
들어가기 전에 : 코드 : 딥러닝 개요_ipynb 코드
공부 환경
- 교재 : 백견불여일타
- 코딩 환경 : Google Colab
- Colab 사용 이유 : GPU 세션을 통한 빠른 속도의 연산처리 가능
- Colab 사용법 : 대부분 주피터 랩과 비슷하나, 단축키 부분은 조금 다름
- Colab 주의사항 : GPU 사용은 6~8시간 사용 후 24시간 대기 필요.
때문에 불필요한 GPU 세션 연결은 지양
1. 딥러닝 개요

- 딥러닝이란
기계학습 방법, 인공지능의 일종. 많은 데이터를 가지고 컴퓨터가 사람처럼 스스로 학습하도록 인공신경망 등의 기술을 이용한 기법이다. 여러(깊은) 학습층을 가지고 유연하고도 확장성 높은 학습이 가능한 기술이다.
자료를 컴퓨터가 알아들을 수 있는 형태로 표현(ex.이미지->배열화)하고, 이를 컴퓨터가 학습하도록 하기 위한 많은 연구들의 결과로 여러 딥러닝 기법들이 만들어지고 있다. (DNN, CNN, RNN, RBM, DBN, Deep Q-Networks 등)
딥러닝은 과거 과적합 문제와 느린 학습시간이라는 문제를 안고 있었으나, 과적합 방지 기술과 하드웨어의 발전에 따라 문제들이 해결됐고, 현업과 생활 전반에서 많은 부분들이 데이터화됨에 따라 많은 데이터(=빅데이터)들이 생겨나고 이를 수집하고 분석하는 기술의 발전에 따라 각광받고 있는 기술이다.
딥러닝에 대해서는 아래 영상을 참고.
https://www.youtube.com/watch?v=aircAruvnKk
딥러닝의 역사에 대해서는 아래 글을 참고.
https://beamandrew.github.io
- 딥러닝이 활약하는 분야
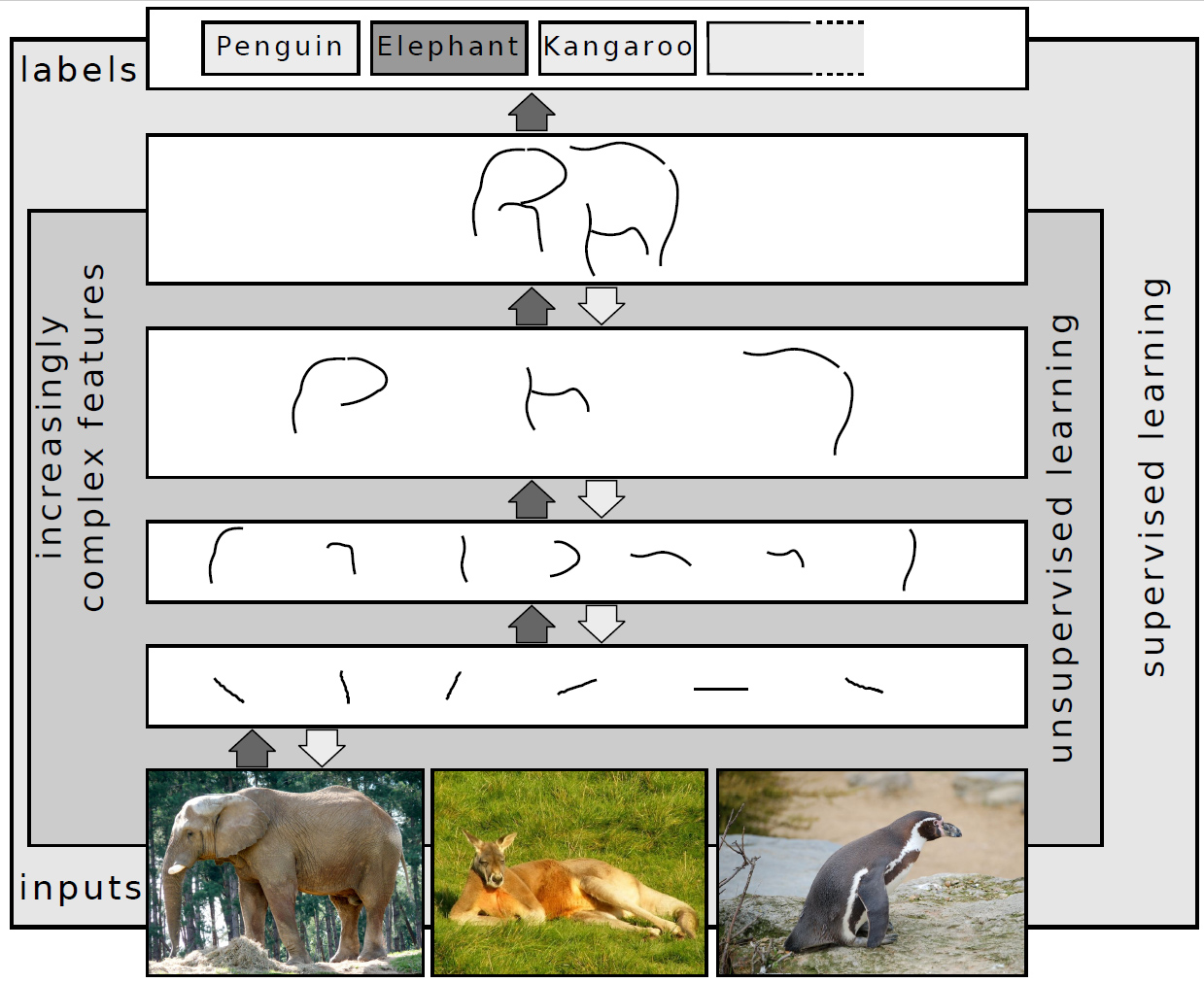
저작자:Sven Behnke / 위키피디아: 링크 / 라이선스 : CC-BY-SA 3.0
- 음성 인식 : 코타나, 스카이프, 구글 나우, 애플 시리 등
- 영상 인식 : 이미지 분류, 자동차 탑재용 컴퓨터 등
- 자연어 처리 : 단어표현에 대한 학습 및 분석. 번역, 감정 분석, 정보 검색 등에 사용
- 약학 및 독성학 : 약 제조 등에 있어 가상 실험 방법으로 사용됨
- CRM : 고객 관계 관리
- 관련 용어
인공신경망
| 용어 | 영단어 | 설명 |
|---|---|---|
| 인공신경망 | Artificial Neural Network | 인간의 뉴런 구조를 참고하여 만든 기계학습 모델. 뉴런에 해당하는 유닛이라 불리는 개체들이 다음 층에 있는 유닛들에 신호를 주면서 학습해간다. 자세한 내용은 하단 신경망 단원에서 서술한다. |
| 오차 | Error | 모델이 예측한 예측값과 실제값 사이의 차이를 의미한다. 오차가 작을 수록 잘 예측했다고 할 수 있다. |
| 활성화 함수 | Activation Function | |
| 가중치 | weight | 처음 들어오는 데이터를 다음 유닛(혹은 층)으로 넘길 때 데이터를 각기 다른 비중으로 넘기기 위한 값. 유닛들이 각기 다른 값을 내도록 하는 주요한 요인 |
| 편향(역치) | bias | 유닛이 다음 유닛(혹은 층)으로 데이터를 넘길 때, 가중치와 함께 넘기는 값을 조정하는 상수 |
| 퍼셉트론 | perceptron | 인공신경망의 한 종류로서, 여러 개의 입력 신호를 받아, 하나의 출력 신호로 출력하는 과정을 이른다. |
| 단층 퍼셉트론 | Single Layer Perceptron | 입력층과 출력층을 제외한 은닉층이 하나인 퍼셉트론. |
| 다층 퍼셉트론 | Multi Layer Perceptron | 하나의 입력층과 하나의 출력층 및 다수개의 은닉층으로 이루어져있는 퍼셉트론 |
- 딥러닝 알고리즘,라이브러리
딥러닝 알고리즘
| 알고리즘 | 영단어 | 설명 |
|---|---|---|
