
OpenCV
OpenCV 설치
여러 설치 방법이 있으며, 자신에게 맞는 설치 방법을 선택하면 된다.
이 포스트에서는 Conda 로 설치해 진행한다.
- Github : https://github.com/opencv/opencv/releases
- SourceForge : https://sourceforge.net/projects/opencvlibrary/files/
- Linux 판 : https://pkgs.org/search/?q=opencv
- Pypi : https://pypi.org/search/?q=opencv
- Conda : https://anaconda.org/search?q=opencv
- Java eclipse : https://docs.opencv2.org/4.x/d1/d0a/tutorial_java_eclipse.html
- 안드로이드 : https://docs.opencv2.org/4.x/d7/dbd/tutorial_android_ocl_intro.html
1
2
3
conda install opencv
핵심 기능 The Core Functionality
Mat - The Basic Image Container
Open CV로 이미지 스캔, 조회 테이블, 시간 측정 스캔
Mask operations on matrices
이미지 작업 Operations with images
이미지 입출력
1
2
3
4
5
6
7
8
9
10
11
12
# OpenCV 라이브러리 import
import cv2
# 이미지 경로 선언
path = 'path/of/imagefile.extension'
# 이미지 불러오기 : 3채널 컬러 이미지
img_rgb = cv2.imread(path)
# 이미지 불러오기 : 그레이 스케일
img_gray = cv2.imread(path, cv2.IMREAD_GRAYSCALE) # 방법 1
img_gray = cv2.imread(path, 0) # 방법 2
이미지 보기
1
2
3
4
5
6
7
8
9
10
11
12
# 이미지 보기
import cv2
path = 'path/of/imagefile.extension'
img_rgb = cv2.imread(path)
img_gray = cv2.imread(path, 0)
cv2.imshow('컬러 이미지', img_rgb)
cv2.waitKey()
cv2.imshow('그레이 이미지', img_gray)
cv2.waitKey()
위 코드를 실행하면 컬러 이미지와 그레이 이미지가
각각 새로운 윈도우에서 보여진다.
cv2.waitKey() 메서드는 사용자가 키(키보드) 입력을 기다리는 메서드이다. 인터프리터가 해당 메서드를 만나면 사용자의 키 입력을 기다렸다가, 키가 입력되면 다음 코드를 실행하게 된다.

이미지 저장
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 이미지 저장
import cv2
import numpy as np
# 랜덤int 500 x 500 픽셀 3channel RGB ndarray생성
img = np.random.randint(0, 256, size=(500, 500, 3), dtype=np.uint8)
# 이미지 보기
cv2.imshow('img', img)
cv2.waitKey()
# 이미지 저장
cv2.imwrite('/Users/jongya/Desktop/example.png', img) # png로 저장
cv2.imwrite('/Users/jongya/Desktop/example.jpg', img) # jpg로 저장


픽셀 강도(intensity) 제어
픽셀이란, 이미지을 이루는 가장 작은 단위인 사각형의 점을 뜻한다.
이 픽셀에는 빨간색, 초록색, 파란색 등 색 정보가 담겨있다. (그레이스케일은 명암 정도만)
위에서 만든 랜덤 이미지에서 [100, 100] 픽셀의 색 정보를 불러와보겠다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# pixel intensity 보기
import cv2
import numpy as np
# 랜덤 이미지 만들기
img = np.random.randint(0, 256, size=(500, 500, 3), dtype=np.uint8)
cv2.imshow('img', img)
cv2.waitKey()
# 이미지의 특정 픽셀 값 출력
# _intensity = img[y, x]
_intensity = img[100, 100]
print(_intensity)
==> [202 226 1]
[100, 100] 픽셀의 색상은 [202, 226, 1] 임을 알 수 있다.
이 색상이 무엇인지 알아보기 위해, [202, 226, 1] 이라는 색상으로 채운 500x500 픽셀을 만들어보겠다.
1
2
3
4
5
6
7
import numpy as np
import cv2
img = np.ones((500, 500, 3), dtype=np.uint8) * np.array([202, 226, 1], dtype=np.uint8)
cv2.imshow('img', img)
cv2.waitKey()
이 코드에서는 500x500x3channel shape의 ndarray를 만든 후, 각 값을 [202, 226, 1]로 설정을 해주었다.
만들어진 이미지는 아래와 같다.

픽셀 강도 (intensity)
픽셀의 강도는 [b, g, r] 식으로 출력됨을 볼 수 있다.
이는 순서대로 색의 3원색인 Blue, Green, Red 를 뜻한다.
우리는 평소에 3원색을 RGB라고 표현한다.
그런데 왜 cv에서는 RGB가 아닌 BGR의 순서를 사용할까?
바로, 픽셀 강도 값을 불러올 때 리스트의 마지막 값부터 빼오기 때문이다. 아래의 예시를 참고해보자.
| 픽셀 강도 | –읽어들임–> | 읽어들인 값 |
|---|---|---|
| [B, G, R] | –> | [] |
| [B, G] | –> | [R] |
| [B] | –> | [R, G] |
| [] | –> | [R, G, B] |
즉, 픽셀 강도가 B, G, R 순서로 되어있어야 읽어들였을 때 RGB의 순서가 될 수 있는 것이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
import numpy as np
import cv2
img = cv2.imread('/path/of/img.jpg')
print("100, 100 픽셀의 Blue 값 : ", img[100, 100, 0])
print("100, 100 픽셀의 Green 값 : ", img[100, 100, 1])
print("100, 100 픽셀의 Red 값 : ", img[100, 100, 2])
# 출력
# 100, 100 픽셀의 Blue 값 : 202
# 100, 100 픽셀의 Green 값 : 226
# 100, 100 픽셀의 Red 값 : 0
픽셀 강도 제어
픽셀 강도를 제어하는 방법은 여러 가지가 있으며, 아래를 참고한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
import numpy as np
import cv2
img = cv2.imread('/Users/jongya/Desktop/ttt.jpg')
_intensity = img[100, 100]
print("변경 전 color 값 : ", _intensity)
# 3channel 값 모두 변경
img[100, 100] = 150
_intensity = img[100, 100]
print("변경 후-1 color 값 : ", _intensity)
# 3channel 값 각각 변경
img[100, 100] = [100, 150, 200]
_intensity = img[100, 100]
print("변경 후-2 color 값 : ", _intensity)
# Blue 값만 변경
img[100, 100, 0] = 0
_intensity = img[100, 100]
print("변경 후-3 color 값 : ", _intensity)
# Green 값만 변경
img[100, 100, 1] = 10
_intensity = img[100, 100]
print("변경 후-4 color 값 : ", _intensity)
# Red 값만 변경
img[100, 100, 2] = 30
_intensity = img[100, 100]
print("변경 후-5 color 값 : ", _intensity)
# 출력
# 변경 전 color 값 : [202 226 0]
# 변경 후-1 color 값 : [150 150 150]
# 변경 후-2 color 값 : [100 150 200]
# 변경 후-3 color 값 : [ 0 150 200]
# 변경 후-3 color 값 : [ 0 10 200]
# 변경 후-3 color 값 : [ 0 10 30]
픽셀 좌표
픽셀의 위치값은 [y, x] 좌표로 표시된다.
즉, 세로축을 뜻하는 y가 먼저, 그 다음 가로축을 뜻하는 x값이 들어가게 된다.
이는 cv에서 다루는 img가 ndarray 형태라는 것을 생각하면 쉽게 이해가 될 것이다.
아래 예시에서는 500 x 500 픽셀 이미지를 4등분하여, 좌측 상단부터 Blue, Green, Red, Black 을 표시해보았다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import cv2
import numpy as np
img = np.ones((500, 500, 3), dtype=np.uint8)
for y, row in enumerate(img):
for x, pixel in enumerate(row):
if (y<250)&(x<250):
img[y, x] = [255, 0, 0] # Blue
elif (y<250)&(x>=250):
img[y, x] = [0, 255, 0] # Green
elif (y>=250)&(x<250):
img[y, x] = [0, 0, 255] # Red
else:
img[y, x] = [0, 0, 0] # Black
cv2.imshow('img', img)
cv2.waitKey()
cv2.destroyAllWindows()

