
Reranker
Reranker 의 개념
- 처음 검색된 문서에 대해 다시 점수를 매기고 재정렬하는 과정
RAG 에서 Reranker 의 필요성
- RAG 는 LLM 의 단점 (환각, 비 최신성 등)을 보완하기 위함
- 특히 금융, 의료, 법률 등 정확성이 중요한 환경에서는 잘못된 정보가 큰 문제로 이어짐.
- 따라서 정보 검색의 품질을 높이는 것이 RAG 서비스의 품질을 결정하는 중요한 요인.
(1) 질문의 의도와 검색 결과의 관련성 검토
- 앞서 수행된 검색 결과가 질문의 실제 의도를 정확히 반영하지 못할 수 있음
- 따라서 질문의 의도와 관련성이 높은지 재검토, 재정렬이 필요
(2) LLM 에 검색 결과를 적절한 순서대로 제공
- LLM에 검색 결과를 제겅할 때, 관련성 높은 정보가 앞단에 있을 수록 답변 품질 좋음
- 중요한 정보가 중간에 있으면, LLM 이 이를 제대로 반영하지 못하는 Lost in the Middle 현상이 발생
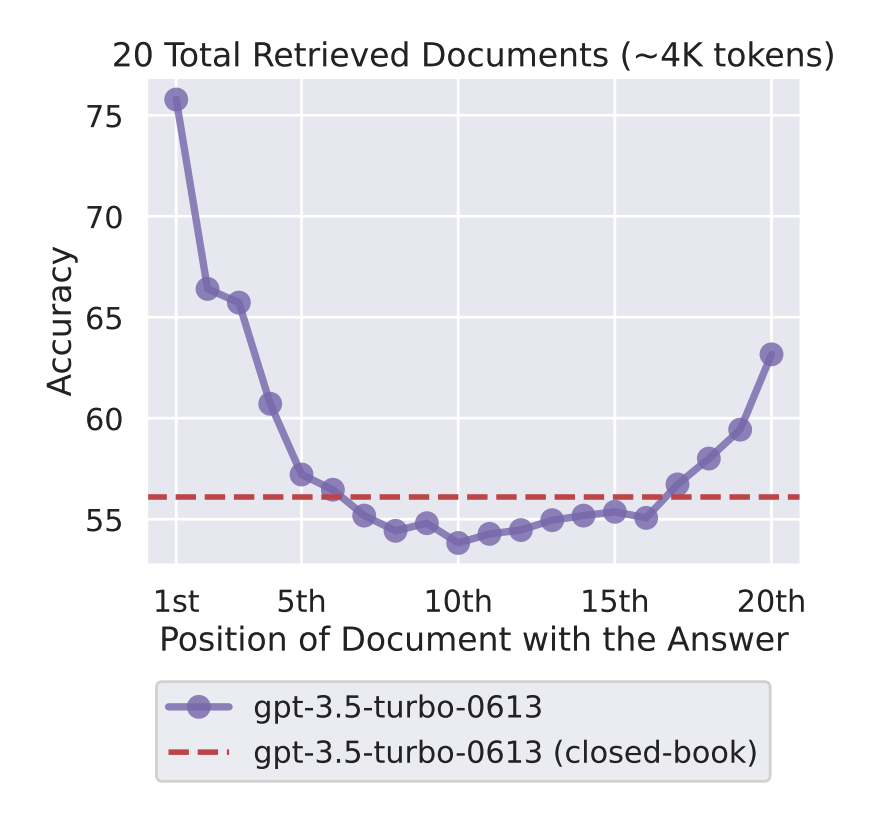
참고 : Lost in the Middle
언어 모델이 주어진 정보를 어떻게 활용하는지 분석한 논문에서 나온 개념 관련 정보가 앞이나 뒤에 있을 때 성능이 좋으며, 중간에 있을 때 성능이 최악
Lost in the Middle: How Language Models Use Long Contexts
Reranker 의 목표
- 검색 결과의 정확도, 질문과의 관련성을 높이기 위함
