
Intro
논문을 보게 된 경위
- 시스템 설계 중 도저히 모르겠어서 표준적인 것들을 찾아봄.
- 그 중 정리가 잘 되어 있는 게 있어서 리뷰해본다.
논문 정보
- https://arxiv.org/abs/2205.02302
- 저자 : Dominik Kreuzberger, Niklas Kühl, Sebastian Hirschl
- 제출 : 2022-05-04 / 최종 2025-05-14
- License : CC BY-NC-ND 4.0
Abstract
- ML 제품을 자동화하고 운영하는 MLOps는 아직까지 모호한 용어이다.
- 이를 극복하기 위해 MLOps의 핵심 원칙, 구성 요소, 역할들에 대한 종합적 개요
- 그리고 관련된 아키텍처와 워크플로우를 제시한다.
Introduction
DevOps에 대한 정의
- 2008 ~ 2009 년 경에 등장한 개념으로, 개발과 운영 사이의 간극을 해소하고자 하는 목표로 발생한 방로론이자 패러다임
- DevOps 는 지속적 통합(CI), 지속적 전달(CD), 지속적 배포(CD)를 포함한다.
- DevOps로 전환되는 흐름에 따라, 개발자는 자신이 개발한 것을 직접 운영하는 것까지 고려해야 한다.
연구 방법론
- 혼합 연구 방법 적용 : 문헌 리뷰, 도구 검토, 전문가 인터뷰 연구
- 문헌 리뷰 : 27편의 피어 리뷰된 학술 논문 리뷰, MLOps는 비교적 신생 분야여서 논문이 제한적이라는 점이 있음
Results
결론의 구성
- 핵심 원칙
- 핵심 원칙이 구체화된 컴포넌트 (기술적 구성 요소)
- 이를 실현하기 위한 역할(Roles)
- 위 요소들을 통합해 구성한 아키텍처 및 워크플로우 설계안
- MLOps 개념에 대한 정의와 개념화 도출
핵심 원칙 (Principle)
- MLOps 에서 원칙은 “무엇을 어떻게 구현해야 하는가” 에 대한 행동 지침.
| No | 원칙 | 설명 |
|---|---|---|
| P1 | CI/CD 자동화 CI/CD |
- 모델 개발과정의 빌드, 테스트, 배포 단계를 자동화 한다. - 각 단계에서 성공/실패 피드백을 신속히 제공해, 생산성을 향상시킨다. |
| P2 | 워크플로 오케스트레이션 Workflow Orchestration |
- DAG를 기반으로 ML 워크플로의 작업 순서와 의존성을 조율한다. - 자동화된 파이프라인 설계의 핵심 구성요소다. |
| P3 | 재현성 Reproducibility |
- 동일 실험을 다시 수행했을 때 동일한 결과를 도출할 수 있어야 한다. - 실험의 신뢰성과 품질 확보에 필수적이다. |
| P4 | 버전 관리 Versioning |
