
TF-IDF
정의
- 단순 빈도 뿐만 아니라, 그 단어가 전체 문서 집합에서 얼마나 희귀하게 나타나는지를 함께 고려해 단어의 중요도를 측정하고, 이를 바탕으로 텍스트를 벡터로 변환하는 것.
만드는 방법
- TF 와 IDF 의 곱으로 계산한다.
- TF : Term Frequency(용어 빈도). 문서 내 단어 빈도를 비율로 나타낸 것.
- DF : Document Frequency(문서 빈도). 특정 단어가 포함된 문서의 빈도를 비율로 나타낸 것.
- IDF : Inverse Document Frequency(역문서 빈도). DF의 역분. 특정 단어가 포함된 문서의 수가 작을수록 증가한다.
- 예시 : 단어 A가 B문서에서 다른 단어에 비해 많이 등장하면서, A단어를 포함하는 다른 문서의 수가 적을수록 B 문서에서 A 단어에 대한 TF-IDF 값이 증가한다.
계산식
(1) TF (Term Frequency)
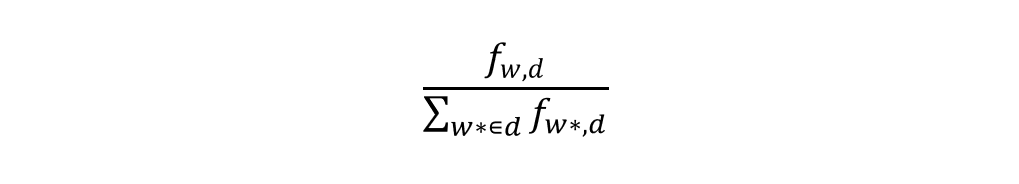
TF(w,d): 문서 d의 모든 단어 등장 빈도 중 w의 등장 빈도 비율f(w,d): 단어 w가 문서 d에 실제로 등장한 횟수 (w의 절대 빈도)- 분모항 : 문서 d에서 등장하는 모든 단어의 등장 횟수 합
(2) IDF (Inverse Document Frequency)
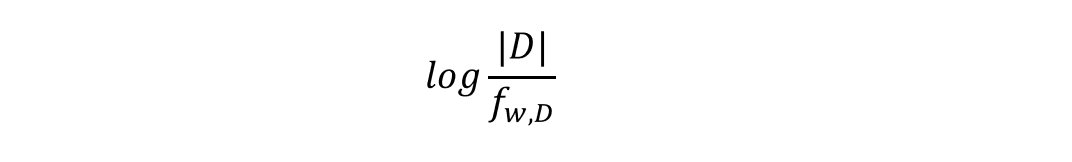
IDF(w): 단어 w가 전체 문서 집합(corpus) D에서 얼마나 희귀하게 나타나는지의 정도|D|: corpus 안의 전체 문서의 개수f(w,D): corpus 안에서 단어 w를 포함하는 문서의 개수- 희귀한 단어일수록 값이 높아져 중요도가 올라간다.
- 값의 변별력을 높이기 위해 log를 취한다.
(3) TF-IDF
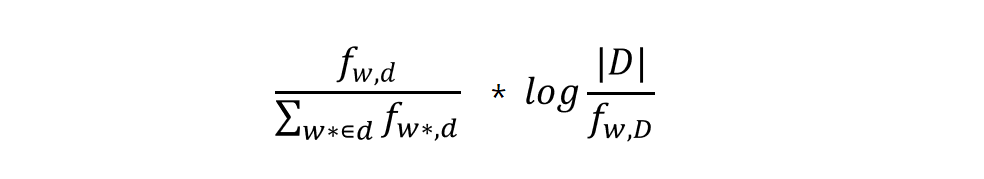
- TF 와 IDF의 곱
- 문서 d 안에 단어 w가 여러 번 등장할수록 tf 값이 증가하며
- corpus 안에 단어 w를 포함하는 문서가 적을수록
idf값이 증가한다. - 반대로
f(w,D)가|D|와 비슷해지면(일반적으로 많이 쓰이면)idf값이 0에 가까워져, 해당 단어가 무시된다.
TF-IDF의 특징
- 문서를 단어들의 빈도로 나타낸다는 점에서 BoW와 유사
- 하지만 모든 단어를 동등한 비중으로 다루는 게 아니라, 일반적으로 많이 쓰이는 단어일수록 무시하는 페널티를 준다는 점에서 차이가 있음
- TF-IDF의 전제는, 많은 문서들에 공통적으로 포함된 단어는, 어느 특정 문서에서만 등장하는 단어보다 문서의 고유한 특성을 나타내기에 제공하는 정보가 적다라는 것
TF-IDF 의 종류
- 현실에서는 TF-IDF의 많은 variation 들이 있다.
- 예를 들어 gensim 라이브러리의 TF-IDF는 스무딩(IDF가 0이 되지 않게 하는 처리)와 정규화(L2norm)을 수행한다.
- 하지만 목적과 가정이 동일하므로, 변종 기법들도 계산의 방향성은 동일하다.
실습
실습 데이터
- gensim 의 샘플 데이터를 활용한다.
- text corpus 는 9개의 문장으로 이루어져 있다.