- 또한 관련성이 높은 자료를 앞 순위에 배치
Reranker 의 종류
Reranker 의 종류
- 1️⃣ Cross-Encoder 방식
- 2️⃣ LLM as a Reranker 방식
1️⃣ Cross-Encoder 방식
- 가장 전통적인 리랭킹 방식 중 하나
- 질의(Query)와 문서(Documents)를 하나의 문맥으로 결합해 모델(보통 BERT)에 입력으로 제공하고
- 이를 통해 질의와 문서 사이의 정확한 맥락적 연관성을 세밀하게 파악해 보다 정밀한 평가를 하는 방식
Bi-Encoder 와 Cross-Encoder
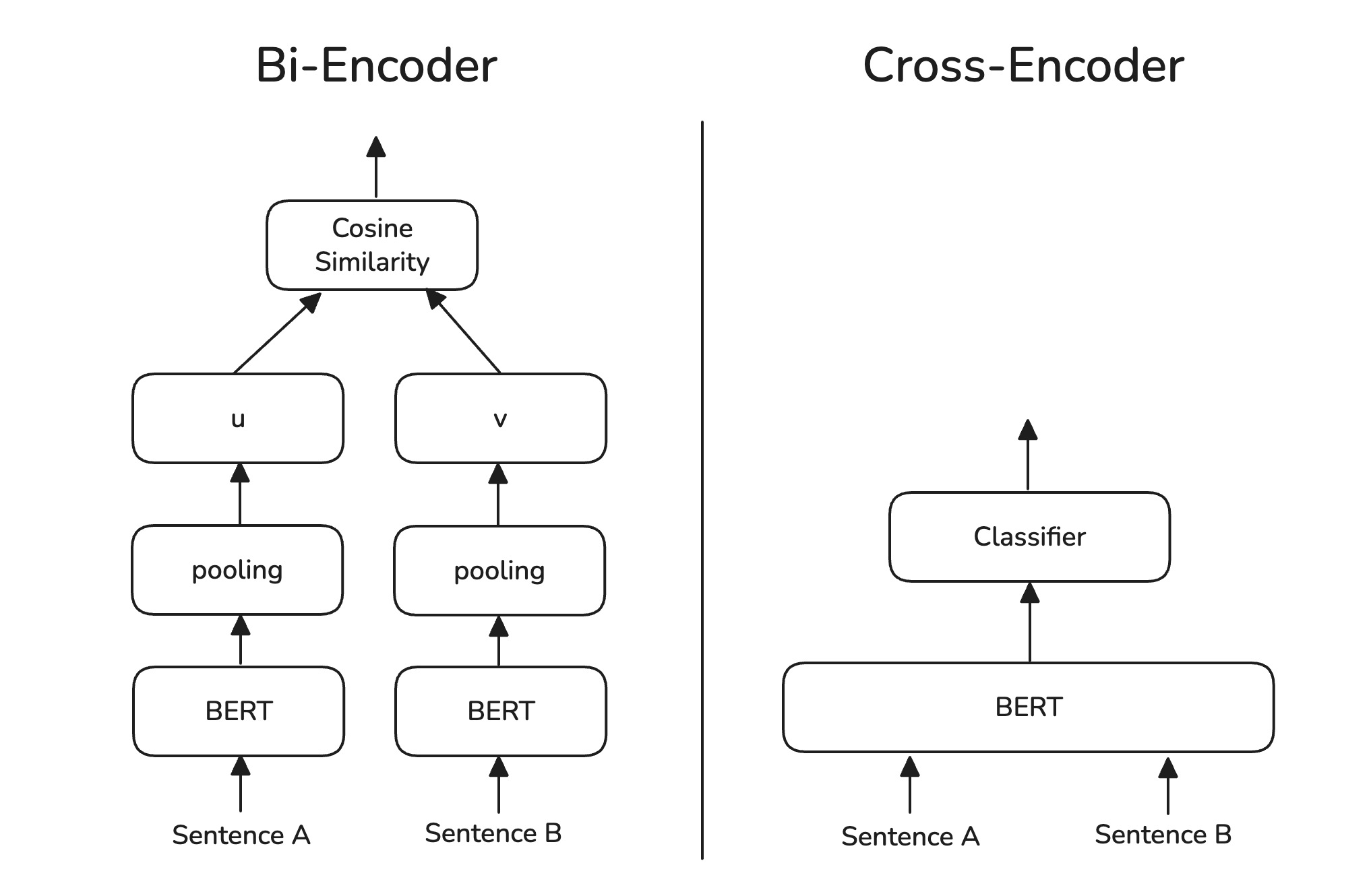
- (1) Bi-Encoder
- Bi-Encoder 는 질문과 문서에 대해 독립적으로 임베딩을 수행
- 미리 임베딩을 하여 벡터를 저장해놓은 뒤, 검색시에 유사도 비교 수행
- 미리 임베딩이 되어있고, 유사도 계산만 하면 되므로 속도가 빠름
-
일반적인 Retriever에서 벡터 검색의 동작 원리에 해당
- (2) Cross-Encoder
- Cross-Encoder 는 질문과 문서를 결합해 하나의 입력으로 임베딩 수행
- 질문과 문서를 동시에 분석함으로써 Bi에 비해 더욱 정확한 유사도 측정 가능
- 수행시 임베딩을 해야하므로 속도가 느림
- 전통적인 Reranking 작업 동작 원리에 해당
애초에 검색시 Cross-Encoder 방식을 사용하면 Reranker 가 없어도 되지 않을까?