| 심층 신경망 | Deep Neural Network(DNN) | 입력층과 출력층 사이에 여러 개의 은닉층들로 이뤄진 인공신경망 |
| 합성곱 신경망 | Convolutional Neural Network(CNN) | 최소한의 전처리를 사용하도록 설계된 다층 퍼셉트론의 한 종류 |
| 순환 신경망 | Recurrent Neural Network(RNN) | 인공신경망의 유닛 사이의 연결이 Directed cycle을 구성하는 신경망 |
| 제한 볼츠만 머신 | Restircted Boltzmann Machine(RBM) | 볼츠만 머신에서 층간 연결을 없앤 형태의 모델 |
| 심층 신뢰 신경망 | Deep Belief Network(DBN) | 층간에는 연결이 있지만, 층 내 유닛 간에는 연결이 없는 모습의 신경망 |
| 심층 Q 네트워크 | Deep Q-Networks | 강화 학습을 위한 딥러닝 모델 |
딥러닝 라이브러리
| 라이브러리 | 설명 |
|---|---|
| Tensorflow | 구글에서 발표한 기계학습 오픈소스 라이브러리. 많은 딥러닝 분야가 이 라이브러리를 사용한다. |
| NVIDIA cuDNN | DNN의 프리미티브를 제공해주는 라이브러리 |
| convnetjs | 자바스크립트로 구현된 딥러닝 라이브러리 |
| 그 외 라이브러리는 추후에 설명한다. |
2. 자주 만날 용어 정리
데이터 준비 단계
| 용어 | 영단어 | 설명 |
|---|---|---|
| 클래스 불균형 | class imbalance | 데이터에서 각 클래스(변수. 주로 범주형)가 가지는 데이터 양의 차이가 큰 경우. 불균형 자체가 의미를 가질 수도 있으므로, 불균형 처리시에 주의 필요. |
| 언더 샘플링(과소표집) | under sampling | 클래스 불균형 데이터에 대해 양이 적은 쪽 클래스의 데이터 양에 맞춰 샘플링하는 방법 |
| 오버 샘플링(과대표집) | over sampling | 클래스 불균형 데이터에 대해 양이 많은 쪽 클래스의 데이터 양에 맞춰 샘플링하는 방법 |
| 자세한 내용은 이후 단계에서 추가 공부 |
분석 방법 (분류)
| 용어 | 영단어 | 설명 |
|---|---|---|
| 분류 | Classification | 데이터에서 규칙을 찾아내고, 유사도와 불순도(그룹 내 불순도)에 따라 분류하는 것. 이를 통한 미래 사건의 예측을 목표로 한다. |
| 이진 분류 | Binary - | 분류되는 범주가 두 가지인 분류 분석 방법. 하나의 데이터는 하나의 범주에만 들어갈 수 있다. |
| 다중 분류 | Multiclass - | 분류되는 범주가 여러 개인 분류 분석 방법. 하나의 데이터는 하나의 범주에만 들어갈 수 있다. |
| 다중 레이블 분류 | Multi Label - | 분류되는 범주가 여러 개이면서, 하나의 데이터가 동시에 여러 범주로 들어갈 수 있는 분류 분석 방법. 비 배타적인(non-exclusive) 분류 방식이라고 부를 수 있다. |
분석 방법 (회귀)
| 용어 | 영단어 | 설명 |
|---|---|---|
| 회귀 | Regression | 둘 이상의 변수 간 관계를 찾는 방법. 보통 종속변수가 연속형 숫자인 경우에 사용. 이를 통한 미래 사건의 예측을 목표로 한다. |
| 선형 회귀 | Linear Regression | 예측 대상인 종속 변수 한 개와 이를 설명하는 한 개 이상의 독립변수 간의 선형 관계성(상관성)을 파악하는 회귀 분석 방법 |
| 단순 회귀 | Simple Regression | 예측 대상인 종속변수와 이를 설명하는 독립변수가 모두 하나인 회귀 분석 방법 |
| 다중 회귀 | Multiple Regression | 예측 대상인 종속변수는 하나이지만, 이를 설명하는 독립변수를 여러개로 하는 회귀 분석 방법 |
