
- 데이터프레임을 특정 파일로 저장 : DF.to_파일형식()
-
인덱스 없애기 : DF.to_파일형식(index=False)
- NA 값이 있는 열 제거 : DF.dropna(axis=1)
- NA 값이 있는 행 제거 : DF.dropna(axis=0)
-
NA 값이 있는 열과 행 제거 : DF.dropna()
- 특정 칼럼 제거 : DF.drop(columns=[칼럼명들], inplace=Bool) : inplace = 본 데이터프레임에 덮어쓰기
-
특정 행 제거 : DF.drop(index=[인덱스], inplace=Boo;) : inplace = 본 데이터프레임에 덮어쓰기
- 인덱스 재설정 : DF.reset_index(drop=Bool, inplace=Bool) : drop = 기존 인덱스 삭제, inplace = 본 데이터프레임에 덮어쓰기
Pandas
- python data analysis 의 약자
- DataFrame이라는 테이블(표) 형식의 자료 형식을 사용한다.
- DataFrame은 여러 열이 하나의 테이블을 이루는 데이터 구조.
- 하나의 열은 시리즈(Series)라고 부름
- Series와 DataFrame의 각 열에는 Index가 매겨진다.
- value가 행렬 형식이기 때문에 numpy로 연산이 가능
- 정형 데이터 처리에 특화된 라이브러리
판다스를 쉽게 설명하자면, “파이썬에서 사용하는 엑셀” 이라고 할 수 있습니다.
대표적 메서드
데이터프레임 만들기
| 메서드명 | 설명 | 파라미터 |
|---|---|---|
| df = pandas.DataFrame(data, index, columns, dtype, copy) | df라는 변수에 DataFrame 형식 Object 생성 | data : 데이터프레임화 할 값 index : 행(시리즈)의 제목을 지정 columns : 열의 제목을 지정 dtype : value의 데이터타입을 지정 copy : value를 복사본으로 사용할지 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import pandas as pd
import random
ls_list = []
for i in range(5): # 데이터프레임화 할 값 리스트 만들기
ls = []
for j in range(3):
ls.append(random.randint(0, 10))
ls.list.append(ls)
print(ls_list) # 데이터프레임화 할 값
# >>> [[9, 4, 5], [5, 7, 3], [9, 6, 0], [2, 10, 1], [4, 9, 1]]
df = pd.DataFrame(data = ls_list, # 데이터프레임화
index = ["첫번째","두번째","세번째","네번째","다섯번째"],
columns = ["1열","2열","3열"],
dtype = float)
print(df)
# >>> 1열 2열 3열
# >>> 첫번째 9.0 4.0 5.0
# >>> 두번째 5.0 7.0 3.0
# >>> 세번째 9.0 6.0 0.0
# >>> 네번째 2.0 10.0 1.0
# >>> 다섯번째 4.0 9.0 1.0
위에 이어서 copy 파라미터의 예시는 아래와 같습니다.
정리하자면 copy = False (기본 세팅) 이면 원본값 변경에 따름,
copy = True 면 복사본을 사용하므로 원본값에 영향을 받지 않음.
으로 말할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
import pandas as pd
import numpy as np
arr = np.random.randint(10, size=(2, 2)) # 2 X 2 랜덤 행렬
df_nocopy = pd.DataFrame(arr, copy=False) # copy = False
df_copy = pd.DataFrame(arr, copy=True) # copy = True
df_default = pd.DataFrame(arr) # default 기본
arr[0,0] = 1000 # 행렬의 첫값을 1000으로 변경
print(df_nocopy) # 원본값이 변경되면 DataFrame 값도 변경
# >>> 0 1
# >>> 0 1000 6
# >>> 1 0 0
print(df_copy) # 원본값이 변경되어도 불변
# >>> 0 1
# >>> 0 0 6
# >>> 1 0 0
print(df_default) # 기본 세팅은 copy = False
# >>> 0 1
# >>> 0 1000 6
# >>> 1 0 0
하지만 list 를 원본으로 하는 경우, copy 파라미터는 의미가 없습니다.