- 애초에 Cross-Encoder로 검색을 수행하면 처음부터 관련성 높은 문서 얻을 수 있음
- 하지만 Cross-Encoder 는 질문과 모든 문서들 간의 임베딩과 유사도 계산이 요구됨
- 이 연산은 유사도 계산만 하는 Bi-Encoder 에 비해 굉장히 오래 걸림
- Sentence-BERT 에서는 4천만개 문서에 대해 V100 GPU기반으로 수행했을 때 약 50시간이 소요 된다고 보고함.
- 따라서 처음부터 많은 문서에 대한 검색을 Cross-Encoder로 수행하는 것은 사용성과 효율성이 떨어짐
Two-Stage 전략
- 따라서 RAG 에서는 2단계 전략(Two-Stage)를 적용함
- 1단계 - 검색시 : 속도가 빠른 Bi-Encoder 로 많은 질의와 후보 문서간 유사도 비교
- 2단계 - 리랭킹 : Cross-Encoder로 검색해온 문서들과 질의 사이 관련성 재평가
- Milvus에서 취한 양자화 + 정제기 전략과 유사
2️⃣ LLM as a Reranker
- LLM 자체를 리랭커로 활용해, 질의와 후보 문서들간 관계성을 직접 평가
- 대표적으로 Pointwise 방식과 Listwise 방식
- 장점1 Zero-shot 리랭킹 가능 : 사전 학습 없이도 리랭킹 가능
- 장점2 복잡한 언어 패턴과 은유, 추론 등 고차원 언어 능력 활용 가능
- 단점 : 아직까지는 실시간 답변이 어려워 사용이 제한적
(1) Pointwise
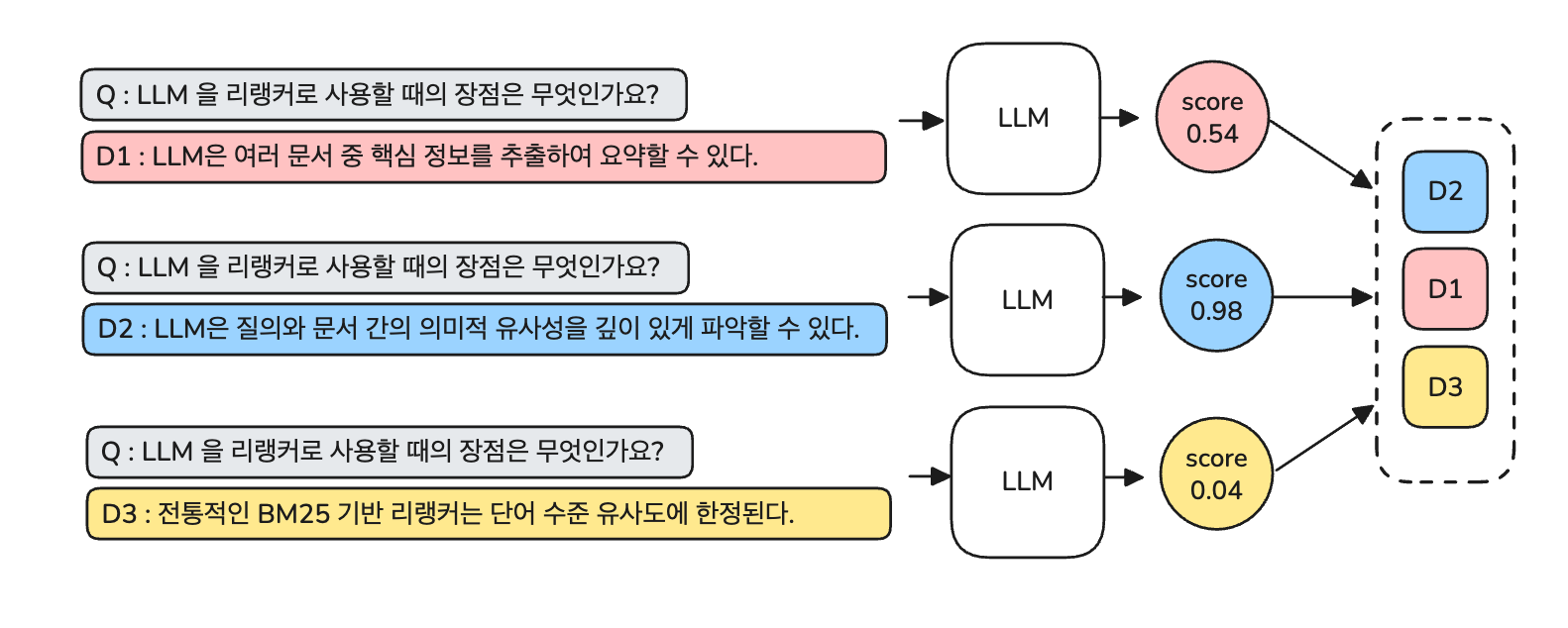
- 각각의 후보 문서를 독립적으로 평가해 관련성 점수를 매긴다.