| 로지스틱 회귀 | Logistic Regression | 종속변수가 범주형 데이터인 경우 사용되는 회귀 분석 방법 |
| 이항형(단순) 로지스틱 회귀 | Binomial - | 종속변수가 이항형(분류가 두 개인 하나의 범주; ex.생물학적 성별)일 때의 분석 방법 |
| 다항형(다항) 로지스틱 회귀 | Multnomial - | 종속변수가 다항형(분류가 두 개 초과인 하나의 범주; ex.봄/여름/가을/겨울)일 때의 분석 방법 |
전처리
| 용어 | 영단어 | 설명 |
|---|---|---|
| 원 핫 인코딩 | One-Hot-Encoding | 수치형이 아닌 자료를 수치형으로 표현할 수 있게 하는 인코딩 방법. 여러 개의 클래스를 각각 칼럼으로 생성해준 후, 데이터가 해당되는 칼럼에는 1, 해당되지 않는 칼럼에는 0을 표시하는 방법. |
| 레이블 인코딩 | Label Encoding | 수치형이 아닌 자료를 수치형으로 표현할 수 있게 하는 인코딩 방법. 하나의 클래스를 하나의 숫자로 변환한다. 딥러닝에서는 이 방식을 지양하는데, 딥러닝 모델이 인코딩된 숫자값의 크기 차에 영향을 받을 수 있기 때문. |
모델 학습과 파라미터
| 용어 | 영단어 | 설명 |
|---|---|---|
| 하이퍼 파라미터 |
Hyper Parameter | 모델이 스스로 찾는 요소 외로, 사람이 직접 설정해줘야 하는 요소. 학습률, 학습 횟수 등이 있다. |
| 학습률 | Learning Rate | 인공신경망 모델은 데이터를 학습하면서 예측치와 실제값 간의 오차를 줄여나가는 것을 우선 목표로 한다. 이를 위해 예측을 위한 함수에서 가중치(weight)와 역치(bias)를 조정하는데, 이 가중치와 역치를 조정하는 강도를 학습률이라고 한다. |
| 에폭 | Epochs | 전체 데이터를 학습하는 횟수. 전체 데이터를 10번 학습한다면 epochs = 10 (10epochs)이 된다. |
| 스텝 | Steps | 모델의 가중치(weight)와 역치(bias)를 업데이트 하는 횟수. 업데이트 횟수가 10번이면 steps = 10 (10steps)이 된다. |
| 배치 크기 | Batch Size | 1step에서 사용한 데이터의 개수이다. 몇 개의 데이터를 학습할 때마다 중량치를 조정할지. |
| 예시 | 일주일동안 매일 벤치 프레스 40개를 5세트로 나눠 하려 한다. 1. epoch = 7 (일주일) 2. step = 5 (5세트) 3. batch size = 8 (세트당 8회) 4. 학습률 : 벤치프레스 중량 조정비 5. n(전체 데이터 수) = 40 |
과대, 과소적합
| 용어 | 영단어 | 설명 |
|---|---|---|
| 과적합 (과대적합) |
Over Fitting | 모델이 학습(훈련) 데이터에 너무 최적화하여 만들어진 경우. 학습(훈련)데이터에는 좋은 분류/예측 성능을 보이지만, 검증 혹은 실제 데이터에는 낮은 분류/예측 성능을 보일 수 있다. 그러므로 모델을 만들 때 과적합되지 않도록 주의해야 한다. |
| 과소적합 | Under Fitting | 과대적합의 반대 개념. 모델이 학습(훈련)데이터를 정확히 분류/예측하지 못하는 문제. |
평가
- 평가는 머신러닝에서의 평가와 동일한 지표들을 사용한다.
(업데이트 필요) 머신러닝 평가지표 링크
3. 인공 신경망
딥러닝을 알기 위해서는 우선 인공 신경망을 알아야 한다. 딥러닝은 인공신경망을 베이스로 하기 때문.
인공신경망은 인간의 뉴런간 시냅스 결합에서 영감을 얻은 기계학습 방법의 하나이다. 하나의 층 혹은 여러 개의 층에 속한 유닛(신경계의 뉴런에 해당)간의 정보 전달을 통해 학습을 해가는 방법으로, 필기체 인식 및 음성 인식 등에 활용된다.