- 데이터, 모델, 코드에 대해 각각의 버전을 관리해야 한다. - 이를 통해 재현성을 확보하고, 규정 준수 여부에 대한 확인이 가능해야 한다. |
| P5 | 협업 Collaboration |
- 데이터, 모델, 코드에 대해 여러 Role 이 협업할 수 있는 환경이 조성되어야 한다. - 기술적 측면 뿐 아니라 소통 중심의 조직문화가 필요하다. - 도메인 간 사일로 현상을 해소하는 것을 목표로 한다. |
| P6 | 지속적인 ML 학습 및 평가 Continuous ML Training & Eval |
- 새로운 피처 데이터를 기반으로 주기적으로 재학습한다. - 모니터링, 패드백 루프, 자동화 파이프라인이 이를 지원해야 한다. - 재학습 시 성능 펴여가를 반드시 포함하도록 한다. |
| P7 | 메타데이터 추적 및 로깅 ML Metadata Tracking & Logging |
- 각 훈련 작업에 대해 학습 시간, 파라미터, 결과 성능, 모델 계보 등을 기록한다. - 이는 실험 재현성과 감사 가능성을 위한 필수 요소이다. |
| P8 | 지속적 모니터링 Continuous Monitoring |
- 데이터, 모델, 코드, 인프라, 서빙 성능 등을 지속적으로 점검한다. - 이를 통해 품질 저하나 오류를 조기에 탐지하도록 한다. |
| P9 | 피드백 루프 Feedback Loops |
- 품질 평가 결과를 다시 모델 개발이나 피처 엔지니어링 등 Upstream 단계로 합류시킨다. |
기술적 구성 요소 (Technical Components)
- Technical Components : 정의된 핵심 원칙들을 ML 시스템 설계에서 어떻게 구현할 수 있는지
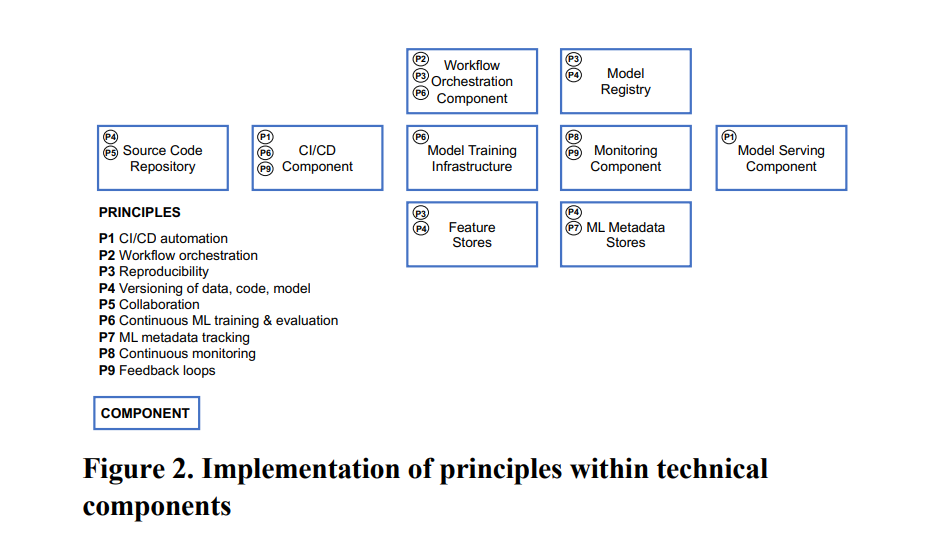
| No | 컴포넌트 | 설명 | 핵심원칙 |
|---|---|---|---|
| C1 | CI/CD - (CI/CD Component) |
- 모델 및 코드 자동 빌드/테스트/배포 - 지속적 통합, 전달, 배포를 보장함 - 개발자에게 성공/실패를 신속히 피드백해 생산성 향상 - 예시 도구 : Jenkins, Github Actions |
P1, P6, P9 |
| C2 | 소스 코드 저장소 (Source Code Repo) |
- 버전 관리, 협업 지원 - 코드 저장 및 버전 관리 기능 제공 - 여러 개발자가 동시에 코드 변경 가능 - 예시 도구 : GitHub, GitLab, BitBucket, Gitea |
P4, P5 |
| C3 | 워크플로 오케스트레이션 - (Workflow Orchestration -) |