이미지의 복사
cv에서는 img의 값을 ndarray로 표시한다.
따라서 이미지의 복사는 numpy.copy() 메서드를 이용한다.
이 때에는 deepcopy가 되기 때문에 각각은 다른 주소값을 가지게 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import cv2
import numpy as np
# 위에서 만든 4color 이미지를 불러오고
img = cv2.imread('./4color.jpg')
# img_copy 변수에 이를 복사한 뒤,
# 복사 후 검은색으로 변경한다.
img_copy = np.copy(img)
img_copy[:] = 0
cv2.imshow('img', img)
cv2.waitKey()
cv2.imshow('img_copy', img_copy)
cv2.waitKey()

greyscale 로 변경
cv2.cvtColor 메서드와 cv2.COLOR_BGR2GRAY 옵션을 통해 이미지를 greyscale 로 변경할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import cv2
import numpy as np
# 위에서 만든 4color 이미지를 불러오고
img = cv2.imread('./4color.jpg')
# greyscale로 변경
img_grey = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 검은색으로 변경
img_black = np.copy(img)
img_black[:] = 0
cv2.imshow('img', img)
cv2.imshow('img_grey', img_grey)
cv2.imshow('img_black', img_black)

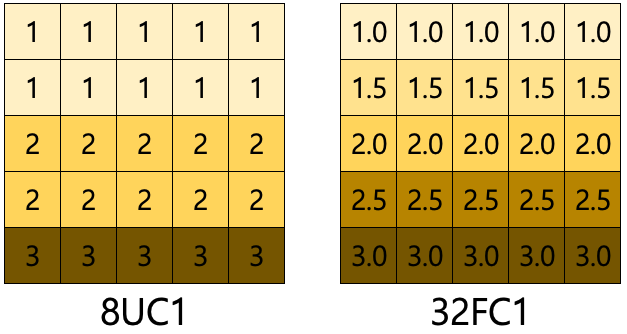
이미지 값 유형 : 8UC1, 32FC1
이미지 픽셀 강도는 8UC1 와 32FC1 두 유형이 있다.
8UC1 는 8비트 int값 즉, 픽셀 강도를 정수 값 0~255 범위로 나타낸다. 이를 다시 말하면 색상을 각각 256개의 강도로 나누어 표현이 가능하다는 것이다.
32FC1 는 32비트 float값 즉, 픽셀 강도를 부동 소수점 값 0.0 ~ 1.0 범위로 나타낸다. 표현할 수 있는 값의 종류가 8UIC보다 많기 때문에 더욱 정밀한 색 표현이 가능하다.
| 항목 | 8UC1 | 32FC1 |
|---|---|---|
| 자료형 | np.uint8 정수형 | np.float32 부동소수점 |
| 값 범위 | 0 ~ 255 | 0.0 ~ 1.0 |
| 표현할 수 있는 값 종류 | 256가지 | 3.4 * 10^38 가지 |
| 기본적인 시각화 작업에 유용 | 사실상 무한대 표현(사람이 구별할 수 있는 색상을 넘어섬) | |
| 비고 | 부드러운 그래디언트 표현 제한적 | 부드러운 그래디언트 표현 가능 |
이해를 돕기 위해 아래와 같이 예시 그림을 그려봤다.
단, 정확한 표현이 아닌, 개념적인 표현임을 명심하자.
이미지 값 유형 변경
8UC1 과 32FC1 간의 변경은 아래와 같이 가능하다.
먼저, uint8로 만든 8UC1 gradient image 를 32FC1 으로 변경하는 예시.
1
2
3
4
5
6
7
8
9
10
import numpy as np
import cv2
img_8UC1 = np.zeros((500, 500, 3), dtype=np.uint8)
for i in range(500):
for j in range(500):
img_8UC1[i,j] = [i//2, j//2, (i+j)//4]
img_32FC1 = img_8UC1.astype(np.float32)/255.0