- 관련성 점수를 매기는 방법은 아래 두 가지 방법이 있다.
- LLM 의 토큰 생성 확률값을 이용한다.
- LLM에게 직접 점수를 산출해달라고 한다.
1. 토큰 생성 확률값을 이용
- 이 경우, 확률값은 LLM이 사용자가 요청한 단어를 생성할 확률을 이용한다.
- LLM에게 문서가 주어진 질의에 적절한 참조 문서인지 Yes 또는 No로 답변하도록 요청한 뒤,
- Yes로 분류될 확률 p를 관련성 점수로 사용하는 것이다.
- 이 때의 확률 p 는 LLM이 출력 토큰을 생성할 때 내부적으로 계산하는 log probability 기반으로 계산한다.
- LLM 에게 보내는 프롬프트는 아래와 같이 구성할 수 있다.
- 이후 나올 실습 코드를 통해 확인하면 이해하기 쉽다.
1
2
3
prompt = "참조 문서가 주어진 쿼리에 대한 적절한 답변인지 Yes 또는 No로 답변하세요."
query = "LLM은 리랭커로 어떻게 활용될 수 있나요?"
document = "Retriever는 질문에 대한 후보 응답을 생성하는 역할을 한다."
log probability
LLM 이 생성할 다음 토큰에 대한 확률분포P(Wt | Context)를 뜻함
Softmax 함수를 통해 얻어지며, log probability 값으로도 제공 가능
2. LLM에게 직접 점수 산출 요청
- 앞의 방식보다 비교적 간단한 방식이다.
- LLM에게 문서가 주어진 질의에 적절한 참조 문서인지 X점 만점으로 평가해달라고 한다.
- 그리고 평가 점수를 관련성의 척도로 삼아 리랭킹을 하는 방법이다.
1
2
3
prompt = "참조 문서가 주어진 쿼리에 대한 적절한 답변인지 100점 만점으로 관련성을 평가해주세요."
query = "LLM은 리랭커로 어떻게 활용될 수 있나요?"
document = "Retriever는 질문에 대한 후보 응답을 생성하는 역할을 한다."
(2) Listwise
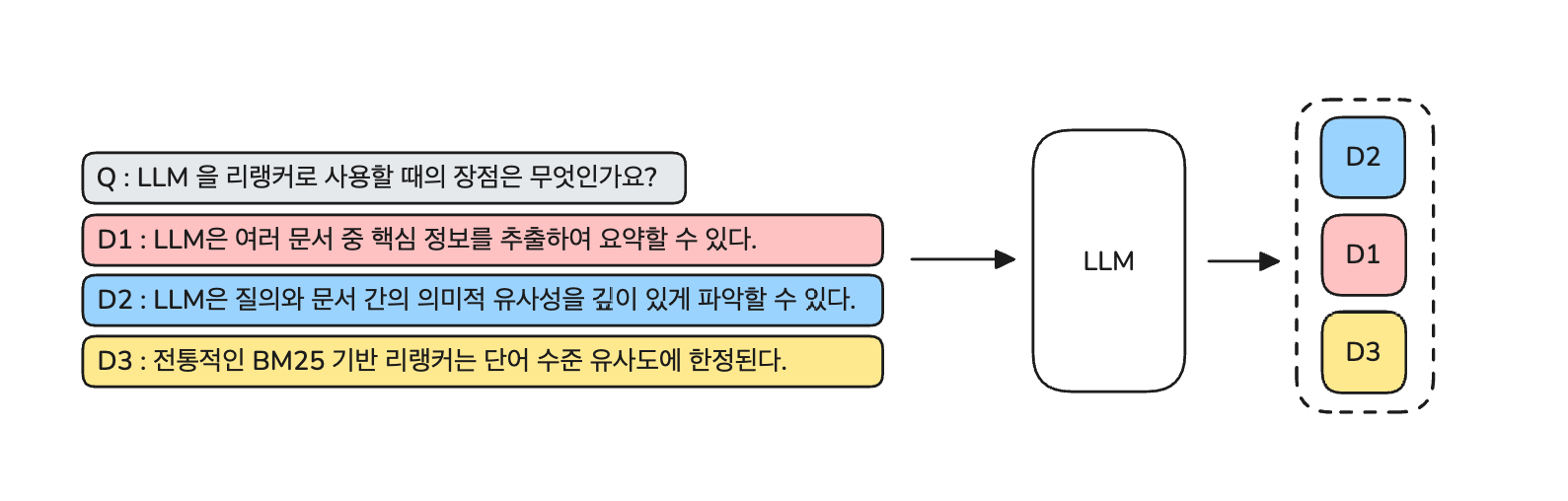
- Listwise 는 Pointwise와 달리 참조문서를 모두 한 번에 LLM에게 제공한다.