- DAG 기반 파이프라인 조율 - DAG 기반 ML 파이프라인의 작업 순서와 의존성 조율 - 아티팩트 사용 흐름을 시각화하며 - 전체 ML 파이프라인 자동화 - 예시 도구 : Airflow, Kubeflow, SageMaker .. |
P2, P3, P6 |
| C4 | 피처 스토어 시스템 (Feature Store System) |
- 피처 중앙 저장 및 제공 - 공통적으로 사용하는 피처들을 중앙에서 저장 및 관리 - 오프라인 피처(실험용) 과 온라인 피처(실시간 추론용) 구성 - 예시 도구 : Google Feast, AWS Feature Store .. |
P3, P4 |
| C5 | 모델 학습 인프라 (Model Training Infra-) |
- 학습 환경 제공 - 모델 학습에 필요한 컴퓨팅 자원(CPU, RAM, GPU) 제공 - 분산/비분산 형태, 확장 가능한 클라우드 기반 인프라 등 - 예시 도구 : K8s, AWS, GCP, Azure .. |
P6 |
| C6 | 모델 레지스트리 (Model Registry) |
- 학습된 모델과 메타데이터를 저장소에 보관 - ML 아티팩트와 메타데이터를 동시에 관리 - 예시 도구 : MLflow, SageMaker Model Registrty .. |
P3, P4 |
| C7 | ML 메타데이터 저장소 (ML Metadata Store) |
- 각 워크플로 작업에 대한 메타데이터 기록 - 메타데이터는 학습일시, 성능, 파라미터 등 - 모델 계보 추적 가능해야 함 - 모델 계보에서는 사용된 데이터 코드도 추적 가능해야 함 - 예시 도구 : MLflow, Kubeflow, SageMaker Pipelines .. |
P4, P7 |
| C8 | 모델 서빙 컴포넌트 (Model Serving -) |
- 실시간 추론 또는 배치 추론을 지원 - 일반적으로 REST API 기반으로 구성되며 - 컨테이너화된 형태로 배포되는 게 보통 - 예시 도구 : Docker, K8s, Tensorflow Serving, SageMaker Endpoints .. |
P1 |
| C9 | 모니터링 컴포넌트 (Monitoring -) |
- 모델 서빙 성능과 인프라 지속 모니터링 - 예측 정확도, CI/CD, 오케스트레이션 등 - 시스템 오류 및 모델 이상 탐지 가능 - 예시 도구 : Prometheus, Grafana, MLflow, Kubeflow.. |
P8, P9 |
역할 (Roles)
- ML 시스템을 설계, 운영, 자동화, 프로덕션화 하는 데 필요한 역할과 협력에 대한 정의
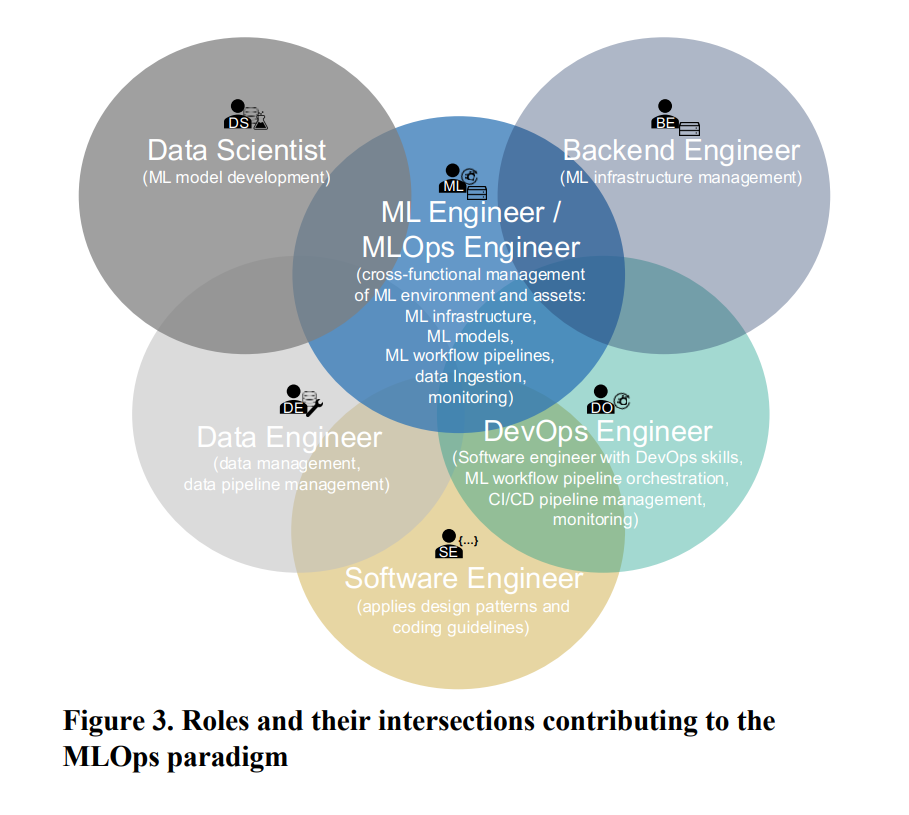
| No | 역할 | 설명 |