다음은 float32로 만든 32FC1 gradient image 를 8UC1 으로 변경하는 예시.
1
2
3
4
5
6
7
8
9
10
import numpy as np
import cv2
img_32FC1 = np.zeros((500, 500, 3), dtype=np.float32)
for i in range(500):
for j in range(500):
img_32FC1[i,j] = [i/500, j/500, (i+j)/500]
img_8UC1 = cv2.convertScaleAbs(img, alpha=255)
# img_32FC1 = img * 255
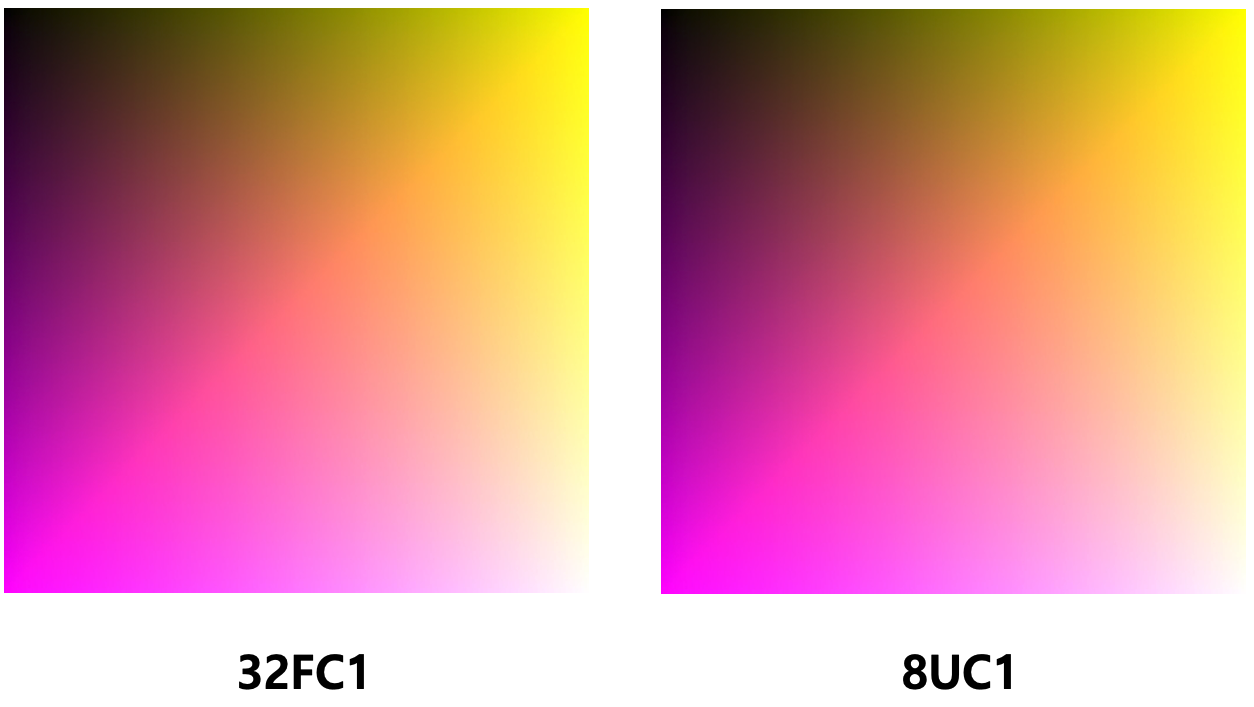
Blending
블렌딩은 두 이미지를 혼합하는 것을 말한다.
맛있는 크로칸슈 JPG 이미지와, 투명 배경에 ‘Croquant Chou’ 라는 텍스트가 있는 PNG 이미지를 합쳐보겠다.
(1) OpenCV의 addWeighted 메서드를 이용하는 방법
(2) numpy 에서 직접 계산하는 방법
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# (1) OpenCV의 메서드를 이용하는 방법
import cv2
import numpy as np
src1 = cv2.imread('/path/to/croquant_img.jpg')
src2 = cv2.imread('/path/to/croquant_txt.png')
alpha = 0.5
beta = 1 - alpha
# alpha : blending 시 첫 이미지를 살릴 비율
# beta : blending 시 두 번째 이미지를 살릴 비율
# alpha + beta = 1.0
dst = cv2.addWeighted(src1, alpha, src2, beta, 0.0)
1
2
3
4
5
6
7
8
9
10
11
# (2) numpy 에서 직접 blending
import cv2
import numpy as np
src1 = cv2.imread('/path/to/croquant_img.jpg')
src2 = cv2.imread('/path/to/croquant_txt.png')
alpha = 0.5
beta = 1 - alpha
dst = np.uint8((alpha * src1) + (beta * src2))

(croquant_txt 이미지는 png 파일로, 검은 부분은 투명을 나타낸다.)
alpha 와 beta 값은 각 이미지를 얼마나 섞을지를 결정한다.
위 예시에서는 두 이미지를 0.5씩 (=50%씩) 서로 양보하면서 섞었다.
이제 alpha와 beta 모두를 1.0의 값을 줘서 섞는다면 아래와 같이 된다.
1
2
3
4
5
6
7
8
9
src1 = cv2.imread('/path/to/croquant_img.jpg')
src2 = cv2.imread('/path/to/croquant_txt.png')
alpha = 1
beta = 1
# alpha : blending 시 첫 이미지를 살릴 비율
# beta : blending 시 두 번째 이미지를 살릴 비율
dst = cv2.addWeighted(src1, alpha, src2, beta, 0.0)

addWeighted 메서드의 γ(감마) 값을 조절하면 이미지 전체의 밝기를 조절할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import cv2
import numpy as np
src1 = cv2.imread('/Users/jongya/Desktop/img_rgb.jpg')
src2 = cv2.imread('/Users/jongya/Desktop/croq_text.png')
alpha = 0.5
beta = 1 - alpha
dst_1 = cv2.addWeighted(src1, alpha, src2, beta, -255.0)
dst_2 = cv2.addWeighted(src1, alpha, src2, beta, -150.0)
dst_3 = cv2.addWeighted(src1, alpha, src2, beta, -50.0)
dst_4 = cv2.addWeighted(src1, alpha, src2, beta, 0.0)
dst_5 = cv2.addWeighted(src1, alpha, src2, beta, 50.0)
dst_6 = cv2.addWeighted(src1, alpha, src2, beta, 150.0)
dst_7 = cv2.addWeighted(src1, alpha, src2, beta, 255.0)