- 한 번에 제공한 후, 전체 후보 문서를 관련성에 따라 순서를 재정렬 해달라고 요청한다.
1
2
3
4
5
6
7
prompt = "아래 문서들을 주어진 쿼리와의 관련성이 높은 순서대로 순위를 매겨 답변하세요."
query = "LLM은 리랭커로 어떻게 활용될 수 있나요?"
documents = '''
[A] LLM은 인간 수준의 의미 이해를 기반으로 질문과 문서 간의 깊은 연관성을 파악할 수 있다.
[B] Retriever는 질문과 유사한 벡터를 기준으로 문서를 추출한다.
[C] Cross-Encoder는 질의와 문서를 함께 처리해 높은 정확도를 보인다.
'''
- Listwise는 별도의 확률 계산 없이 LLM 이 출력으로 준 순서대로 문서를 리랭킹하면 되어 편리함
- 하지만 LLM 은 처리할 수 있는 토큰 수에 제한이 있으므로, 한 번에 평가할 수 있는 문서 수가 제한됨
- 이를 극복하고자 슬라이딩 윈도우 방식을 사용하기도 함
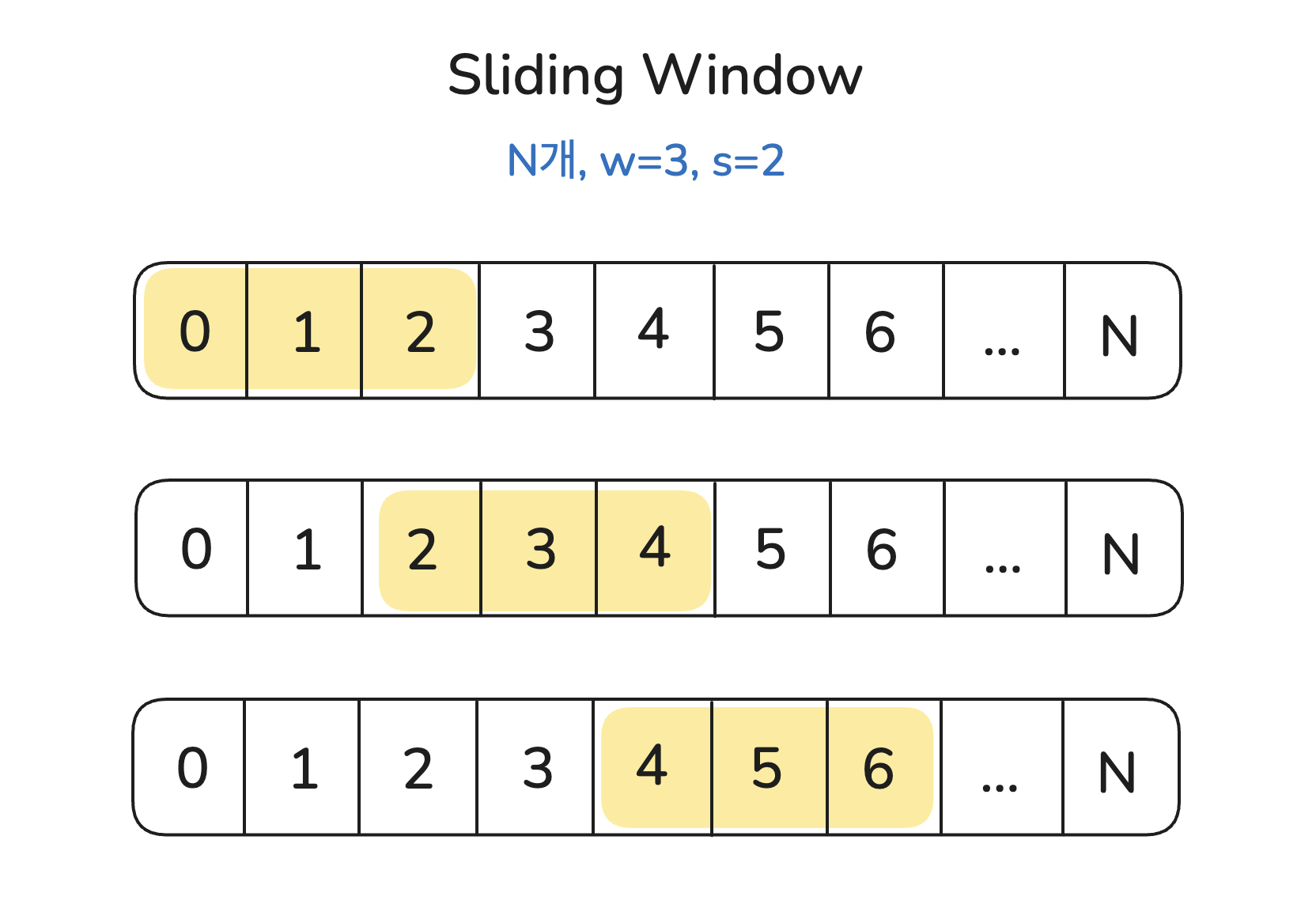
슬라이딩 윈도우(Sliding Window) 방식
-전체 N 개의 후보 문서들이 있다고 가정할 때
-윈도우 크기 w, 스텝 크기 s로 이동하며 점진적으로 리랭킹
비교
| 항목 | Pointwise | Listwise |
|---|---|---|
| 평가 방식 | 각 문서를 개별적으로 평가하여 관련성 점수 부여 | 전체 문서 집합을 함께 입력하여 순위를 매김 |
| LLM 입력 | 쿼리 + 단일 문서 | 쿼리 + 복수 문서 (리스트 전체) |
| 출력 형식 | 관련성 점수 또는 “Yes/No” | 관련 문서 순서 (예: A > C > B) |
| 장점 | - 세밀한 점수 산정 가능 - LLM 토큰 확률 활용 가능 |
- 직관적인 결과 출력 - 문서 간 상대 비교에 최적화 - 추가 점수 해석 없이 바로 순위 생성 가능 |
| 단점 | - 문서 간 상대 비교가 어려울 수도 있음 - 토큰 확률 계산 해석 필요 |
- 토큰 수 제한 있음 - 문서 수가 많을수록 처리 어려움 |
실습
실습 내용
- 탐색한 Reranking 방식을 직접 수행하봄
- Cross-Encoder 방식, LLM as a Reranker 방식 실습
- Cross-Encoder : Huggingface에 있는 BAAI/bge-reranker-v2-m3 모델
- LLM as a Reranker : OpenAI ChatGPT API 사용
리랭킹 질의 및 검색 결과 문서 데이터셋
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
query = 'LLM을 리랭커로 사용할 때 장점은 무엇인가요?'
search_documents = [
"[1] LLM은 여러 문서 중 핵심 정보를 추출하여 요약할 수 있다.",
"[2] 사전학습된 LLM은 다양한 도메인 지식에 기반한 추론이 가능하다.",
"[3] LLM은 질의와 문서 간의 의미적 유사성을 깊이 있게 파악할 수 있다.",
"[4] LLM은 기존 리랭커보다 더 복잡한 문맥을 이해할 수 있는 능력을 갖고 있다.",
"[5] LLM은 Zero-shot 환경에서도 강력한 관련성 판단을 수행할 수 있다.",