|---|---|---|
| R1 | 비즈니스 이해관계자 Business Stakeholder |
비즈니스 목표 정의, ROI 제시 - ML을 통해 달성할 비즈니스 목표를 정의함 - ROI 등 비즈니스 관점에서 성과를 커뮤니케이션 - 조직 내 이해관계자들과의 소통을 책임짐 - PO, PM 등 |
| R2 | 솔루션 아키텍트 Solution Architect |
기술 선정, 아키텍처 설계 - 전체 시스템 아키텍처를 설계 - 어떤 기술 스택을 사용할지 그술 선정 및 평가 - IT Architect 등 |
| R3 | 데이터 사이언티스트 Data Scientist |
모델 설계 및 학습 - 비즈니스 문제를 ML 문제로 변환 - 모델 엔지니어링 전담 (최적 알고리즘, 하이퍼파라미터) - ML 전문가, ML 개발자 |
| R4 | 데이터 엔지니어 Data Engineer |
데이터 파이프라인 구축, 피처 관리 - 데이터 및 피처 엔지니어링 파이프라인 구축 및 운영 - 피처 스토어의 데이터 적재를 책임 - DataOps Engineer 등 |
| R5 | 소프트웨어 엔지니어 Software Enginner |
ML 솔루션의 소프트웨어화 - ML 문제를 구조화된 소프트웨어 제품으로 구현 - 엔지니어링 품질 확보르 ㄹ위해 - 디자인 패턴, 코딩 규칙, 베스트 프랙티스 적용 |
| R6 | DevOps 엔지니어 DevOps Enginner |
CI/CD 자동화, 배포, 모니터링 - 개발과 운영의 간극을 해소 - CI/CD 자동화, 워크플로 오케스트레이션 - 프로덕션 배포, 모니터링.. |
| R7 | ML 엔지니어 MLOps 엔지니어 ML Engineer MLOps Enginner |
인프라/파이프라인 운영 및 종합 관리 - 다양한 역할의 전문성을 통합한 크로스 도메인 전문가 - DS, DE, SE, DevOps, BE 역할을 혼합 - ML 인프라 구축 및 운영 - 자동화된 ML 워크플로우 파이프라인 관리 - 모델 프로덕션 배포 및 성능/인프라 모니터링 |
아키텍처 및 워크플로우 Airchitecture and Workflow
- 원칙, 구성요소, 역할을 바탕으로 MLOps 를 구현하기 위한 일반화된 엔드 투 엔드 아키텍처
- ML 연구자와 실무자들에게 실질적인 가이드를 제공하는 데 목적
- 그리고 MLOps 전체 단계에 걸친 워크플로우 흐름도 함께 설명
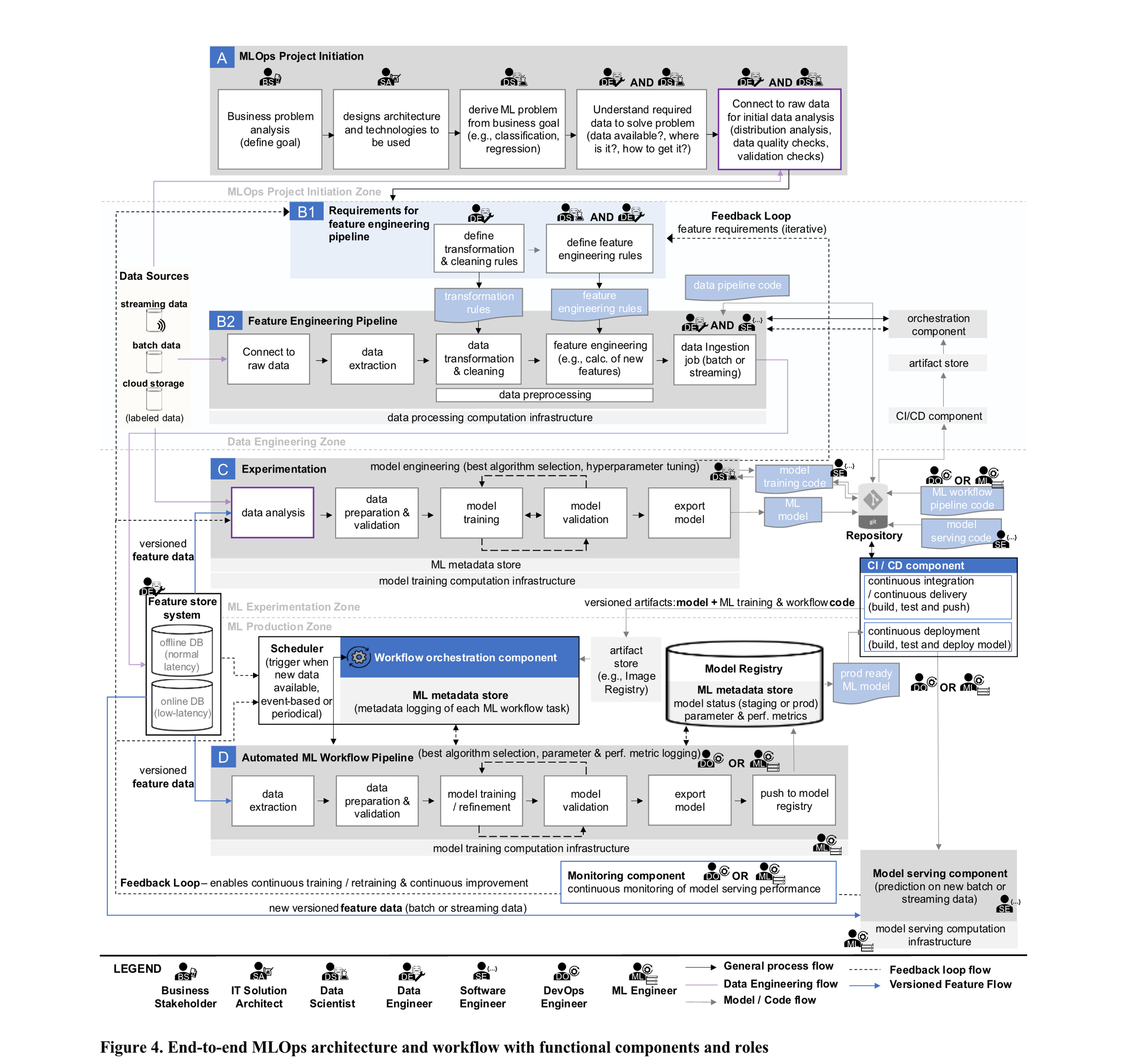
(A) MLOps 프로젝트 시작 단계
- 비즈니스 이해관계자(R1): 비즈니스 분석을 수행하고, ML을 통해 해결 가능한 문제를 정의한다.