이는 list 의 mutable 성질로 인해, copy = False 를 사용하더라도 DataFrame은 원본 데이터를 보호하기 위해 내부적으로 복사(copy)를 수행하기 때문입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import pandas as pd
ls_list = [[9, 10, 5], [5, 7, 3], [9, 6, 0]]
df_copy = pd.DataFrame(ls_list, copy=True)
df_nocopy = pd.DataFrame(ls_list, copy=False)
ls_list[0][0] = 1000
print(df_copy)
# >>> 0 1 2
# >>> 0 9 10 5
# >>> 1 5 7 3
# >>> 2 9 6 0
print(df_nocopy)
# >>> 0 1 2
# >>> 0 9 10 5
# >>> 1 5 7 3
# >>> 2 9 6 0
파일 읽기
판다스는 테이블 형식의 외부 파일을 불러들여와 DataFrame 형태로 만들 수 있습니다.
| 메서드명 | 설명 | 예시 |
|---|---|---|
| pandas.read_csv(path) | csv 형식의 자료를 데이터프레임으로 읽어들임 | df = pandas.read_csv(path) |
| pandas.read_excel(path) | excel 형식의 자료(.xls, .xlsx)를 데이터프레임으로 읽어들임 | df = pandas.read_excel(path) |
| pandas.read_json(path) | json 형식의 자료(.json)를 데이터프레임으로 읽어들임 | df = pandas.read_json(path) |
| pandas.read_sql(path) | sql 형식의 자료를 읽어들임 | df = pandas.read_sql(path) |
외부에 아래와 같은 엑셀파일을 판다스로 불러와보겠습니다.
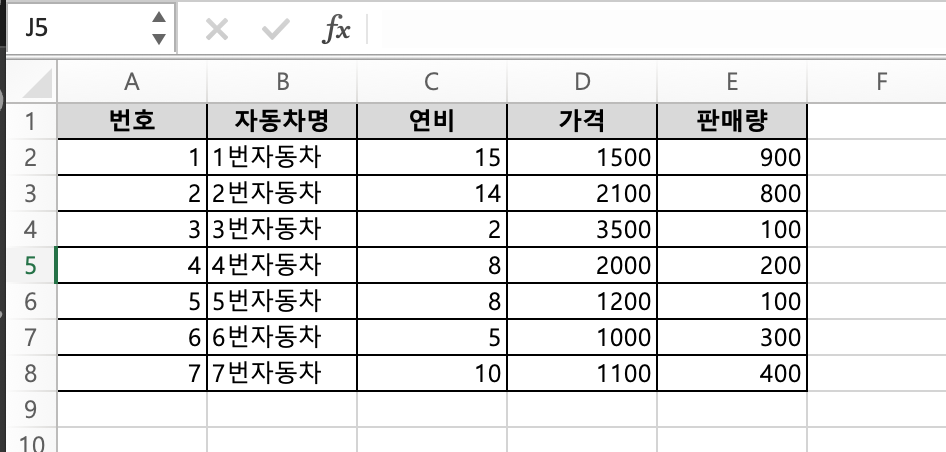 .{width=300px;}
.{width=300px;}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import pandas as pd
import openpyxl
path = "./car.xlsx"
df = pd.read_excel(path)
print(df)
# >>> 번호 자동차명 연비 가격 판매량
# >>> 0 1 1번자동차 15 1500 900
# >>> 1 2 2번자동차 14 2100 800
# >>> 2 3 3번자동차 2 3500 100
# >>> 3 4 4번자동차 8 2000 200
# >>> 4 5 5번자동차 8 1200 100
# >>> 5 6 6번자동차 5 1000 300
# >>> 6 7 7번자동차 10 1100 400
openpyxl 은 xlsx 형식을 다루기 위한 의존성 라이브러리입니다. 보여주기위해 import 했을 뿐, 판다스 내부에서 import 하기 때문에 실제 사용시에는 import를 하지 않아도 됩니다.
