
CQRS
CQRS 의 개념
Command Query Responsibility Segregation, 아키텍처 설계 중 "쓰기" 작업과 "읽기" 작업을 분리하도록 설계하는 방법입니다.
이를 통해 쓰기, 읽기 각 작업에 특화된 기술을 적용하여 성능적 이점을 얻는 것을 가장 큰 목표로 합니다.
가장 약한 CQRS 로는 코드적으로 쓰기 기능과 읽기 기능을 분리하는 것 부터 시작해,
쓰기 전용과 읽기 전용으로 데이터 저장소를 분리하는 강한 CQRS 까지 있습니다.
용어 뜯어보기
- Command : 시스템의 상태를 변경하는 Create, Update, Delete 작업. 즉, 쓰기 작업
- Query : 데이터를 조회하는 작업. 즉, 읽기 작업
- Responsibility : 책임
- Segregation : 분리
Command(쓰기) Query(읽기) 작업 책임 분리 시스템 아키텍처 패턴
도식으로 알아보기
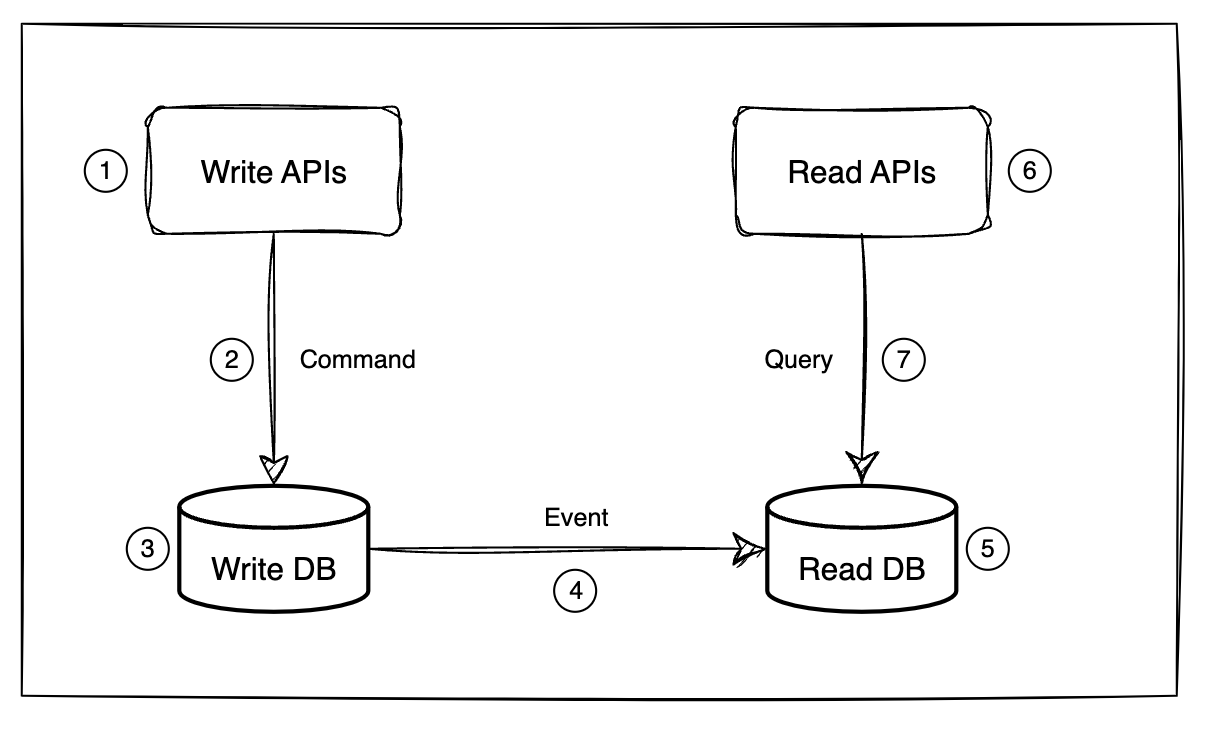
본 CQRS 는 가장 강한 단계의 CQRS 로, 쓰기 저장소와 읽기 저장소가 분리된 예시입니다.
