
RAG 에서 검색의 정확도를 높이는 방법
RAG
- Retrieval-Augmented Generation 검색 증강 생성
- 모델이 학습하지 않은 외부 데이터를 실시간으로 검색(retrieval) 하고
- 이를 바탕으로 답변을 생성(generation) 하는 것
- 목표 : 기존 LLM 의 한계를 극복하고자 함
| 구분 | 기존 LLM | RAG 를 이용 |
|---|---|---|
| 신뢰성 | -학습된 데이터를 기반으로만 답변하는 한계 따라서, 허위 정보(할루시네이션) 제공할 수 있음 |
외부의 신뢰할 수 있는 지식 소스를 인용 따라서 신뢰할 수 있는 정보를 바탕으로 답변 |
| 최신성 | 학습한 과거 데이터 기반 답변만 가능 | 최신의 정보를 (준)실시간으로 검색해 답변에 사용 |
| 도메인 특화 | 학습하지 않은 분야에 대한 지식이 부족 | 새로운 분야의 자료로 지식 범위 보완 가능 |
| 응답 투명성 | 답변의 출처나 근거 제공이 어려움 | 응답 기반에 사용된 문서 출처 확인 가능 |
| 효율성 | 지식을 추가하기 위해 모델 학습 필요 -> 비용 | 외부에 지식 저장소를 둬, 모델이 상대적으로 작아도 됨 |
RAG 의 단계
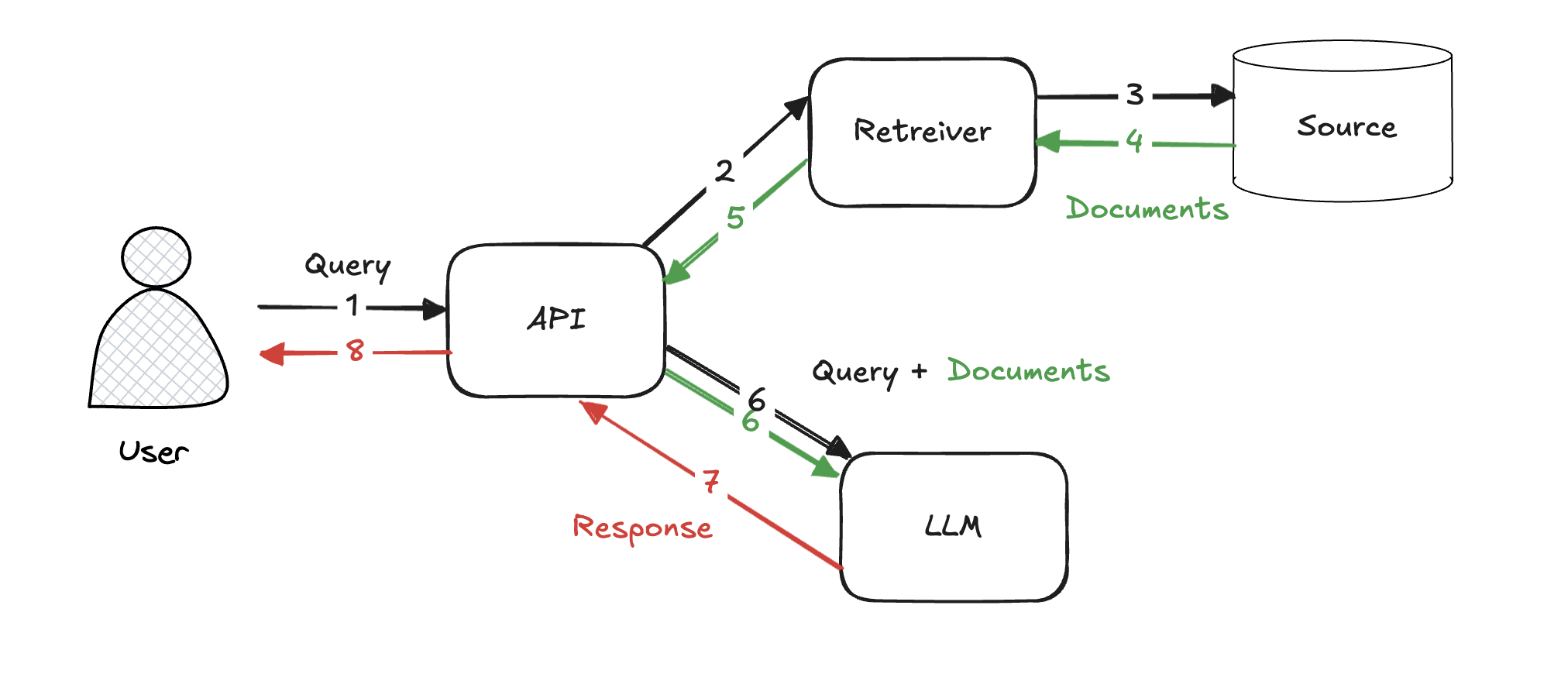
(1) 검색 단계 Retrieval Phase
- 사용자의 질문이나 컨텍스트를 기반으로 외부 데이터를 검색하는 단계
- 데이터베이스나 정보 저장소 등 다양한 소스로부터 필요한 정보를 찾아낸다.