- 활성화 함수
Activation Function
한 층의 유닛에서 다음 층의 유닛에 전달하는 값을 변환하는 함수로, 활성화 함수를 통해 변환된 값이 임계값을 넘지 못하는 경우 다음 층으로 값이 전달되지 않는다.
활성화 함수는 ‘비선형’ 함수를 사용하는데, 이는 딥러닝 모델의 레이어 층을 깊에 가져갈 수 있기 때문이다. 즉, 선형 함수를 사용할 경우 아무리 많은 층을 사용하더라도 선형으로 설명이 가능하기 때문에, 딥러닝을 이용하는 의미가 없어지는 것이다.
다양한 활성화 함수가 있으며, 아래와 같다.
| 활성화 함수 | 영단어 | 설명 |
|---|---|---|
| 시그모이드 함수 | Sigmoid Function | 입력값을 0~1 사이의 값으로 변환한 뒤 출력(전달) 하는 함수 |
| ReLU | Rectified Linear Unit | 입력값이 0보다 작으면 0으로 출력, 입력값이 0보다 크면 그대로 출력(전달)하는 함수 |
| 쌍곡탄젠트 | Hyperbolic Function | 입력값을 -1~1 사이의 값으로 변환한 뒤 출력(전달) 하는 함수 |
| 소프트맥스 함수 | Softmax Function | 세 개 이상으로 분류하는 다중 클래스 분류에서 사용되는 함수로, 각 클래스에 속할 확률을 추정하는 함수이다. 인공신경망에서는 가장 마지막 활성화 함수로 자주 쓰인다. 입력값을 자연로그의 밑으로 한 지수 함수를 취한 두, 그 지수함수의 합으로 나눠주는 것. 다른 활성화함수와는 조금 다르게 보아야 한다. |
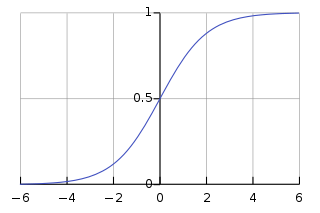
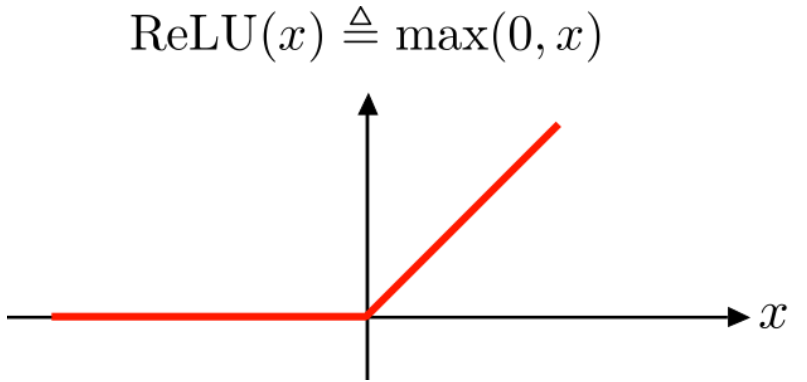
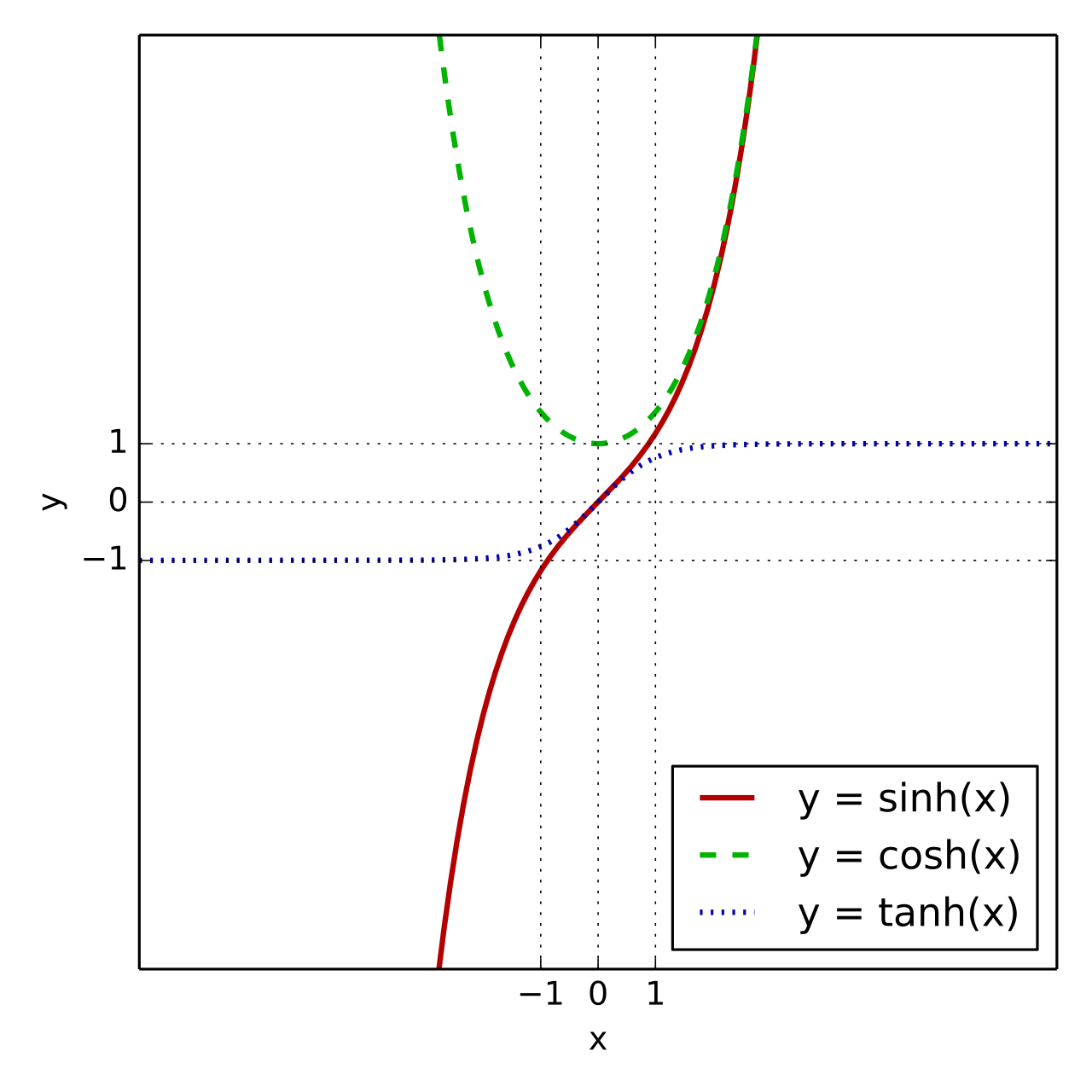
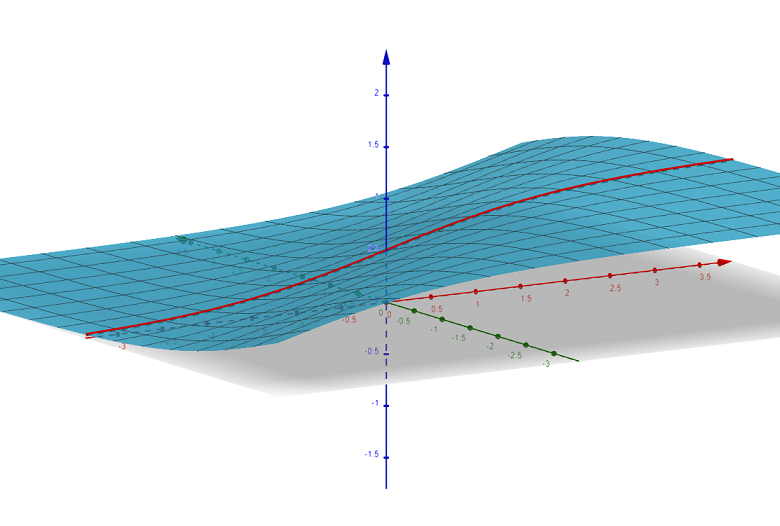
추가 필요 : - 손실함수
추가 필요 : - 평가지표
4. 퍼셉트론 알고리즘
- 퍼셉트론 알고리즘이란?
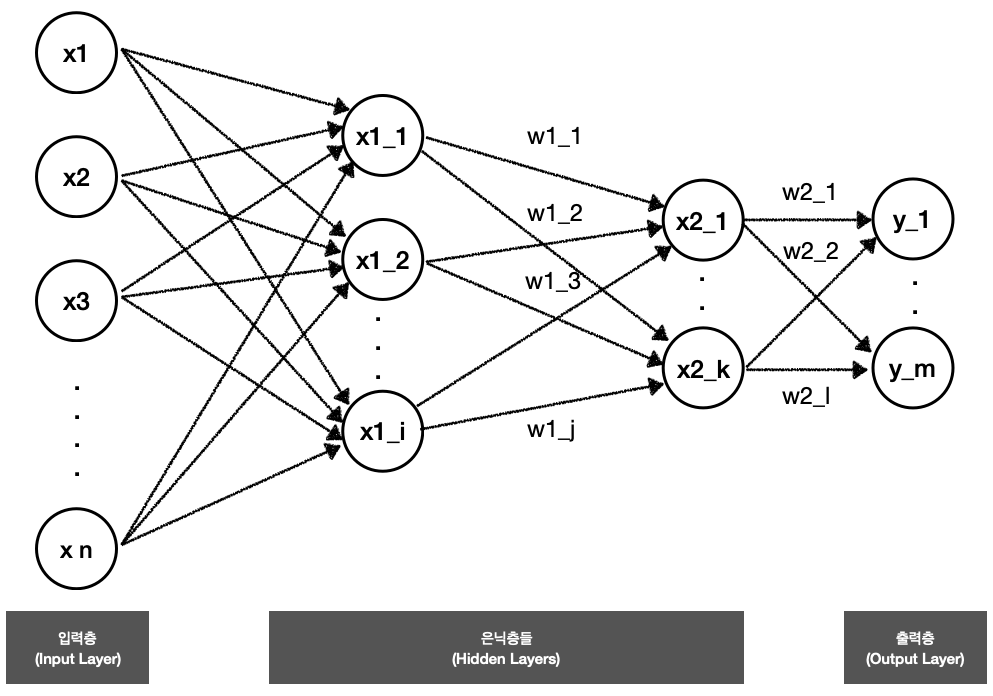
인공신경망의 한 종류로서, 여러 개의 입력 신호를 받아, 하나의 출력 신호로 출력하는 과정을 이른다.