Contrast and Brightness
이미지의 대비와 밝기를 조절하는 방법을 기술한다.
우선, 기본적인 대비와 밝기 조절의 원리는 아래와 같다.
1
2
3
4
5
6
7
new_img = (alpha * img) + beta
# alpha : 밝기 조절. intensity 에 곱하기
# beta : 대비 조절. intensity 에 더하기
# img : ndarray 형태
여기에 numpy의 clip 메서드를 적용하여 ndarray의 최소값과 최대값을 제한해준다.
1
2
3
4
5
6
7
8
9
import numpy as np
new_img = np.clip((alpha * img) + beta, min_v, max_v)
# np.clip
# ndarray 내의 원소값들에 대해
# min 값보다 작은 값들은 min 값으로 바꿔주고
# max 값보다 큰 값들은 max 값으로 바꿔준다.
원리는 픽셀의 intensity를 곱하거나 더해서 값을 조절하는 것이다.
대비 조절은 곱하기를 통해, 그리고 밝기 조절은 더하기를 통해 조절이 된다. 즉, 원리는 동일한 것. 다만, 값을 증감시키는 방식이 곱하기냐 더하기냐에 따라 달라진다.
원래 값이 작다면 곱하기를 통해 변경되는 값의 폭은 적고, 원래 값이 크다면 곱학를 통해 변경되는 값의 폭은 크게 된다. 하지만 더하기는 원래 값이 작든 크든 연산을 통한 변경 값의 폭은 동일하다.
다음은 ndarray의 연산 방법을 살펴보자.
이미지의 ndarray의 자료형태는 np.uint8로, 기본적으로 2^8개인 256개의 값을 표현할 수 있다.
uint8 타입의 ndarray에 곱하기와 더하기 연산이 진행되면서 uint8이 표현할 수 있는 범위인 0 ~ 255 을 벗어나면 랩어라운드(Wrap around) 가 일어나면서 255를 초과하는 값만이 표시된다.
여기에 np.clip을 타입 지정하기 전에 적용함을 통해 최대값과 최소값을 제한함으로써 astype을 통한 랩어라운드가 일어나기 전에 조정값이 소실되지 않게끔 한다. 자세한 것은 아래에서 예를 든다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
test = np.array([[[10, 20, 30], [40, 50, 60]],[[70, 80, 90], [100, 110, 120]]])
print(3 * test)
- [[[ 30, 60, 90],[120, 150, 180]],
- [[210, 240, 14],[ 44, 74, 104]]]
# 10은 30이 되지만
# 120은 360 - 256 = 104 가 된다.
print(test + 200)
- [[[210, 220, 230],[240, 250, 260]],
- [[ 270, 280, 290],[300, 310, 320]]]
# 곱하기와 달리 값이 잘리지 않음을 볼 수 있다.
print((test + 200).astype(uint8))
- [[[210, 220, 230],[240, 250, 4]],
- [[ 14, 24, 34],[ 44, 54, 64]]]
# uint8 타입으로 제한하면, 랩어라운드가 일어난다.
# 랩어라운드는 test를 선언할 때에 타입을 적용해도 일어난다.
print(np.clip(1.5 * test + 120), 0, 255)
- [[[135., 150., 165.],[180., 195., 210.]],
- [[225., 240., 255.],[255., 255., 255.]]]
# np.clip을 통해 uint8 범위를 벗어나는 값들은 모두
# 255라는 최대범위로 표현됨을 볼 수 있다.
실제 밝기와 대비 조절에 대한 예시는 아래와 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import cv2
import numpy as np
import matplotlib.pyplot as plt
img_origin = cv2.imread('/Users/jongya/Desktop/img_rgb.jpg')
alpha = 1.0
beta = 0
min_v = 0
max_v = 255
img_after = np.clip(alpha * img_origin + beta, min_v, max_v).astype(np.uint8)
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(10, 5))
ax1.imshow(cv2.cvtColor(img_origin, cv2.COLOR_BGR2RGB))
ax1.set_title('Original Image')
ax2.imshow(cv2.cvtColor(img_after, cv2.COLOR_BGR2RGB))
ax2.set_title('Adjusted Image')
plt.show()
원본

대비 증가

대비 감소 + 밝기 증가

밝기 증가

표현값(min, max) 제한

이산 푸리에 변환 (DFT)
Discrete Fourier Transform

푸리에 변환이란 시간이나 공간에 대한 함수를 주파수 성분으로 분해하는 변환을 이야기한다. 지난 수업들 중 음성 기술 수업에서 푸리에 변환을 통해 음성을 멜스펙토그램으로 변환하고, 이를 다시 복원하는 작업을 했었는데, 이미지에도 그러한 푸리에 변환을 적용할 수 있다.
음성에서는 푸리에 변환을 통해 시간의 흐름에 따른 각 주파수대의 값을 쉽게 볼 수 있었고,
이와 비슷하게 이미지에서는 푸리에 변환을 통해 각 픽셀의 밝기(intensity) 값의 변화를 변화를 쉽게 볼 수 있을 것이다.
즉, 이미지에서의 푸리에 변환을 쉽게 말하자면 “픽셀의 강도(=밝기) 변화를 주파수로 변환하는 것” 이라고 말할 수 있겠다.
음성을 푸리에 변환을 통해 멜스펙토그램으로 만들었을 때에는 그 위상을 잃는 문제가 있었다. 그리고 그 위상을 복원하는 게 바로 WaveGlow와 같은 Vocoder 즉, 음성 합성 모델이었다.
이미지에서는 blue, green, red 값을 각각 분리할 수 있고, 이 각각에 대한 푸리에 변환 또한 가능하다. 이 때문에 음성과는 달리 이미지는 푸리에변환 한 뒤 다시 컬러 이미지로 복원하는 데 큰 문제가 없을 것으로 예상된다. 이 점도 아래에서 공부를 진행하면서 알아보도록 하겠다.
- 음성 -> 멜스펙토그램 -> 음성
- 이미지 -> 푸리에스펙트럼 -> 이미지

채널 분리 (B, G, R)
이미지 밝기(intensity)에 대한 푸리에 변환을 진행할 때에는 이미지를 greyscale로 변환한 뒤 진행하게 된다. greyscale로의 변환을 하는 이유는
(1) greyscale로 변환하면 이미지가 단일 채널로 변경되면서 푸리에 변환을 쉽게 처리 할 수 있고,
(2) 밝기에 대한 푸리에 변환에서는 Blue, Green, Red 색상정보가 목적을 달성하기 위해 필수적이지 않기 때문이다.
하지만 바꿔 말하면 greyscale로 변환한 이미지는 단순히 픽셀의 밝기에 대한 값만을 가지고 있으며, 각 색상에 대한 분석은 어렵다고 할 수 있겠다.
그러면 여기서 든 생각. 각 채널을 분리한다면, 각 색상에 대한 푸리에 변환과 이를 통한 분석이 가능하지 않을까?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 이미지에서 특정 채널 값만을 가져오기
import cv2
import numpy as np
img = cv2.imread('/path/to/img.jpg')
img_green = []
for i, rows in enumerate(img):
temp_green = []
for j, pixel in enumerate(rows):
temp_green.append(pixel[1])
# blue : 0 / green : 1 / red : 2
img_green.append(temp_green)
img_green = np.array(img_green).astype(np.uint8)
이렇게 하면 green intensity만을 가져올 수 있다.
그리고, 각 채널값을 분리하는 기능을 cv2에서 제공함을 나중에야 알았다. (…)
1
2
3
4
5
6
7
8
# 이미지 각 채널 값 분리
import cv2
# Load image
img = cv2.imread('/path/to/img.jpg')
# Split the image into it's color channels
b, g, r = cv2.split(img)
각 채널값을 추출한 이미지, 그리고 greyscale 이미지를 만든 예시를 아래에 첨부한다.
이미지를 보면 각 color 별로 동일 픽셀간에 intensity가 다름을 볼 수 있다.
이를 통해 각 채널값을 추출하면, 각 색상 채널별로 분석과 이미지 처리가 가능할 것임을 짐작할 수 있었다.

