 유튜브 영상 컨텐츠에는 이러한 평점 시스템이 없습니다. 사용자는 단지 ‘좋아요’ 혹은 ‘싫어요’를 누를 뿐입니다. 이렇게 LIKE / DISLIKE 만 있는 경우에는 LIKE 를 1점, DISLIKE 혹은 무응답을 0점으로 계산합니다.
NDCG (Normalized Discounted Cumulative Gain) 은 DCG를 정규화(Normalized) 한 값입니다. DCG는 사용자의 선호 아이템 개수가 많을수록 높은 점수가 나올 확률이 높아지는 편향성이 있습니다. 이러한 편향성을 방지하기 위해 DCG 점수를 정규화하는 NDCG 가 만들어졌습니다.
DCG를 정규화 하는 방법은 실제 DCG 값 ÷ 이상적인 DCG 값 입니다. 이상적인 DCG는 이상적인(즉, 완벽한) 추천 리스트에서 얻을 수 있는 DCG 값을 의미하며, 이를 iDCG 라고 부릅니다. 이상적인 추천 리스트란 사용자가 선호하는 아이템 중 가장 평점이 높은 것부터 추천 리스트의 1, 2, 3.. 순위를 차지하는 것입니다. 따라서 iDCG는 고정된 상수값이 아니라, 사용자의 선호 상황에 따라 달라질 수 있습니다.

NDCG는 위에서 계산된 DCG를 iDCG로 나누기만 해주면 됩니다. 아래 구체적인 예시를 통해 더 자세히 알아보겠습니다.

| 사용자 | 선호 아이템 (선호점수) | 추천 리스트 | DCG 계산 | DCG | iDCG 계산 | iDCG | NDCG |
|---|---|---|---|---|---|---|---|
| 사용자1 | A(5), B(3) | D, A, B, C | 5/log2(1+2) + 3/log2(1+3) |
4.6546 | 5/log2(1+1) + 3/log2(1+2) |
6.8928 | 0.6953 |
| 사용자2 | C(5) | C, D, A, B | 5/log2(1+1) | 5.0000 | 5/log2(1+1) | 5.0000 | 1.0000 |
| 사용자3 | A(2), D(1) | D, B, C, A | 2/log2(1+4) + 1/log2(1+1) |
1.8614 | 2/log2(1+1) + 1/log2(1+2) |
2.6309 | 0.7075 |
| 사용자4 | B(5), C(4), D(3) | A, C, B, D | 5/log2(1+3) + 4/log2(1+2) + 3/log2(1+4) |
6.3157 | 5/log2(1+1) + 4/log2(1+2) + 3/log2(1+3) |
9.0237 | 0.6999 |
| NDCG 평균 | 0.7707 |
마치며
이 외에도 추천 시스템을 평가하는 지표는 여러 가지가 있습니다. 또한, 프로젝트나 서비스의 특성에 따라 맞춤형 평가 지표를 개발해야 할 필요가 있을 수도 있습니다. 중요한 것은, 각 지표가 의미하는 바를 이해하고, 추천 리스트를 어떻게 평가해야하는지 감을 잡아가는 과정이라고 생각합니다.
그리고 추천은 정량적 지표가 아닌 정성적인 지표가 매우 중요하다는 특징을 가지고 있습니다. 사용자들에게 만족도를 조사하고, 불편한점을 파악하여 이를 추천 시스템에 녹여내는 것이 중요한 점이죠.
이러한 다양한 평가 지표를 활용해 추천 시스템을 다각도로 평가하고, 피드백을 받아 개선해 나가는 과정을 통해 성공적인 추천 시스템을 구축할 수 있기를 바랍니다.
Reference
NDCG : wikipedia : DCG
NDCG, MAE, ARHR .. : Recommender_systems_handbook
MRR, MAP, NDCG : Naver Blog - nilsine11202
MDCG, MAP, HitRate : tistory - lsjs92
Precision, Recall, HitRate, MAP, MRR, nDCG : tistory - white-joy
Precision, Recall, NDCG, HitRate, MAE, RMSE : tistory - sungkee-book
Comments