- 검색된 데이터는 사용자의 질문에 대한 적합한 답변을 만들기 위해 정확하고 상세한 정보여야 한다.
(2) 생성 단계 Generation Phase
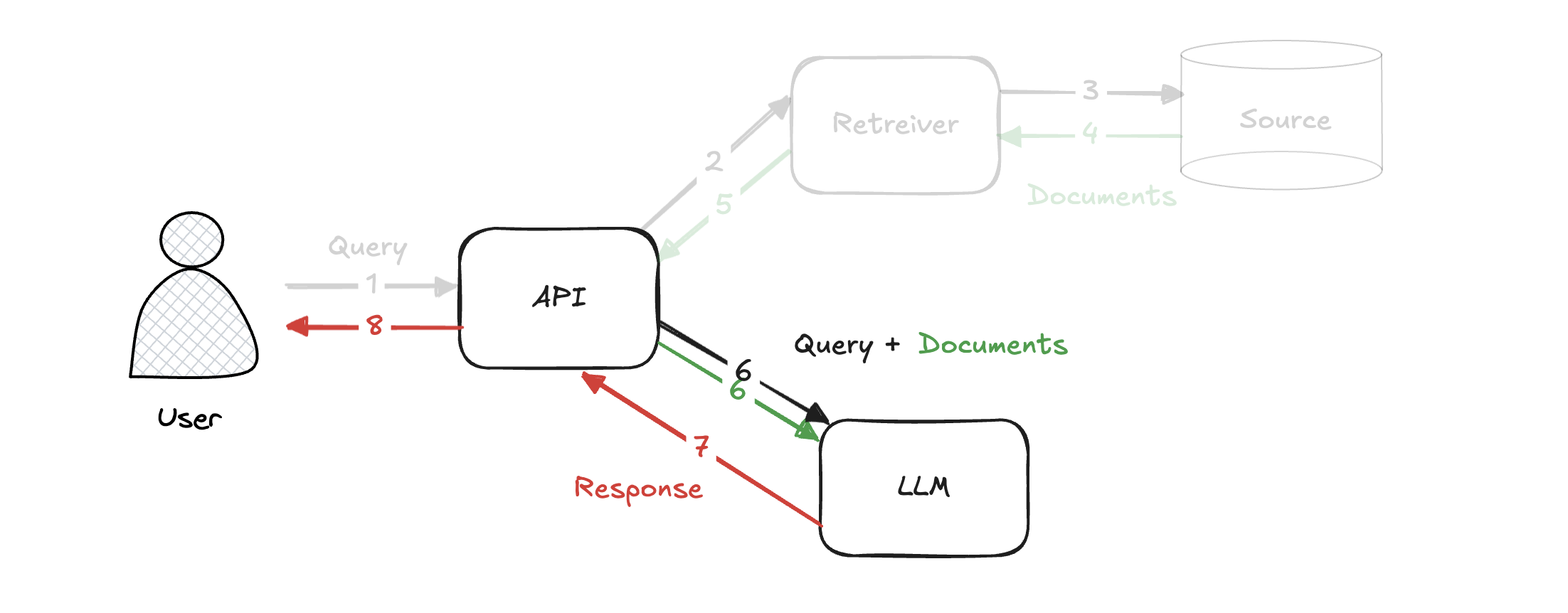
- 검색된 데이터를 보강 자료(Augmented) 로 활용해 LLM 모델이 사용자 질문에 답변을 생성하는 단계
- 검색 단계에서 검색된 데이터와, LLM이 기존에 학습한 지식을 결합해 답변을 생성한다.