"[6] Cross-Encoder 방식의 LLM은 질문과 문서를 동시에 고려한다.",
"[7] LLM은 사용자 질의의 숨겨진 의도까지 파악해 정교한 평가가 가능하다.",
"[8] 전통적인 BM25 기반 리랭커는 단어 수준 유사도에 한정된다.",
"[9] Transformer 기반 구조는 멀티턴 질의에도 높은 정확도를 보인다.",
"[10] 기존 Cross-Encoder는 유연성에서 LLM에 비해 제한적이다.",
"[11] LLM은 구조화되지 않은 자유 문장도 효과적으로 분석할 수 있다.",
"[12] LLM은 질의와 문서 간의 상호작용을 문맥 수준에서 학습한다.",
"[13] 단어 일치보다 의미 일치에 기반한 리랭킹이 가능하다.",
"[14] LLM은 복잡한 개념 연결 관계도 이해할 수 있다.",
"[15] 기존 리랭커는 사전 정의된 feature에 의존하는 경우가 많다.",
"[16] LLM은 이전 학습 데이터 외의 질문에도 유연하게 대응한다.",
"[17] LLM은 하나의 프롬프트로 여러 유형의 판단을 수행할 수 있다.",
"[18] 사용자의 질문 의도와 답변 사이의 간극을 줄이는 데 효과적이다.",
"[19] 대규모 파라미터를 가진 LLM은 문맥 분별력이 뛰어나다.",
"[20] LLM은 수치 기반 점수보다 자연어 기반 판단에 더 적합하다.",
]
Cross-Encoder 방식
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-v2-m3')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-v2-m3')
model.eval()
# 질의와 문서를 하나의 리스트에 묶어 준비
# 아래에서 각각의 질의-문서 쌍이 하나의 입력으로 결합됨
pairs = [[query, document] for document in search_documents]
# (1) 질의와 문서를 결합하여 하나의 텍스트로 토크나이징
# (2) padding 및 truncation을 적용하여 모델 입력 형식으로 변환
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float() # 질의와 문서가 얼마나 관련 있는지 점수(logit)를 계산
# score 기준 관련성이 높은 순서대로 정렬해서 출력
# score 가 높을수록 질의와 문서 간 관련성이 높다는 의미
# 양수 : 관련성 있음 / 0 근처 : 중립적이거나 관련성 불확실 / 음수 : 관련성이 낮거나 없음
sim_score_result = [[sentence, score] for sentence, score in zip(search_documents, scores)]
sim_score_result = sorted(sim_score_result, key=lambda x:x[1], reverse=True)
sim_score_result
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 결과
[4] LLM은 기존 리랭커보다 더 복잡한 문맥을 이해할 수 있는 능력을 갖고 있다. tensor(1.5858)
[19] 대규모 파라미터를 가진 LLM은 문맥 분별력이 뛰어나다. tensor(-3.5372)