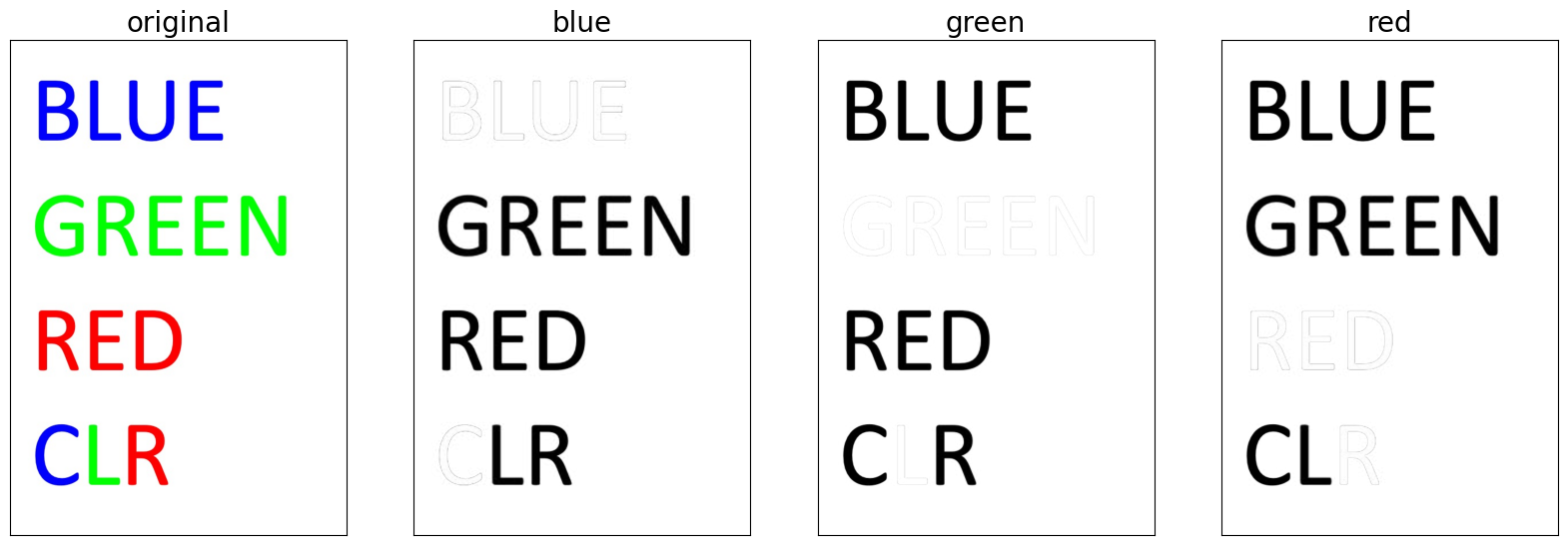
(두 번째 이미지에선 특정 채널값만 하얀색임을 볼 수 있다. 이는 해당 채널값의 intensity가 높으기 때문)
푸리에 변환
그러면 본격적으로 이미지에 대한 푸리에 변환을 진행해본다.
OpenCV에서 푸리에 변환은 cv2.~ft() 라는 메서드를 통해 손쉽게 접근할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import cv2
import matplotlib.pyplot as plt
import numpy as np
# 이미지 불러오기
img = cv2.imread('path/to/img', 0)
# 이미지를 float32로 변환하고, normalize 하기
f = np.fft.fft2(img)
fshift = np.fft.fftshift(f)
# fft를 한 fshift를 절대값처리한 뒤
# magnitude spectrum 으로 변경
magnitude_spectrum = 20 * np.log(np.abs(fshift))
img_list = [img, magnitude_spectrum]
img_name = ['origin', 'fourier']
plt.figure(figsize=(20,10))
for i, img in enumerate(img_list):
plt.subplot(int(f'12{i+1}'))
plt.title(img_name[i])
plt.imshow(img, cmap='gray')
plt.show()