데이터프레임 정보 (조회)
df 는 데이터프레임 Object를 뜻합니다.
| 메서드명 | 설명 |
|---|---|
| df.head(n) | 데이터프레임의 처음부터 n번째 행까지 반환 |
| df.tail(n) | 데이터프레임의 마지막 n개 행의 내용 반환 |
| df.sample(n) | 데이터프레임에서 n개의 랜덤 자료를 반환 |
| df.info() | 데이터에 대한 전체적인 요약정보 |
| df.describe() | 데이터에 대한 전체적인 통계정보 |
| df.index | 데이터프레임의 인덱스를 반환 |
| df.columns | 데이터프레임의 열 제목을 반환 |
| df.keys() | 상동 |
| df.values | 데이터의 value 를 반환 |
| df.dtypes | 데이터타입을 반환 |
| df.size | value의 개수를 반환 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 살펴보기
import pandas as pd
path = "./car.xlsx"
df = pd.read_excel(path)
print(df.head(2))
# >>> 번호 자동차명 연비 가격 판매량
# >>> 0 1 1번자동차 15 1500 900
# >>> 1 2 2번자동차 14 2100 800
print(df.tail(2))
# >>> 번호 자동차명 연비 가격 판매량
# >>> 5 6 6번자동차 5 1000 300
# >>> 6 7 7번자동차 10 1100 400
print(df.sample(2))
# >>> 번호 자동차명 연비 가격 판매량
# >>> 5 6 6번자동차 5 1000 300
# >>> 2 3 3번자동차 2 3500 100
다음은 info와 describe 입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# info, describe
import pandas as pd
path = "./car.xlsx"
df = pd.read_excel(path)
print(df.info())
# >>> <class 'pandas.core.frame.DataFrame'>
# >>> RangeIndex: 7 entries, 0 to 6
# >>> Data columns (total 5 columns):
# >>> # Column Non-Null Count Dtype
# >>> --- ------ -------------- -----
# >>> 0 번호 7 non-null int64
# >>> 1 자동차명 7 non-null object
# >>> 2 연비 7 non-null int64
# >>> 3 가격 7 non-null int64
# >>> 4 판매량 7 non-null int64
# >>> dtypes: int64(4), object(1)
# >>> memory usage: 408.0+ bytes
# >>> None
print(df.describe())
# >>> 번호 연비 가격 판매량
# >>> count 7.000000 7.000000 7.000000 7.000000
# >>> mean 4.000000 8.857143 1771.428571 400.000000
# >>> std 2.160247 4.634241 875.051019 326.598632
# >>> min 1.000000 2.000000 1000.000000 100.000000
# >>> 25% 2.500000 6.500000 1150.000000 150.000000
# >>> 50% 4.000000 8.000000 1500.000000 300.000000
# >>> 75% 5.500000 12.000000 2050.000000 600.000000
# >>> max 7.000000 15.000000 3500.000000 900.000000
index, column 등 구조적인 정보를 볼 수도 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 구조적인 정보
import pandas as pd
path = "./car.xlsx"
df = pd.read_excel(path)
print(df.index)
# >>> RangeIndex(start=0, stop=7, step=1)
print(df.columns)
# >>> Index(['번호', '자동차명', '연비', '가격', '판매량'], dtype='object')
print(df.values)
# >>> [[1 '1번자동차' 15 1500 900]
# >>> [2 '2번자동차' 14 2100 800]
# >>> [3 '3번자동차' 2 3500 100]
# >>> [4 '4번자동차' 8 2000 200]
# >>> [5 '5번자동차' 8 1200 100]
# >>> [6 '6번자동차' 5 1000 300]
# >>> [7 '7번자동차' 10 1100 400]]
print(df.dtypes)
# >>> 번호 int64
# >>> 자동차명 object
# >>> 연비 int64
# >>> 가격 int64
# >>> 판매량 int64
# >>> dtype: object
print(df.size)
# >>> 35
저장
데이터프레임은 테이블 형식의 외부 자료형으로 저장할 수 있습니다.
df 는 데이터프레임 Object를 뜻합니다.
| 메서드명 | 설명 |
|---|---|
| df.to_csv(path) | csv 형식으로 저장 |
| df.to_excel(path) | 엑셀 형식으로 저장 |
| df.to_json(path) | json 형식으로 저장 |
1
2
3
4
5
6
7
8
9
10
import pandas as pd
path = "./car.xlsx"
df = pd.read_excel(path)
export_path = "./car_export"
df.to_csv(export_path + ".csv")
df.to_excel(export_path + ".xlsx")
df.to_json(export_path + ".json")
json 형태는 아래와 같이 저장됩니다.