인공신경망은 크게
(1) 입력 신호를 받는 입력층
(2) 신호에 가중치와 역치 계산을 조정한 후, 활성함수를 통해 다음 층으로 전달하는 은닉층
(3) 값을 출력하는 출력층 으로 이루어져 있다.
-
층 layer 입력층과 출력층 사이에 있는 은닉층. 은닉층에 있는 뉴런들이 가중치와 bias값을 조정하면서 학습하는 과정을 통해 최소 손실값을 찾아간다. 층의 유닛간 연결법에는 Dense(완전연결), LSTM, RNN 등이 있다.
-
유닛 (=노드 = 뉴런)
각 층에 있는 정보를 받고, 다음 층으로 정보를 전달하는 x들을 ‘유닛(=뉴런 =노드)’라 한다. -
가중치 weight
하나의 유닛에서 다음 층에 있는 유닛에 정보를 전달할 때, 가중치(weight)를 곱하고 편향(bias)을 더한 후 전달하게 된다. 전달된 정보는 활성화 함수를 통해 임계값을 넘어야 전달되며, 임계값에 미달할 경우 전달되지 않는다. -
활성화 함수 activation function
입력값(정보)을 변환하는 함수. 변환된 입력값이 임계값을 넘어가면 값이 다음 층의 유닛으로 전달된다.
- 퍼셉트론 만들기
퍼셉트론 만들어보기기본적인 퍼셉트론 모델 코딩 FLOW (펼치기/접기)
- keras 주요 클래스 설명
> keras 주요 클래스
| keras 주요 클래스 | 설명 |
|---|---|
| keras.Sequential() | 층을 차례대로 쌓은 모델 |
| keras.layers() | 층을 생성하는 메서드 |
| keras.data import Dataset | 케라스 데이터셋 |
| keras.Model.evaluate() | 손실(loss)과 정확도 등의 지표 |
| keras.Model.predict() | 예측 실행 |
| keras.Model.summary() | 모델의 층 정보, 파라미터 정보 등을 요약해 보여준다. |
> keras 레이어 클래스
| layer | 설명 |
|---|---|
| Input | 입력층. 들어오는 데이터 형태를 지정해주면 된다. |
| Dense | 완전연결층. 모든 유닛들이 연결된다. |
| LSTM | |
| GRU | |
| SimpleRNN | |
| TimeDistributed | |
| Bidirectional | |
| ConvLSTM1D ~ 3D | |
| BaseRNN | |
| 그 외로, layer를 직접 설정해줄 수도 있다. |
| activation function | 설명 |
|---|---|
| relu | ReLU 함수. 입력값이 0보다 작으면 0으로 출력, 입력값이 0보다 크면 그대로 출력(전달)하는 함수. 가장 많이 쓰인다. |
| sigmoid | 시그모이드 함수 |
| softmax | 소프트맥스 함수. 입력값을 자연로그의 밑으로 한 지수 함수를 취한 두, 그 지수함수의 합으로 나눠주는 것. |
| tanh | 탄젠트쌍곡선. 입력값을 -1~1 사이의 값으로 변환한 뒤 출력(전달) 하는 함수 |
| softplus | ReLU함수를 부드럽게 근사한 것으로, 출력을 항상 양수로 제한한다. |
| softsign | 시그모이드와 비슷하면서, 경사소실문제를 어느정도 완화해줌. |
| elu | ReLU의 변종으로, 다른 ReLU 변종들의 성능을 앞질렀다. 시간단축, 성능향상 |
| selu | ELU 의 변종. 완전연결 + 모든 은닉층이 selu 사용시 네트워크가 가지 정규화 된다고 저자가 주장함. 평균0과 표준편차 1을 유지하는 경향을 보임. |
| exponential | 지수함수. |
| 그 외, 직접 활성함수를 제작할 수도 있다. |
> keras compile 클래스 : (layer의 optimizer, loss, metrics 설정)
| Optimizer | 설명 |
|---|---|
| Optimizer? 직역하면 최적화 알고리즘으로, ‘손실값을 최소로 하는 최적의 방법’을 찾아가는 방법론. 손실함수를 통해 얻은 손실값으로부터 모델을 업데이트하는 계산식을 의미한다. | |
| Adam | 일반적으로 가장 많이 사용하는 옵티마이저. RMSprop에 모멘텀을 적용한 것. |
| SGD | 경사하강법. 모멘텀 및 네스테로프 모멘텀, learning_rate_decay 방법을 지원한다. |
| RMSprop | 일반적으로 순환 신경망 RNN의 옵티마이저로 많이 사용된다. |
| Adagrad | 모델 파라미터별 학습률을 사용하는 옵티마이저. 파라미터의 값이 업데이트되는 빈도에 의해 학습률이 결정됨. 모든 인자를 기본값으로 사용하는 것이 권장됨. |
| Adadelta | Adagrad를 확장한 보다 견고한 옵티마이저. 과거의 모든 그래디언트를 축적하는 대신, 그래디언트 업데이트의 이동창에 기반해 학습률을 조정함. |