Retrieval Phase
Retrieval Phase 의 순서와 구성 요소
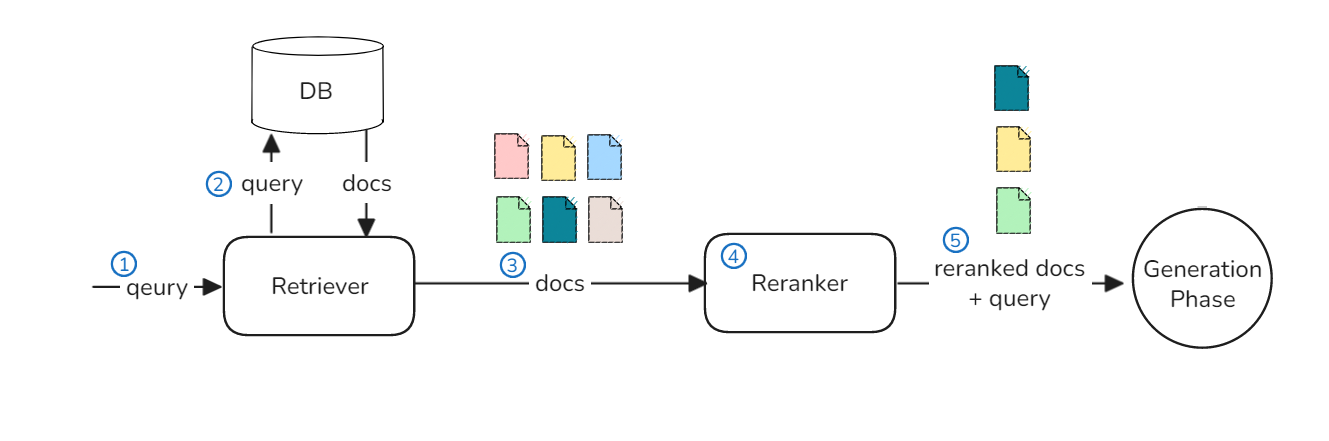
(1) Retriever 가 질의를 받음
(2) 참고 문서들이 저장된 저장소에 질의로 검색을 수행하고, 관련 있는 문서를 받아옴
(3) 검색된 문서들을 Reranker 에 보냄
(4) Reranker 에서는 받은 문서들로 Reranking 작업을 수행
(5) Reranking 작업을 통해 재정렬/선별 된 문서들을 Generation Phase로 넘김
1. Retriever

어원과 정의
- Retrieve
1 : 다시 찾거나 발견하다. 원래는 “사냥꾼이 상처입힌 사냥감을 찾아 가져다주다.” 의 의미
2 : “저장된 정보를 다시 얻다.” “검색하다.” 와 같은 의미는 1962년부터 사용됨. - Retriever
1 : 죽거나 부상당한 사냥감을 찾고 가져오는 데 특별히 적합한 품종의 개
2 : 질문에 대한 답변을 찾기 위해 데이터베이스나 정보 저장소에서 관련 문서를 검색하는 검색기
Retriever의 목표
- 사용자의 질문에 대해 관련성이 높은 문서들을 검색하여 반환
- RAG 에서는 reranker 와 대비해 “빠르게 검색” 한다는 특성을 가짐
2. Reranker

어원과 정의
- Reranking
1 : 다시 순위를 매기다
2 : 2000년대 초 IR(정보 검색) 분야에서부터 오랫동안 사용되어왔던 말 - 처음 검색된 문서에 대해 다시 점수를 매기고 재정렬하는 과정
Reranker의 목표
- 검색 결과의 정확도, 질문과의 관련성을 높이기 위함
- 또한 관련성이 높은 자료를 앞 순위에 배치
- 단순한 정렬(sorting)의 개념이 아니라, 후처리 기반의 성능 개선 알고리즘
- RAG 에서는 Retriever 와 대비해 비교적 느리지만 정밀한 관련성 평가를 한다는 특성을 가짐
Reference
https://www.etymonline.com/search?q=retrieve
https://www.etymonline.com/word/retriever
https://wikidocs.net/233779
https://aclanthology.org/J05-1003.pdf
https://devocean.sk.com/blog/techBoardDetail.do?ID=167335&boardType=techBlog
Comments