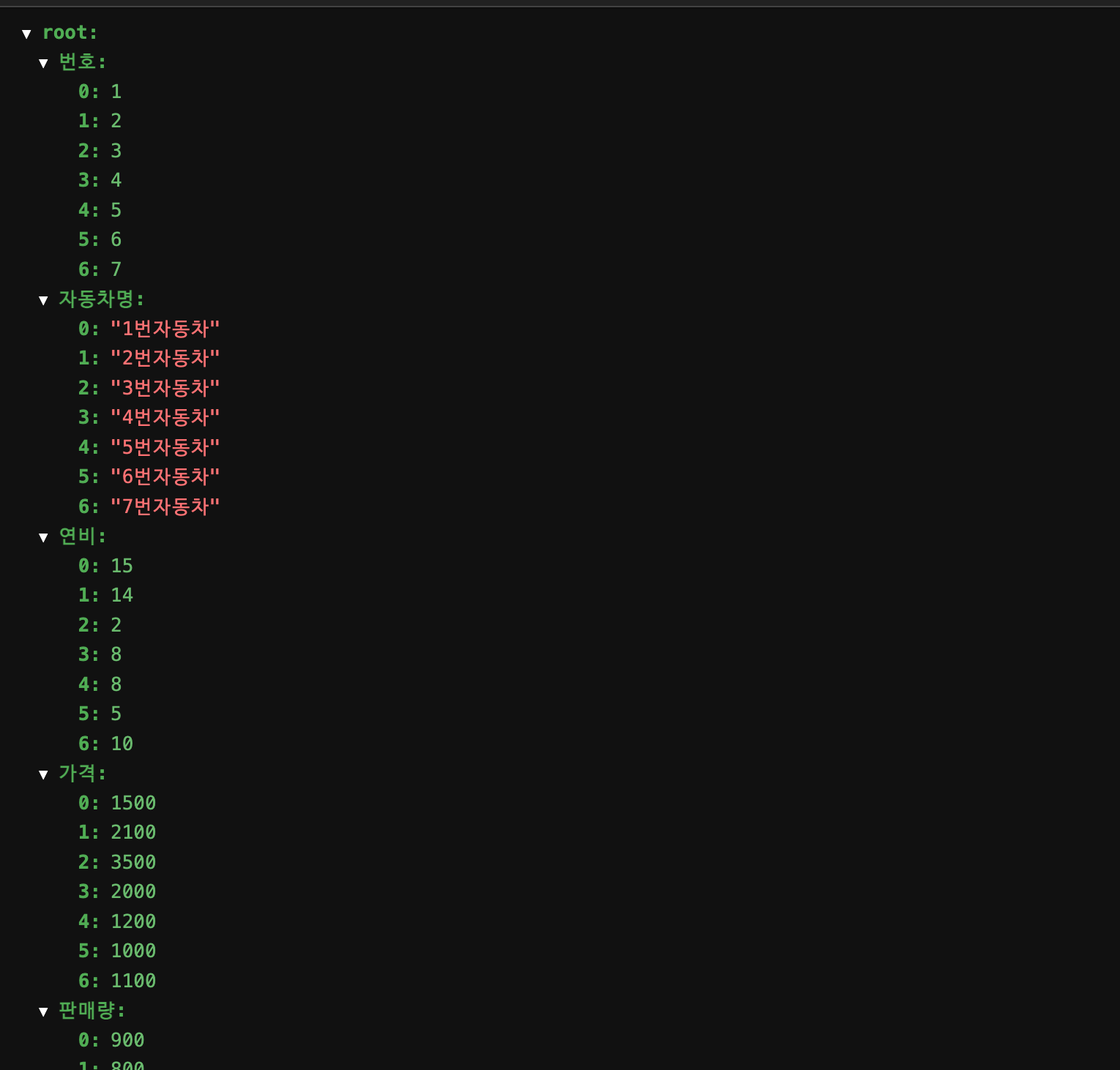
행 또는 열 선택하기
데이터프레임의 특정 행 또는 열을 선택하는 방식은 아래와 같습니다.