[7] LLM은 사용자 질의의 숨겨진 의도까지 파악해 정교한 평가가 가능하다. tensor(-4.7256)
[15] 기존 리랭커는 사전 정의된 feature에 의존하는 경우가 많다. tensor(-4.9283)
[20] LLM은 수치 기반 점수보다 자연어 기반 판단에 더 적합하다. tensor(-5.3553)
[1] LLM은 여러 문서 중 핵심 정보를 추출하여 요약할 수 있다. tensor(-5.3571)
[10] 기존 Cross-Encoder는 유연성에서 LLM에 비해 제한적이다. tensor(-5.4176)
[17] LLM은 하나의 프롬프트로 여러 유형의 판단을 수행할 수 있다. tensor(-5.8128)
[11] LLM은 구조화되지 않은 자유 문장도 효과적으로 분석할 수 있다. tensor(-5.8304)
[16] LLM은 이전 학습 데이터 외의 질문에도 유연하게 대응한다. tensor(-5.8559)
[5] LLM은 Zero-shot 환경에서도 강력한 관련성 판단을 수행할 수 있다. tensor(-6.0521)
[13] 단어 일치보다 의미 일치에 기반한 리랭킹이 가능하다. tensor(-6.1061)
[3] LLM은 질의와 문서 간의 의미적 유사성을 깊이 있게 파악할 수 있다. tensor(-6.5490)
[2] 사전학습된 LLM은 다양한 도메인 지식에 기반한 추론이 가능하다. tensor(-6.7263)
[8] 전통적인 BM25 기반 리랭커는 단어 수준 유사도에 한정된다. tensor(-6.8096)
[14] LLM은 복잡한 개념 연결 관계도 이해할 수 있다. tensor(-7.3066)
[6] Cross-Encoder 방식의 LLM은 질문과 문서를 동시에 고려한다. tensor(-7.8556)
[12] LLM은 질의와 문서 간의 상호작용을 문맥 수준에서 학습한다. tensor(-8.0627)
[18] 사용자의 질문 의도와 답변 사이의 간극을 줄이는 데 효과적이다. tensor(-8.6381)
[9] Transformer 기반 구조는 멀티턴 질의에도 높은 정확도를 보인다. tensor(-10.2660)
LLM as a Reranker 방식
Poinstwise
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# openai 0.28 버전 사용. (1.0 이상은 logprobs 옵션 사라짐)
import openai
import dotenv
import os
import math
env_path = '/Users/jongya/Desktop/github/shopping_llm_recommendation/lab/reranker/jupyter/.env'
dotenv.load_dotenv(env_path)
openai.api_key = os.getenv('OPENAI_API_KEY')
def pointwise(query, document):
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "질문과 문서 간 관련성 판단해 Yes 나 No 중 하나로 답변하세요."},
{"role": "user", "content": f"질문: {query} 문서: {document}"}
],
logprobs=True, # 핵심 옵션!