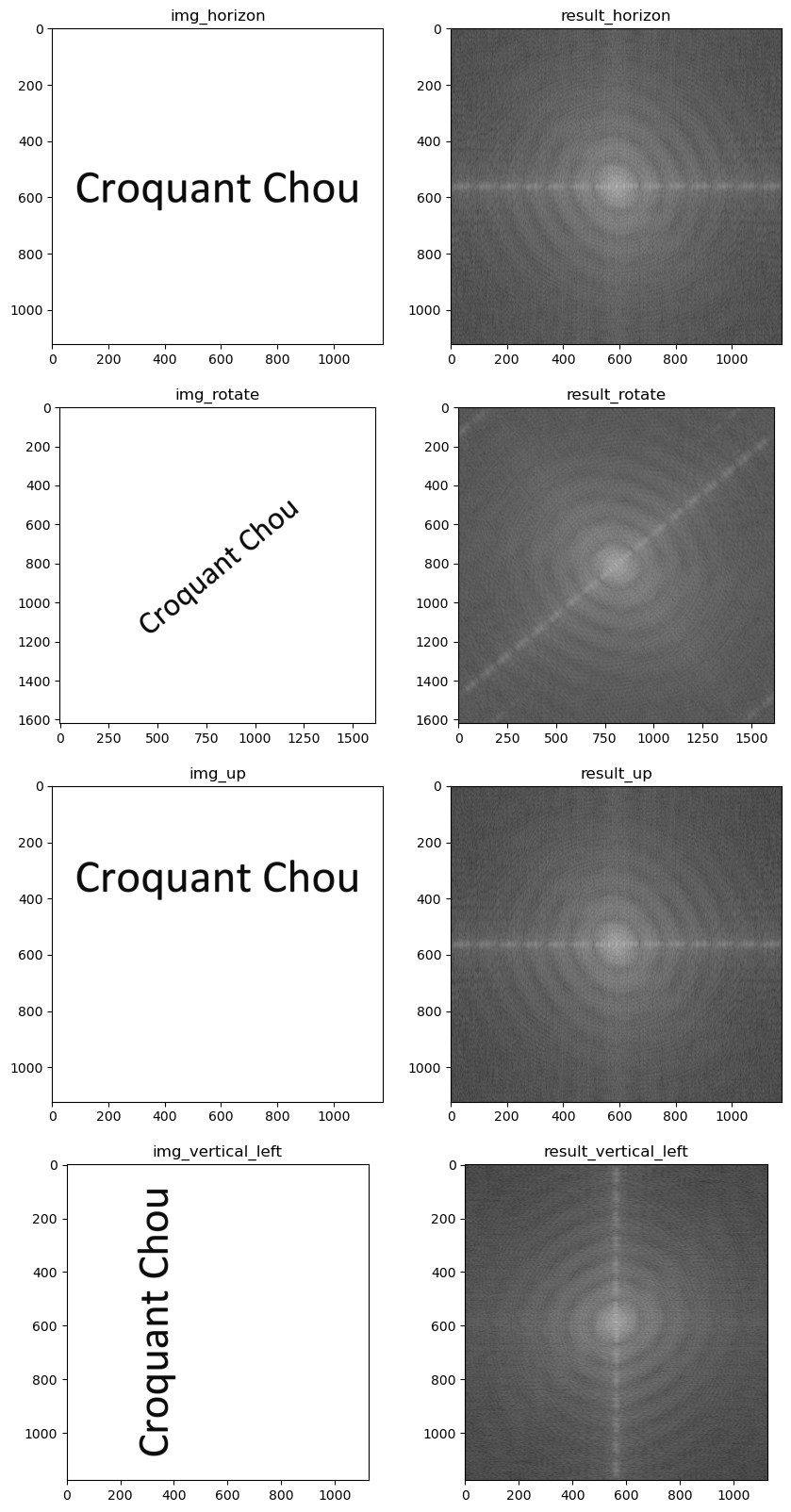
푸리에 변환을 통한 응용 예시1 : 텍스트 기울기 여부 판단
간단한 예를 들어, 텍스트가 쓰여진 이미지와 이를 회전시킨 이미지를 푸리에 변환해보겠다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
import cv2
import matplotlib.pyplot as plt
import numpy as np
def make_mag_spec(img):
f = np.fft.fft2(img)
fshift = np.fft.fftshift(f)
result = 20 * np.log(np.abs(fshift))
return result
img_horizon = cv2.imread('path/to/horizon_img', 0)
img_rotate = cv2.imread('path/to/rotate_img', 0)
# 줄임 : 등 4개 이미지...
result_horizon = make_mag_spec(img_horizon)
result_rotate = make_mag_spec(img_rotate)
# 줄임 : 등 4개 이미지...
img_list = [img_horizon, result_horizon, img_rotate,
result_rotate, img_up, result_up,
img_vertical_left, result_vertical_left]
title_list = ['img_horizon', 'result_horizon', 'img_rotate',
'result_rotate', 'img_up', 'result_up',
'img_vertical_left', 'result_vertical_left']
for i, img in eumerate(img_list):
plt.subplot(int(f'42{i+1}'))
plt.title(title_list[i])
plt.imshow(img, cmap='gray')
plt.show()
결과
카메라와 동영상 파일 다루기
OpenCV는 FFMPEG를 지원하기 때문에 AVI, MP4 등 다양한 형식의 동영상 파일을 취급할 수 있다.
| 지원하는 동영상 형식 | 확장자 |
|---|---|
| MPEG-4 Part 14 | MP4 |
| QuickTime Movie File Format | MOV |
| Matroska Multimedia Container | MKV |
| Audio Video Interleave | AVI |
| Flash Video | FLV |
| Windows Media Video | WMV |
| MPEG-2 Transport Stream | M2TS |
| MPEG-2 Program Stream | MPEG |
| Ogg Video | OGV |
| WebM |
동영상 읽어오기
OpenCV 의 cv2.VideoCapture() 메서드와 cv2.VideoCapture.read() 메서드를 통해 동영상을 읽어올 수 있다. 이렇게 읽어온 동영상 데이터는 많은 수의 이미지들로 이루어져 있으며, 이는 Frame이라고 한다. 읽어온 Frame을 연속적으로 보여줌으로써 움직이는 것 처럼 보이는 영상, 즉 동영상을 보여줄 수 있는 것이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import cv2
# 동영상파일의 정보 불러오기
path = "path/to/video.extension"
capture = cv2.VideoCapture(path)
while True:
# 로딩
ret, frame = capture.read()
# 동영상파일 정보의 ret과 frame을 읽어온다.
# ret : boolean 형. capture에서 정상적으로 프레임을 읽었는지 여부
# frame : 동양상 프레임
# 무결성 검사
if(capture.get(cv2.CAP_PROP_POS_FRAMES) == capture.get(cv2.CAP_PROP_FRAME_COUNT)):
capture.open(path)
# 현재 프레임 수(CAP_PROP_POS_FRAMES)와
# 총 프레임 수 (CAP_PROP_FRAME_COUNT)를 비교해
# 동일하다면 capture 변수에 동영상을 다시 할당한다.
# 동영상 재생
cv2.imshow("VideoFrame", frame)
if cv2.waitKey(capture.get(1000 / cv2.CAP_PROP_FPS)) == ord('q'):
break
# 각 frame을 cv2.imshow() 메서드를 통해 보여준다.
# cv2.waitKey(33) 으로 각 프레임을 보여준지 33ms이 지나면 현재 프레임을 끄고
# 다음 프레임(while 문)이 진행되게 한다.
# 동영상 종료
capture.release()
cv2.destroyAllWindows()
# 동영상이 끝나면 파일을 닫고 메모리를 해제한다.
동영상 읽어오기에서 사용된 메서드
위 코드에서 동영상을 읽어오는 데에는 8개의 관련 메서드와 2개의 관련 attribution이 활용되었다.
| 종류 | 이름 | 설명 |
|---|---|---|
| 메서드 | cv2.VideoCapture(동영상파일) | 동영상파일을 불러온다. |
| 메서드 | cv2.VideoCapture(동영상파일).get() | 동영상파일의 정보를 불러온다. |
| 메서드 | cv2.VideoCapture(동영상파일).read() | 동영상파일의 각 프레임 정보를 불러온다. .read()메서드가 사용될 때마다 순차적으로 프레임을 불러옴. ret : 정상적으로 프레임을 읽어왔는지 여부. boolean. frame : 읽어온 프레임(이미지) |