df 는 데이터프레임 Object를 뜻합니다.
| 메서드 | 설명 | 비고 |
|---|---|---|
| df[“컬럼명”] | 데이터프레임의 특정 컬럼 내용을 반환 | 컬럼 선택 |
| df[[“컬럼명1”, “컬럼명2”]] | 다수의 컬럼 내용을 반환 | 컬럼 선택 |
| df.loc[n] | 데이터프레임의 n 번째 행 내용을 반환 | 행 선택 |
| df.loc[start:end] | loc는 슬라이싱도 가능 | 행 선택 |
| df.iloc[n] | 데이터프레임의 n 번째 열 내용을 반환 | 행 선택 |
| df.iloc[start:end] | iloc 또한 슬라이싱 가능 | 행 선택 |
| df[df[n] == 값 | 데이터프레임 중 특정 조건을 만족하는 내용 반환 | 조건 |
먼저, 이번에는 loc와 iloc의 차이를 보기 위해 인덱스값을 별도로 준 데이터프레임을 생성하겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import pandas as pd
import numpy as np
ls_columns = ["1번열", "2번열", "3번열", "4번열"]
ls_indices = ["1번", "2번", "3번", "4번", "5번"]
value_arry = np.random.randint(10, size=(5, 4))
df = pd.DataFrame(value_arry, columns = ls_columns,
index = ls_indices, copy = True)
print(df)
# >>> 1번열 2번열 3번열 4번열
# >>> 1번 7 0 0 1
# >>> 2번 1 7 4 7
# >>> 3번 0 9 6 0
# >>> 4번 3 0 7 1
# >>> 5번 5 4 1 5
여기에서 특정 컬럼을 선택할 때에는 [“컬럼명”] 과 같이 명시해주면 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
print(df["1번열"]) # 하나의 컬럼
# >>> 1번 7
# >>> 2번 1
# >>> 3번 0
# >>> 4번 3
# >>> 5번 5
# >>> Name: 1번열, dtype: int64
print(df[["1번열", "4번열"]]) # 다수의 컬럼
# >>> 1번열 4번열
# >>> 1번 7 1
# >>> 2번 1 7
# >>> 3번 0 0
# >>> 4번 3 1
# >>> 5번 5 5
loc와 iloc는 모두 “행”을 선택할 때 사용합니다.
차이점으로는 loc는 행의 이름을, iloc는 행의 번호를 이용한다는 점이 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# /==== loc ====/
print(df.loc["3번"])
# >>> 1번열 0
# >>> 2번열 9
# >>> 3번열 6
# >>> 4번열 0
# >>> Name: 3번, dtype: int64
print(df.loc[["3번", "4번"]])
# >>> 1번열 2번열 3번열 4번열
# >>> 3번 0 9 6 0
# >>> 4번 3 0 7 1
# /==== iloc ====/
print(df.iloc[2])
# >>> 1번열 0
# >>> 2번열 9
# >>> 3번열 6
# >>> 4번열 0
# >>> Name: 3번, dtype: int64
print(df.iloc[2:4])
# >>> 1번열 2번열 3번열 4번열
# >>> 3번 0 9 6 0
# >>> 4번 3 0 7 1
특정 조건을 만족하는 행 또는 열, 혹은 값을 반환받거나 조건을 만족하는지 여부를 알 수도 있습니다.
1
2
3
4
5
6
7
8
9
10
11
print(df[df["2번열"] > 5])
# >>> 1번열 2번열 3번열 4번열
# >>> 2번 1 7 4 7
# >>> 3번 0 9 6 0
print(df.loc["1번"] == 0)
# >>> 1번열 False
# >>> 2번열 True
# >>> 3번열 True
# >>> 4번열 False
# >>> Name: 1번, dtype: bool
통계값
평균, 합, 중앙값, 사분위수 등의 통계값을 얻을 수도 있습니다.