max_tokens=10
)
return response['choices'][0]['logprobs']
# 로그 확률 값 확인
result_list = []
for document in search_documents:
logprobs = pointwise(query = query, document = document)
# 답변 (Yes / No)
reply = logprobs['content'][0]['token'] if logprobs['content'][0]['token'] != '\\xeb\\x8b' else 'No'
# Yes = 1 / No = -1
sign = 1 if logprobs['content'][0]['token'] == 'Yes' else -1
# 확률값 p = e^log(p)
p = math.exp(logprobs['content'][0]['logprob'])
# 결과 적재
result_list.append([
document,
reply,
p,
p * sign
])
# 결과 정렬
result_list = sorted(result_list, key=lambda x:x[3], reverse=True)
# 출력
for result in result_list:
print(result[0], result[3])
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 결과
[3] LLM은 질의와 문서 간의 의미적 유사성을 깊이 있게 파악할 수 있다. 0.9999998063873693
[4] LLM은 기존 리랭커보다 더 복잡한 문맥을 이해할 수 있는 능력을 갖고 있다. 0.999999448776502
[13] 단어 일치보다 의미 일치에 기반한 리랭킹이 가능하다. 0.999999448776502
[7] LLM은 사용자 질의의 숨겨진 의도까지 파악해 정교한 평가가 가능하다. 0.999999091165777
[19] 대규모 파라미터를 가진 LLM은 문맥 분별력이 뛰어나다. 0.9999989719621736
[5] LLM은 Zero-shot 환경에서도 강력한 관련성 판단을 수행할 수 있다. 0.9999984951481292
[12] LLM은 질의와 문서 간의 상호작용을 문맥 수준에서 학습한다. 0.9999984951481292
[6] Cross-Encoder 방식의 LLM은 질문과 문서를 동시에 고려한다. 0.9999858596583402
[2] 사전학습된 LLM은 다양한 도메인 지식에 기반한 추론이 가능하다. 0.9999720323248966
[17] LLM은 하나의 프롬프트로 여러 유형의 판단을 수행할 수 있다. 0.9997378641193743
[10] 기존 Cross-Encoder는 유연성에서 LLM에 비해 제한적이다. 0.9992882983079844
[20] LLM은 수치 기반 점수보다 자연어 기반 판단에 더 적합하다. 0.9980715604067301
[11] LLM은 구조화되지 않은 자유 문장도 효과적으로 분석할 수 있다. 0.9975256269669018
[18] 사용자의 질문 의도와 답변 사이의 간극을 줄이는 데 효과적이다. 0.9959293105107246
[14] LLM은 복잡한 개념 연결 관계도 이해할 수 있다. 0.9820125102859462
[16] LLM은 이전 학습 데이터 외의 질문에도 유연하게 대응한다. 0.7772967623259942
[15] 기존 리랭커는 사전 정의된 feature에 의존하는 경우가 많다. -0.817571080607408
[1] LLM은 여러 문서 중 핵심 정보를 추출하여 요약할 수 있다. -0.9241343417785254
[9] Transformer 기반 구조는 멀티턴 질의에도 높은 정확도를 보인다. -0.9914205538951522
[8] 전통적인 BM25 기반 리랭커는 단어 수준 유사도에 한정된다. -0.9992891321213027
Listwise
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
import openai
import dotenv
import os
import math
env_path = '/Users/jongya/Desktop/github/shopping_llm_recommendation/lab/reranker/jupyter/.env'
dotenv.load_dotenv(env_path)
openai.api_key = os.getenv('OPENAI_API_KEY')
def listwise(query, documents:str):
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=[
{"role": "system", "content": '''아래 문서들을 주어진 쿼리와의 관련성이 높은 순서대로 순위를 매겨 답변하세요.
(1) 별다른 설명은 넣지 마세요.
(2) 주어지는 모든 문서(20개)에 대해 순서를 매겨 답변해야 합니다.
(3) [20] > [10] > [9] 와 같이 답변하세요.'''},
{"role": "user", "content": f"질문: {query} \n\n 문서: \n{documents}"}
],
max_tokens=1000
)
return response['choices']
# 넣을 문서 텍스트로 변환
documents = ''
for document in search_documents:
documents += document + '\n'
# 리랭킹 요청
result = listwise(query, documents)
# 결과
result[0]['message']['content']
1
2
3
4
# 출력
[20] > [1] > [2] > [3] > [4] > [5] > [6] > [7] > [8] >
[9] > [10] > [11] > [12] > [13] > [14] > [15] > [16] >
[17] > [18] > [19]
Reference
https://devocean.sk.com/blog/techBoardDetail.do?ID=167335&boardType=techBlog
Lost in the Middle: How Language Models Use Long Contexts
https://wikidocs.net/253434
https://aws.amazon.com/ko/blogs/tech/korean-reranker-rag/
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Comments