- 솔루션 아키텍트(R2): 전체 ML 시스템의 아키텍처를 설계하고, 기술 스택을 선정한다.
- 데이터 사이언티스트(R3): 비즈니스 문제를 ML 문제로 변환한다 (예: 분류 vs 회귀).
- 데이터 엔지니어(R4) 및 R3: 어떤 데이터를 활용해야 할지 파악
- 함께 원시 데이터 소스 확인, 품질 분석, 검증 수행
(B1) 피처 엔지니어링 파이프라인 요구사항 정의
- R4: 데이터 정제/변환 규칙 정의 (정규화, 집계 등)
- R3 + R4: 새로운 파생 피처 정의 (계산식, 조합 규칙 등) 이 규칙들은 실험 단계나 모니터링 결과에 따라 지속적으로 조정된다
(B2) 피처 엔지니어링 파이프라인 구축
- R4 + R5: 앞서 정의된 규칙을 바탕으로 피처 엔지니어링 파이프라인 프로토타입 구축
- R4: 파이프라인의 오케스트레이션(C3) 및 CI/CD(C1) 설정
- 원시 데이터와 연결 (스트리밍, 배치, 클라우드 등)
- 데이터 추출
- 데이터 전처리 수행 (정제 및 변환)
- 고급 피처 계산
- 최종 데이터는 피처 스토어(C4)에 적재됨 (오프라인/온라인 DB 중 선택)
(C) 실험 (Experimentation)
- 주로 R3 가 주도하고, R5 가 지원한다.
- R3는 피처 스토어(C4) 또는 원시 데이터에 연결하여 분석 수행 필요한 데이터 조정이 있을 경우, 피드백 루프를 통해 R4에게 전달
- 훈련/테스트 분할 및 데이터 검증
- 최적의 알고리즘/하이퍼파라미터 선택 후 모델 학습 시작 (C5)
- 반복 실험을 통해 최적 조합 도출 (모델 엔지니어링)
- 최종 모델은 Export 후 코드 저장소에 커밋(C2)
⚙️ DevOps(R6) 또는 ML 엔지니어(R7)는 자동 ML 워크플로우(C2)의 코드를 작성해 저장소에 커밋 → CI/CD 컴포넌트(C1)가 이를 감지하고 자동으로 Build, Test, Delivery 단계 수행 → 결과물(artifact)은 아티팩트 저장소로 전달됨
(D) 자동화된 ML 워크플로우 파이프라인
- R6 + R7: 전체 파이프라인 관리 및 인프라(C5, 예: Kubernetes 등) 운영
- C3 오케스트레이터가 전체 작업 실행 및 메타데이터 수집
- 버전된 피처 자동 추출 (C4에서)
- 자동 데이터 준비 및 검증 (훈련/테스트 분할 포함)
- 사전 정의된 알고리즘 및 파라미터로 자동 학습
- 자동 모델 평가 및 필요 시 파라미터 조정
→ 반복 평가 후 성능이 만족스러우면 종료 - 모델 export
- 모델 레지스트리(C6)에 저장 (코드, 컨테이너, 환경파일 포함)
모든 학습 작업은 ML 메타데이터 저장소(C7)에 기록됨:
- 학습 파라미터, 성능 지표, 실행 시간, 모델 계보(lineage) 등
- 모델 버전, 상태(staging or production-ready) 포함
모델 배포 및 서빙
- 모델이 production-ready 상태가 되면 R6 또는 R7이 이를 배포
- CI/CD 컴포넌트(C1)가 배포 파이프라인 트리거
- 모델 및 서빙 코드 (R5가 작성한 코드 기반)를 가져와 빌드 및 테스트
- 모델은 프로덕션에 배포됨
모델 서빙 및 추론
- 모델 서빙 컴포넌트(C8)가 새 데이터에 대해 추론 수행
- 실시간 추론: 온라인 DB 기반, 낮은 지연 시간
- 배치 추론: 오프라인 DB 기반, 일반 지연 시간
- 대부분 REST API + 컨테이너 기반 애플리케이션