위에서 살펴본 describe를 통해 전체적인 통계값을 얻을 수 있었다면, 좀 더 세부적인 통계를 얻는 것은 아래의 메서드들을 사용합니다.
df 는 데이터프레임 Object를 뜻합니다.
| 메서드 | 설명 |
|---|---|
| df.sum() | 합을 반환 |
| df.max() | 최대값을 반환 |
| df.min() | 최소값을 반환 |
| df.mean() | 평균값을 반환 |
| df.mode() | 최빈값을 반환 |
| df.std() | 표준편차를 반환 |
| df.var() | 분산을 반환 |
| df.median() | 중앙값을 반환 |
| df.quantile() | 분위수를 반환 |
| 그 외 다수 |
아래와 같이 사용할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
import pandas as pd
import numpy as np
ls_columns = ["1번열", "2번열", "3번열", "4번열"]
ls_indices = ["1번", "2번", "3번", "4번", "5번"]
value_arry = [[7, 0, 0, 1], [1, 7, 4, 7], [0, 9, 6, 0], [3, 0, 7, 1], [5, 4, 1, 5]]
df = pd.DataFrame(value_arry, columns = ls_columns, index = ls_indices, copy = True)
print(df)
# >>> 1번열 2번열 3번열 4번열
# >>> 1번 7 0 0 1
# >>> 2번 1 7 4 7
# >>> 3번 0 9 6 0
# >>> 4번 3 0 7 1
# >>> 5번 5 4 1 5
print(df.sum())
# >>> 1번열 16
# >>> 2번열 20
# >>> 3번열 18
# >>> 4번열 14
# >>> dtype: int64
print(df["1번열"].sum())
# >>> 16
print(df[df["2번열"] == 0].sum()) # 조건을 줄 수도 있음
# >>> 1번열 10
# >>> 2번열 0
# >>> 3번열 7
# >>> 4번열 2
# >>> dtype: int64
그 외 동일하므로 빠르게 패스
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
print(df.max()) # 최대값
# >>> 1번열 7
# >>> 2번열 9
# >>> 3번열 7
# >>> 4번열 7
# >>> dtype: int64
print(df.min()) # 최소값
# >>> 1번열 0
# >>> 2번열 0
# >>> 3번열 0
# >>> 4번열 0
# >>> dtype: int64
print(df.mean()) # 평균값
# >>> 1번열 3.2
# >>> 2번열 4.0
# >>> 3번열 3.6
# >>> 4번열 2.8
# >>> dtype: float64
print(df["2번열"].mode()) # 최빈값 (가장 많이 등장하는 값)
# >>> 0
한 박자 쉬고
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
print(df.std()) # 표준편차
# >>> 1번열 2.863564
# >>> 2번열 4.062019
# >>> 3번열 3.049590
# >>> 4번열 3.033150
# >>> dtype: float64
print(df.var()) # 분산
# >>> 1번열 8.2
# >>> 2번열 16.5
# >>> 3번열 9.3
# >>> 4번열 9.2
# >>> dtype: float64
print(df.median()) # 중앙값
# >>> 1번열 3.0
# >>> 2번열 4.0
# >>> 3번열 4.0
# >>> 4번열 1.0
# >>> dtype: float64
print(df.quantile()) # 분위수 / 미지정시 등분
# >>> 1번열 3.0
# >>> 2번열 4.0
# >>> 3번열 4.0
# >>> 4번열 1.0
# >>> Name: 0.5, dtype: float64
print(df.quantile(0.25))
# >>> 1번열 1.0
# >>> 2번열 0.0
# >>> 3번열 1.0
# >>> 4번열 1.0
# >>> Name: 0.25, dtype: float64
그룹화, 통계
그룹바이.. 피벗..
| 메서드 | 설명 | 파라미터 |
|---|---|---|
| df.groupby() | 데이터프레임 그룹화 연산 | by : 그룹화할 기준. index, column 등 axis , leve 등은 생략 |
실습을 위한 데이터프레임을 만듭니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 데이터프레임 만들기
import pandas as pd
df = pd.read_excel("./car.xlsx")
print(df)
# >>> 번호 자동차명 연비 가격 판매량 종류 제조사
# >>> 0 1 1번자동차 15 1500 900 소형 A사
# >>> 1 2 2번자동차 14 2100 800 소형 D사
# >>> 2 3 3번자동차 2 3500 100 대형 A사
# >>> 3 4 4번자동차 8 2000 200 중형 A사
# >>> 4 5 5번자동차 8 1200 100 중형 B사
# >>> 5 6 6번자동차 5 1000 300 대형 C사
# >>> 6 7 7번자동차 10 1100 400 중형 B사
기본적인 groupby를 해보겠습니다.