| Adamax | Adam의 변형으로, 무한 노름(infinity norm)에 기반함 |
| Nadam | RMSprop에 네스테로프 모멘텀을 적용한 옵티마이저. |
| loss | 문제종류 | 설명 | 모델의 마지막 활성화 함수 |
|---|---|---|---|
| loss? 손실함수(=최적화 함수) 최소의 손실값을 찾아가는 계산식이다. | |||
| binary_crossentropy | classification | 클래스가 두 개인 이진 분류 문제에서 사용하는 손실함수. label이 0 또는 1을 값으로 가질 때. | sigmoid |
| categorical_crossentropy | classification | 클래스가 여러 개인 다중 분류 문제에서 사용하는 손실함수. label이 원-핫 인코딩 된 형태에서 사용한다. | softmax |
| sparse_categorical_crossentropy | classification | 클래스가 여러 개인 다중 분류 문제에서 사용하는 손실함수. label이 정수 인코딩 label encoding 된 값을 가질 때 사용한다. | softmax |
| mse | regression | mean_squared_error. 평균 제곱 오차 손실. | |
| mean_absolute_error | regression | ||
| mean_absolute_percentage_error | regression | ||
| mean_squared_logarithmic_error | regression | ||
| squared_hinge | regression |
| metrics | 문제종류 | 설명 |
|---|---|---|
| metrics? 평가지표. keras에서는 한 층에 다수의 평가지표를 리스트 형태로 넣을 수 있다. | ||
| acc | Classification | 정확도 |
| mse | Regression | MeanSquaredError |
| rmse | Regression | 평균 제곱근 편차 Root Mean Square Error |
| r2 | Regression | 통계학의 결정계수. 추정한 선형 모형이 주어진 자료에 적합한 정도. |
| mae | Regression | MeanAbsoluteError |
| mape | Regression | MeanAbsolutePercentageError |
| msle | Regression | MeanSquaredLogarithmicError |
| categorical_crossentropy | Probabilistic | |
| precision, recall, f1 등은 keras 2.0부터 제외되었다. 이에 해당 지표를 사용하려면 사용자 정의 함수로 정의해야한다. |
- 단층 퍼셉트론
Single layer Perceptron
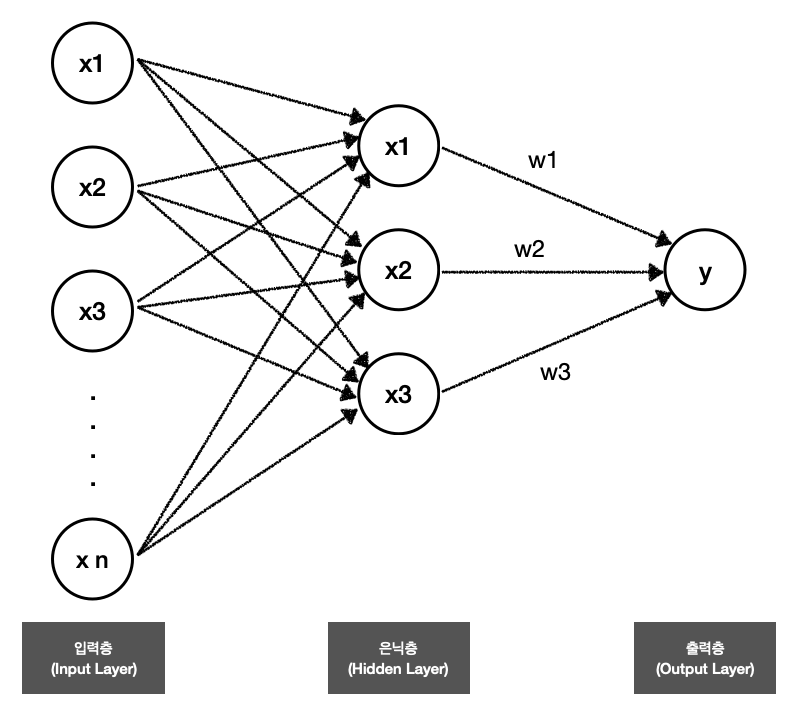
입력층과 출력층을 제외한 은닉층이 하나인 퍼셉트론.
각각의 입력값에 대해 유닛에서 가중치를 준 후, 활성화 함수를 통해 다음 층으로 값을 전달하거나 전달하지 않는다.
AND, OR, NAND(Not-AND) 와 같은 선형 분리가 가능한 문제에 대해선 해결이 가능하나,
XOR(배타적 논리합) 연산은 해결이 불가능한 문제를 가지고 있다. (하기 코드 강조)
이 문제와 함께 하드웨어의 연산 속도의 한계로 인해 인공신경망은 발전이 더딘 암흑기를 보냈었다.
OR, NAND, XOR에 대한 설명펼치기/접기
구분 설명 OR 논리합.
둘 중 하나라도 True [0, 1] [1, 0] [1, 1]이면 -> True(1)
둘 다 False [0, 0] 이면 -> Flase(0)AND 논리곱.
둘 다 True [1, 1] 이면 -> True(1)
둘 중 하나라도 False [0, 1],[1, 0],[0,0]이면 -> False(0)NAND 둘 다 True [1, 1] 이면 -> True가 아님(False=0)
둘 다 True 가 아니면[0, 0] -> True(1)XOR 둘 중 한 가지만 True면 -> True(1)
둘 다 True거나 False면 -> False(0)
단층 퍼셉트론 만들어보기OR 데이터에 대한 단층 퍼셉트론 모델
NAND(Not AND) 데이터에 대한 단층 퍼셉트론 모델
XOR(exclusive or : 배타적 논리합) 데이터에 대한 단층 퍼셉트론 모델
- 다층 퍼셉트론
Multi layer Perceptron
하나의 입력층과 하나의 출력층 및 다수개의 은닉층으로 이루어져있다.
퍼셉트론을 여러 층 쌓은 모습으로, 각 층에서는 활성함수를 통해 값이 전달된다.