| 메서드 | cv2.VideoCapture(동영상파일).open() | 동영상파일을 불러와 메모리에 올린다. |
| 메서드 | cv2.imshow(“VideoFrame”, frame) | 각 프레임을 이미지로 보여준다. |
| 메서드 | cv2.waitKey(33) | 이미지(frame)을 보여준 후 33ms 후 닫는다. |
| 메서드 | cv2.VideoCapture(동영상파일).release() | 동영상 파일을 닫고 메모리를 해제한다. |
| 메서드 | cv2.destroyAllWindows() | 이미지를 보여준 모든 창을 닫는다. |
| 종류 | 이름 | 설명 |
|---|---|---|
| attribution | cv2.CAP_PROP_POS_FRAMES | 현재 frame이 몇 번째 frame인지 |
| attribution | cv2.CAP_PROP_FRAME_COUNT | 해당 동영상의 총 frame 개수 |
| attribution | cv2.CAP_PROP_FPS | Frame Per Second 초당 frame 수 |
cv2.VideoCapture()
cv2.VideoCapture() 메서드
동영상 파일을 cv.VideoCapture 오브젝트로 메모리에 올리는 것
1
2
3
4
5
6
7
8
import cv2
path = "path/to/video"
capture = cv2.VideoCapture(path)
print(capture)
# 출력값 : cv2.VideoCapture 0x132729eb0
# 설명 : cv2.VideoCapture 객체이며 메모리 주소값은 0x132729eb0
프레임 관련 속성 가져오기
cv2.VideoCapture().get() : 프레임 관련 정보 가져오는 메서드
cv2.CAP_PROP_POS_FRAMES : 현재 프레임 번호
cv2.CAP_PROP_FRAME_COUNT : 동영상의 총 프레임 수
1
2
3
4
5
6
7
8
9
import cv2
path = "path/to/video"
capture = cv2.VideoCapture(path)
print(f'현재 프레임 번호 : {capture.get(cv2.CAP_PROP_POS_FRAMES)}')
print(f'총 프레임 수 : {capture.get(cv2.CAP_PROP_FRAME_COUNT)}')
# 출력 : 현재 프레임 번호 : 0.0
# 출력 : 총 프레임 수 : 1007.0
cv2.VideoCapture().read()
동영상 파일의 각 프레임 정보를 불러온다.
ret : 현재 프레임이 정상적으로 불러와지는지 여부 Boolean
frame : 현재 프레임의 ndarray
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import cv2
import numpy as np
import matplotlib.pyplot as plt
path = "path/to/video"
capture = cv2.VideoCapture(path)
ttl_frame = capture.get(cv2.CAP_PROP_FRAME_COUNT)
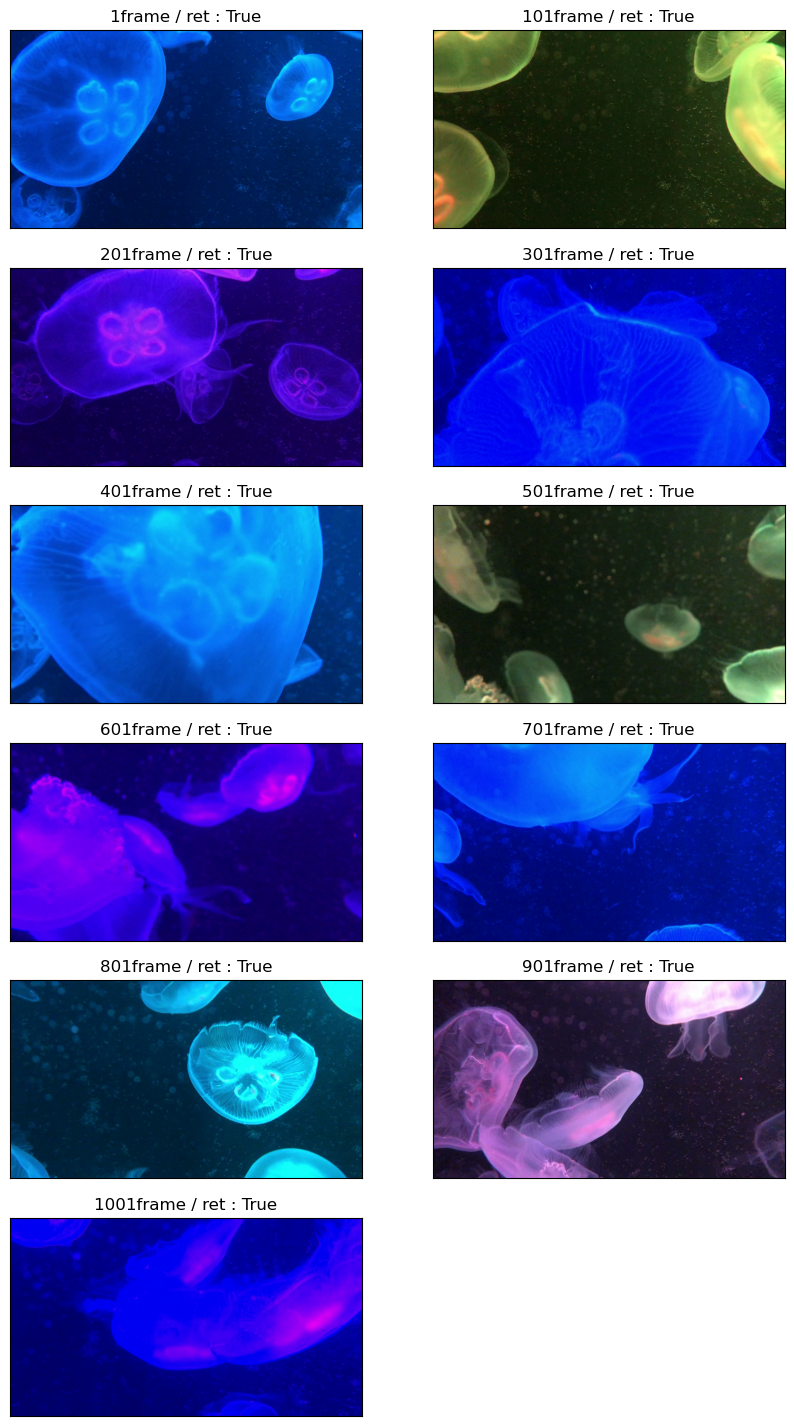
for i in range(int(ttl_frame)): # 총 프레임을 순환하면서
ret, frame = capture.read() # 프레임을 불러온다.
if(i % 100) == 0: # 100번째 마다의 프레임만 표현
plt.subplot(int(ttl_frame)//200 + 1, 2, i // 100 + 1)
plt.imshow(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
plt.title(f'{i+1}frame / ret : {ret}')
plt.show()
FPS
Frame Per Second. 초당 프레임 수이다.
예를 들어, 1000 프레임짜리 동영상을 FPS 25로 설정하면 총 동영상 플레이타임은 40초가 된다.
- FPS = 1000 / interval(ms)
- interval = 1000 / FPS
1
2
3
4
5
6
7
import cv2
path = "path/to/video"
capture = cv2.VideoCapture(path)
print(capture.get(cv2.CAP_PROP_FPS))
# 출력값 : 30.00595947556615
동영상 재생
무결성 검사를 하지 않는다면, 아래와 같이 동영상을 읽어와 재생할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import cv2
import numpy as np
import matplotlib.pyplot as plt
path = "path/to/video"
capture = cv2.VideoCapture(path)
ttl_frame = capture.get(cv2.CAP_PROP_FRAME_COUNT)
fps = capture.get(cv2.CAP_PROP_FPS)
for i in range(int(ttl_frame)):
ret, frame = capture.read()
if ret ==True:
cv2.imshow("VideoFrame", frame)
if cv2.waitKey(int(1000//fps)) == ord('q'):
# 1000//fps 만큼 프레임 간 interval을 가지고 재생
break
capture.release()
cv2.destroyAllWindows()
동영상 크기 조절