특정 칼럼의 value 중 같은 값끼리 묶어 데이터프레임을 다시 보여줍니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
print(df.groupby("제조사").count()) # 제조사로 묶음
# >>> 번호 자동차명 연비 가격 판매량 종류
# >>> 제조사
# >>> A사 3 3 3 3 3 3
# >>> B사 2 2 2 2 2 2
# >>> C사 1 1 1 1 1 1
# >>> D사 1 1 1 1 1 1
print(df.groupby(["제조사","종류"]).count()) # 제조사와 종류로 묶음
# >>> 번호 자동차명 연비 가격 판매량
# >>> 제조사 종류
# >>> A사 대형 1 1 1 1 1
# >>> 소형 1 1 1 1 1
# >>> 중형 1 1 1 1 1
# >>> B사 중형 2 2 2 2 2
# >>> C사 대형 1 1 1 1 1
# >>> D사 소형 1 1 1 1 1
print(df.groupby(["제조사","종류","자동차명"]).mean()) # 평균값
# >>> 번호 연비 가격 판매량
# >>> 제조사 종류 자동차명
# >>> A사 대형 3번자동차 3.0 2.0 3500.0 100.0
# >>> 소형 1번자동차 1.0 15.0 1500.0 900.0
# >>> 중형 4번자동차 4.0 8.0 2000.0 200.0
# >>> B사 중형 5번자동차 5.0 8.0 1200.0 100.0
# >>> 7번자동차 7.0 10.0 1100.0 400.0
# >>> C사 대형 6번자동차 6.0 5.0 1000.0 300.0
# >>> D사 소형 2번자동차 2.0 14.0 2100.0 800.0
사칙연산
안에 있다 없다 같다(이퀄즈) 비교(컴페어) 엔유니크 덧셈 뺄셈 곱셉 나눅셈 나머지 거듭제곱 행렬곲
구조적 변환, 가공
인서트 팝 드롭 카피 드롭듀플리케이트 리플레이스 트랜스폼 트랜스포즈
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# drop : 행 또는 열을 삭제
import pandas as pd
df = pd.read_excel("./car.xlsx")
print(df)
# >>> 번호 자동차명 연비 가격 판매량 종류 제조사
# >>> 0 1 1번자동차 15 1500 900 소형 A사
# >>> 1 2 2번자동차 14 2100 800 소형 D사
# >>> 2 3 3번자동차 2 3500 100 대형 A사
# >>> 3 4 4번자동차 8 2000 200 중형 A사
# >>> 4 5 5번자동차 8 1200 100 중형 B사
# >>> 5 6 6번자동차 5 1000 300 대형 C사
# >>> 6 7 7번자동차 10 1100 400 중형 B사
print(df.drop(index=[0, 1, 2, 5]))
#### 0, 1, 2, 5 번째 index 를 삭제
# >>> 번호 자동차명 연비 가격 판매량 종류 제조사
# >>> 3 4 4번자동차 8 2000 200 중형 A사
# >>> 4 5 5번자동차 8 1200 100 중형 B사
# >>> 6 7 7번자동차 10 1100 400 중형 B사
print(df.drop(columns=["제조사","판매량","자동차명"]))
# >>> 번호 연비 가격 종류
# >>> 0 1 15 1500 소형
# >>> 1 2 14 2100 소형
# >>> 2 3 2 3500 대형
# >>> 3 4 8 2000 중형
# >>> 4 5 8 1200 중형
# >>> 5 6 5 1000 대형
# >>> 6 7 10 1100 중형
NA 값 관련
드롭엔에이 이즈인
??
아이템즈
값 이용하기
조인 키스 밸류스 라인드 리플레이스 솔트
인덱스
셋인덱스
Reference
SeSAC 수업
pandas DOC : https://pandas.pydata.org/docs/
https://wikidocs.net/151329
Comments