(1) Command (C/U/D) 요청이 발생함
(2) Command 작업이 비즈니스 로직에 따라 실행됨
(3) Write DB (쓰기 저장소) 에 반영됨
(4) 특정 조건, 이벤트에 따라 Write DB 내용을 Read DB 전송
(5) Write DB 의 내용이 Read DB 에 적용됨
(6) Query (읽기) 요청이 발생함
(7) Read DB 를 향해 Query 작업이 실행됨
Command 와 Query
Command (쓰기 작업)
- Create(생성), Update(수정), Delete(삭제) 와 같이 상태를 변경하는 작업
- 목적 : 비즈니스 규칙에 따라 시스템 상태를 일관되게 변경하는 것
- 예시 : 상품 등록, 주문 생성, 결제 처리, 상품 재고 수정 등
- Command 에 대한 데이터 모델은 아직까지고 RDBMS 가 대세
Query (읽기 작업)
- Select(조회) 와 같이 데이터를 읽는 작업
- 목적 : 필요한 정보를 효율적(빠르고, 정확하게) 검색하고 표현하는 것
- 상품 목록 조회, 주문 내역 확인, 검색 결과 표시 등
CQRS의 등장 배경과 도입 이유
(1) Command 작업과 Query 작업의 비대칭성
- 일반적인 서비스에서는 Query 작업의 빈도가 Command 작업의 빈도보다 훨씬 많음
- 예를 들어 온라인 쇼핑몰에서는 상품 등록의 빈도보다 상품 목록 조회 빈도가 훨씬 많음
- 때문에 Query 작업에서 얻을 수 있는 성능적 이득의 크기가 Command 보다 클 확률이 높음
(2) Command 성능과 Query 성능의 트레이드오프
| 구분 | Command 작업 | Query 작업 |
|---|---|---|
| 설명 | 쓰기 작업 | 읽기 작업 |
| 목표 | 상태 변경 | 데이터 제공 (상태 변화 없음) |
| 중요 포인트 | - ACID 가 중요 - 트랜잭션 보장 - 강한 논리적 일관성 - 지속성 |
- 빠른 응답 시간 - 높은 처리량 - 수평적인 확장성 |
| 최적화 방향 | - 정규화 - 인덱싱 최소화 |
- 반정규화 - 최대한 많은 인덱싱 |
| 일관성 | - 논리적 일관성이 절대적으로 중요 | - 작업, 시점에 따라 일관성 강도 유연하게 가능 |
| 데이터 모델 | - 정규화된 도메인 모델 | 비정규화된 뷰 모델 |
- Command 작업과 Query 작업의 최적화 방향이 다름
- Command : 정규화, 최소한의 인덱싱(인덱싱 작업 최소화)
- Query : 반정규화(Join 최소화), 최대한의 다중 인덱싱
- 즉, Command 와 Query 최적화는 트레이드 오프의 관계
예시 : 정규화 (쇼핑몰 주문정보)
Command : 상품 정보, 고객 정보, 주문 정보 등으로 나눠 정규화 하는 것이 최적화의 방향
Query : 데이터가 정규화 될 수록 많은 Join 이 요구됨 -> 성능의 저하
예시 : 인덱싱
Query : 데이터에 많은 인덱싱이 될 수록 빠른 조회가 가능
Command : 인덱싱이 많아질 수록 인덱싱 작업에 소요되는 시간 증가
(3) 모놀리식 아키텍처에서 트랜잭션 락
- 모놀리식 아키텍처에서는 시스템 전반이 단일 공유 데이터베이스를 사용
- 따라서 Command 작업과 Query 작업도 동일한 데이터 모델을 바라봄
- 무결성을 위한 트랜잭션 락으로 인해 하나의 작업 중 다른 작업이 대기하는 한계
(4) Query 특화 데이터 저장소
- Query 작업에 특화된 데이터 저장소/방법 존재 : 검색 엔진, NoSQL, 캐시…
- 이들은 특정 읽기 작업 유형에 최적화된 Query 성능을 보일 수 있게 설계됨
- 하지만 Command 와 함께 단일 데이터 모델을 사용할 경우 위외 같은 저장소 사용 불가
- 결국 얻을 수 있는 Query 의 성능적 이득을 놓치게 되는 악영향으로 돌아옴
(5) 단일 책임 원칙
- Command 와 Query 는 근본적으로 다른 특성을 가진 작업임
- 둘이 동일 데이터 모델을 사용할 경우, 한 쪽의 변경사항이 다른 쪽에 불필요한 영향을 주게 됨
- 이는 단일 책임 원칙에 위배되는 형태
(6) 데이터 모델 분리의 필요성
- 도메인이 복잡해지면서 Command 와 Query 데이터 모델 분리의 필요성이 높아짐
- 또한 Command 보다 Query 쪽의 요구사항과 비즈니스로직의 변경 빈도가 훨씬 많음
- 단일책임원칙 관점으로도 둘을 분리하는 것에서 얻는 이득이 있을 수 있음
CQRS 의 장단점
장점
| 장점 | 설명 |
|---|---|
| 확장성의 향상 | 읽기/쓰기 작업을 독립적으로 확장할 수 있음 |
| 성능 최적화 | 각 작업 유형에 맞는 데이터 모델과 기술을 선택할 수 있음 |
| 기술 다양성 | 목적에 맞는 다양한 데이터 저장소를 선택해 활용할 수 있음 |
| 복잡성 관리 | 관심사 분리를 통해 코드 복잡성을 감소시킬 수 있음 |
단점
| 단점 | 설명 |
|---|---|
| 복잡성 증가 | 시스템 관리 관점에서의 복잡성이 증가될 수 있음 |
Reference
Wanted 커리어 프리온보딩 - 2-4년차 백엔드를 위한 CQRS 패턴과 실시간 데이터 처리
Comments