카메라 출력
저장된 이미지나 동영상 파일이 아니라 카메라를 통해 동영상(영상)을 실시간으로 받아 처리하기 위해 사용. 카메라를 사용하는 방법은 위 동영상 재생과 방법은 동일하며, 대상 자료 경로를 ‘0’으로 설정해주면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import cv2
capture = cv2.VideoCapture(0)
capture.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
capture.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
fps = capture.get(cv2.CAP_PROP_FPS)
while True:
ret, frame = capture.read()
if ret == True:
cv2.imshow("VideoFrame", frame)
if cv2.waitKey(int(1000/fps)) == ord('q'):
break
else:
break
capture.release()
cv2.destroyAllWindows()
사용된 주요 메서드 및 attribution
| 종류 | 이름 | 설명 |
|---|---|---|
| 메서드 | cv2.VideoCapture(0) | 0번 소스(웹캠) 로부터 동영상을 받아온다. |
| 메서드 | cv2.VideoCapture().set() | 동영상 관련 여러 정보(크기 등)를 제어한다. |
| attribution | cv2.CAP_PROP_FRAME_WIDTH | 동영상의 가로 길이(폭) |
| attribution | cv2.CAP_PROP_FRAME_HEIGHT | 동영상의 세로 길이(높이) |
| 그 외는 위 동영상 읽어오기 부분 참고 |
동영상 저장(쓰기)
이미지를 묶어서 동영상으로 저장하는 것은 cv2.VideoWriter() 메서드를 이용한다.
아래에서 카메라를 통해 들어온 영상(동영상) 정보를 토대로, 이를 녹화해보는 실습을 한다.
| 메서드 | 파라미터 | 설명 |
|---|---|---|
| cv2.VideoWriter() | filename | 동영상 파일을 저장할 경로명. 확장자 포함. |
| fourcc | 코덱. 확장자에 맞는 코덱 선택 필요. 하단 참조 | |
| fps | 초당 프레임 수 | |
| framesize | 동영상 크기. (width, height) 튜플 형식으로 제공 | |
| isColor | True/False. 컬러로 저장할지 여부 |
| fourcc 포맷 | 확장자 | 설명 |
|---|---|---|
| *‘mp4v’ | .mp4 | |
| *‘h264’ | .mp4 | |
| .mov | ||
| .avi | ||
| *‘hevc’ | .mp4 | |
| .mkv | ||
| *‘mpeg-4’ | .mp4 | |
| .mov |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
import cv2
# 동영상 입력 : 웹캡 video capture
capture = cv2.VideoCapture(0)
# Frame 의 width / height 선언
# width = int(capture.get(cv2.CAP_PROP_FRAME_WIDTH)) # webcam 스펙에 맞춰
# height = int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT)) # webcam 스펙에 맞춰
# # width = 640
# # height = 480 와 같이 직접 선언도 가능
width = 500
height = 500
# Frame 의 width / height 세팅
capture.set(cv2.CAP_PROP_FRAME_WIDTH, width)
capture.set(cv2.CAP_PROP_FRAME_HEIGHT, height)
# 저장 경로 설정
path = "/Users/jongya/Desktop/test.mp4"
# FPS 설정
fps = capture.get(cv2.CAP_PROP_FPS) # webcam 스펙에 맞춰
# fps = 10 와 같이 직접 선언도 가능
# Codec 설정
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
# VideoWriter 객체 선언
out = cv2.VideoWriter(path, fourcc, int(fps), (width, height), True)
# 동영상파일을 만드는 VideoWirter 객체 선언
# 설정값을 videoWriter 객체에 저장
# 웹캠의 frame 들을 동영상파일로 저장
while True:
ret, frame = capture.read()
if ret == True:
cv2.imshow("VideoFrame", frame)
cv2.waitKey(int(1000/fps))
# 프레임을 동영상에 추가
out.write(frame)
if cv2.waitKey(int(1000/fps)) == ord('q'):
break
# VideoWriter 객체 종료 (파일 저장 및 종료)
out.release()
capture.release()
cv2.destroyAllWindows()
그리기 Drawing functions
선 Drawing Line
기타 참고
Pixel 픽셀
Reference
- 푸리에 변환 : https://ko.wikipedia.org/wiki/%ED%91%B8%EB%A6%AC%EC%97%90_%EB%B3%80%ED%99%98
Comments