- 전처리 코드 등은 샘플 데이터의 코드 혹은, 이전 bag of words 포스팅을 참고한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
text_corpus = [
"Human machine interface for lab abc computer applications",
"A survey of user opinion of computer system response time",
"The EPS user interface management system",
"System and human system engineering testing of EPS",
"Relation of user perceived response time to error measurement",
"The generation of random binary unordered trees",
"The intersection graph of paths in trees",
"Graph minors IV Widths of trees and well quasi ordering",
"Graph minors A survey",
]
# ... 전처리 부 생략 ... #
print(processed_corpus)
[['human', 'interface', 'computer'],
['survey', 'user', 'computer', 'system', 'response', 'time'],
['eps', 'user', 'interface', 'system'],
['system', 'human', 'system', 'eps'],
['user', 'response', 'time'],
['trees'],
['graph', 'trees'],
['graph', 'minors', 'trees'],
['graph', 'minors', 'survey']]
TF-IDF 손코딩
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# TF-IDF
from math import log
# test doc
new_doc_words = "system minors".lower().split()
new_doc_bow = dictionary.doc2bow(new_doc_words)
print("words of corpus")
pprint.pprint(processed_corpus)
print('='*50)
print("new doc words\n")
print(new_doc_words)
print("new doc BoW")
print(new_doc_bow)
print('='*50)
# 손코딩 TF-IDF
tf_system = len([word for word in new_doc_words if word == 'system']) / len(new_doc_words)
idf_system = log(len(processed_corpus) / len([doc for doc in processed_corpus if 'system' in doc]))
tfidf_system = tf_system * idf_system
tf_minors = len([word for word in new_doc_words if word == 'minors']) / len(new_doc_words)
idf_minors = log(len(processed_corpus) / len([doc for doc in processed_corpus if 'minors' in doc]))
tfidf_minors = tf_minors * idf_minors
print("손코딩")
print(f'word : system / id : {dictionary.token2id["system"]} / tf : {tf_system}, / idf : {idf_system} / tfidf : {tfidf_system}')
print(f'word : minors / id : {dictionary.token2id["minors"]} / tf : {tf_minors}, / idf : {idf_minors} / tfidf : {tfidf_minors}')
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 출력
words of corpus
[['human', 'interface', 'computer'],
['survey', 'user', 'computer', 'system', 'response', 'time'],
['eps', 'user', 'interface', 'system'],
['system', 'human', 'system', 'eps'],
['user', 'response', 'time'],
['trees'],
['graph', 'trees'],
['graph', 'minors', 'trees'],
['graph', 'minors', 'survey']]
==================================================
new doc words
['system', 'minors']
new doc BoW
[(5, 1), (11, 1)]
==================================================
손코딩 검증
word : system / id : 5 / tf : 0.5, / idf : 1.0986122886681098 / tfidf : 0.5493061443340549
word : minors / id : 11 / tf : 0.5, / idf : 1.5040773967762742 / tfidf : 0.7520386983881371
==================================================
IDF 계산
아래에서 말하는 log는 자연로그(ln)을 의미한다.
- 9개 문서 중
system이라는 단어가 등장하는 문서는 3개,minors는 2개다. - 따라서
system이라는 단어의 IDF 는log(9/3) = log3 = 1.0986이 된다. - 그리고
minors이라는 단어의 IDF 는log(9/2) = log4.5 = 1.5041이 된다.
TF 계산
- 문서는 2개의 각기 다른 단어를 가지고 있다.
- 따라서 각 단어의 TF 값은
1/2 = 0.5가 된다.
TF-IDF 계산
system에 대한 TF-IDF 는 TF와 IDF의 곱인0.5 * log3 = 0.5493이 된다.minors에 대한 TF-IDF 는 TF와 IDF의 곱인0.5 * log4.5 = 0.7520이 된다.
gensim을 이용한 TF-IDF 계산
1
2
3
4
5
6
7
8
9
from gensim import models
# train tf-idf model from corpus
tfidf = models.TfidfModel(bow_corpus) # bow_corpus : test_corpus 를 BoW 한 리스트
# test doc
new_doc_words = "system minors".lower().split()
new_doc_tfidf = tfidf[new_doc_bow]
print(new_doc_tfidf)
1
2
# 출력
[(5, np.float64(0.5898341626740045)), (11, np.float64(0.8075244024440723))]
- 표준적인 계산식을 통해 계산한 TF-IDF와 gensim을 이용해 계산한 결과값은 서로 다름을 볼 수 있다.
gensim의 TF-IDF 계산식
- IDF 를 계산할 때, IDF가 0이 되지 않도록 스무딩을 적용한다.
1
2
3
4
5
# 표준적 IDF
idf = log(전체문서개수 / 단어를포함하는문서개수)
# gensim IDF
idf = log((전체문서개수 + 1) / (단어를포함하는문서개수+1)) + 1
- 또한 TF를 “문서의 모든 단어 중 특정 단어의 빈도 비율”이 아닌,
"특정 단어의 등장 횟수"로 계산한다.
1
2
3
4
5
# 표준적 TF
tf = (특정단어의등장빈도) / (문서내모든단어의등장빈도)
# gensim TF
tf = (특정단어의 등장빈도)
gensim TF-IDF 코드 뜯어보기
- 시간이 나면 해보기
Reference
방송통신대학교 - 자연언어처리 수업 (유찬우 교수)
gensim 샘플 데이터 및 코드
Comments