기존 단층 퍼셉트론이 아무리 학습을 시켜도 XOR문제에 대해서는 정확도가 떨어지는 반면,
다층 퍼셉트론은 이러한 XOR 문제를 해결하였다.
이 다층 퍼셉트론은 현재 딥러닝의 기본 바탕이 된다.
다층 퍼셉트론 만들어보기XOR 데이터에 대한 다층 퍼셉트론 모델
5. 실습 : 신경망 만들어보기
- 케라스
- import keras
- 파이썬 기반 머신러닝 라이브러리
- 텐서플로우를 편하게 사용할 수 있도록 보조하는 역할
-
텐서플로우는 거의 모두 케라스를 통해 사용한다 해도 과언이 아님
- (1) 높은 유연성
- (2) 명확한 예약어명
등등의 장점
- 실습 : 손글씨 인식 딥러닝
이제 딥러닝을 실제로 사용해볼 차례입니다.
손글씨를 인식하고 예측하는 모델을 만들어봅시다.
코드는 아래 접어놨으니, 펼쳐서 봐주세요.
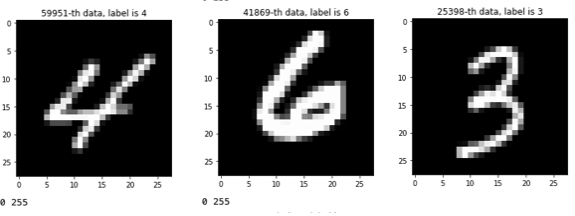
- 사용 데이터셋 : keras.datasets.mnist
- 손글씨 데이터셋으로
- x = 총 7만개의 데이터, 각 데이터는 28*28 픽셀 이미지
- y = 총 7만개의 데이터, 데이터는 0부터 9까지의 값 (답안)
1
2
3
4
5
'=== import ==='
from keras.datasets.mnist import load_data # 손글씨 데이터셋
import matplotlib.pyplot as plt # 이미지 시각화 도구
import numpy as np # 행렬 연산 도구
from keras.utils import to_categorical # 범주형데이터 인코딩 모듈
1
2
3
4
5
6
7
8
9
10
'=== 훈련/테스트 데이터 나누기 ==='
(x_train, y_train), (x_test, y_test) = load_data()
'=== 데이터 살펴보기 ==='
print(x_train.shape, y_train.shape, x_test.shape, y_test.shape)
# x_train : 60000, 28, 28 -> 6만개, 28*28 행렬
# y_train : 60000, -> 6만개 1개씩
# x_test : 10000, 28, 28 -> 1만개, 28*29 행렬
# y_test : 10000, -> 1만개 1개씩
실습 : 손글씨 인식 딥러닝이후 코드 펼치기/접기
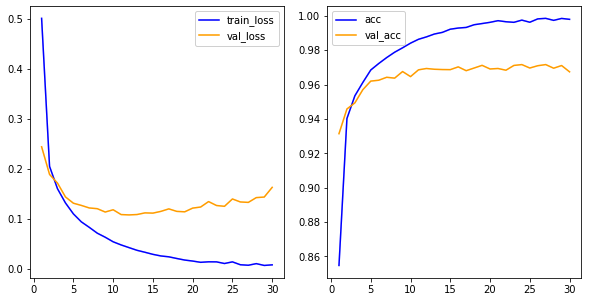
{kind=link}
- 딥러닝 학습의 의의
- 딥러닝 학습은 연산의 ‘가중치’를 얻어내는 과정이다.
To Do
- 용어 정리 - 인공신경망 부분 좀 더 쉽게 설명
- 용어 정리 - 평가 지표 부분 추가
- 인공 신경망 - 손실함수, 층에 대한 추가 설명
- keras - 주요 클래스 설명 마무리
레퍼런스
- 교재1 : 백견불여일타 딥러닝
- 교재2 : 이기적 빅데이터 분석기사 2022(나홍석 등)
- 클래스 불균형 : https://techblog-history-younghunjo1.tistory.com/74
- 회귀분석 : https://bioinformaticsandme.tistory.com/290
- 회귀분석 : https://ko.wikipedia.org/wiki/회귀_분석
- 인공신경망의 역사 : https://beamandrew.github.io/deeplearning/2017/02/23/deep_learning_101_part1.html
- 인공신경망 개요 : https://ko.wikipedia.org/wiki/인공_신경망
- 딥러닝 개요 : https://ko.wikipedia.org/wiki/딥_러닝
- 다층 퍼셉트론 설명 : https://www.youtube.com/watch?v=aircAruvnKk
- Batch, Epoch 등 설명 : http://esignal.co.kr/ai-ml-dl/?board_name=ai_ml_dl&search_field=fn_title&order_by=fn_pid&order_type=asc&board_page=1&list_type=list&vid=15
- 과대적합, 과소적합 : https://heytech.tistory.com/125
- 활성화함수 : https://themaverickmeerkat.com/2019-10-23-Softmax/
- 활성화함수 : https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=handuelly&logNo=221824080339
- keras 활성화함수 : https://keras.io/api/layers/activations/#relu-function
- keras 활성화함수 : https://hwk0702.github.io/ml/dl/deep%20learning/2020/07/09/activation_function/
- 옵티마이저 : https://codetorial.net/tensorflow/basics_of_optimizer.html
- ★★★옵티마이저 : https://keras.io/ko/optimizers/
- 손실함수 : https://cheris8.github.io/artificial%20intelligence/DL-Keras-Loss-Function/
Comments