- R7은 서빙 인프라 운영 책임
모니터링 및 피드백 루프
- 모니터링 컴포넌트(C9)가 모델 성능 및 인프라를 실시간 모니터링
- 예측 정확도 저하 등 임계치 도달 시 알림 전송
- 피드백 루프(C9 → R3, R4 등):
- 실험 단계에 피드백 → 모델 개선
- 데이터 엔지니어링 영역에 피드백 → 피처 조정
- 개념 드리프트 발생 시, 재학습 트리거 (자동 or 주기적)
개념화 및 미해결 과제
개념화
MLOps 의 정의
- MLOps는 머신러닝 제품의 엔드-투-엔드 설계, 구현, 모니터링, 배포 및 확장성과 관련된 모범 사례(best practices), 개념 체계(sets of concepts), 그리고 개발 문화(development culture)를 포함하는 하나의 패러다임이다.
- MLOps 는 머신러닝, 소프트웨어 엔지니어링(+DevOps), 데이터 엔지니어링의 교차점에 위치한 개념이다.
MLOps 기반 핵심 분야
- 머신러닝(ML)
- 소프트웨어 엔지니어링 (특히 DevOps)
- 데이터 엔지니어링
미해결 과제
1) 조직적 과제 (Organizational Challenges)
| No | 과제 |
|---|---|
| 1 | - 많은 조직은 여전히 모델 중심 사고방식(model-driven) 에 머물러 있음 - 이를 제품 중심 사고방식(product-oriented mindset) 으로 전환해야 함 |
| 2 | - 최근은 데이터 중심 AI(Data-Centric AI) 흐름이 있음 - 따라서 모델 이전 단계인 데이터 품질과 설계 의 중요성이 강조되고 있음 |
| 3 | - MLOps 는 다양한 역할군을 필요로 하나, 저문 인재가 부족함 |
| 4 | - 데이터 사이언스 교육 과정에서는 MLOps 요소를 다루지 않음 |
| 5 | - 학생들은 모델 생성 뿐 아니라 ML 제품 구성 기술 및 구성요소도 배워야 할것 |
| 6 | - MLOps 는 DS 혼자 할 수 없으며, 다학제적 팀 기반 협업이 필요 |
| 7 | - 여전히 많은 팀들이 사일로(silo) 구조로 분리되어 협업이 어려움 - 전문 용어와 기술 격차로 커뮤니케이션 어려움 |
| 8 | - 의사결정권자들이 MLOps 성숙도와 제품 중심 관점에 대한 필요성 인식 필요 - 그리고 이들이 비즈니스 가치를 창출함을 이해하고 수용해야 함 |
2) ML 시스템적 과제
| No | 과제 |
|---|---|
| 1 | - 모델 학습은 수요 예측이 어렵고 데이터 변동량이 큼 - 따라서 CPU, RAM, GPU 등 인프라 요구량 추정이 어려움 - 따라서 시스템은 높은 수준의 유연성과 확장성을 가져야 함 |
3) 운영 과제 (Operational Challenges)
| No | 과제 |
|---|---|
| 1 | - ML 시스템은 다양한 SW, HW 스택이 얽혀있음 - 따라서 수동 운영은 복잡하므로, 강력한 자동화가 필수적임 |
| 2 | - 데이터가 지속적으로 유입되기에 재학습이 필수 - 이 또한 반복적이고 고도화된 자동화가 요구됨 |
| 3 | - 반복적인 작업에서 생성되는 아티팩트에 대해 - 거버넌스 체계 및 버전 관리를 통해 관리되어야 함 - 이는 데이터, 모델, 코드 모두에 해당함 |
| 4 | - 여러 컴포넌트와 역할이 얽혀 문제 발생 시 원인 파악에 어려움이 있음 |
Comments