
확률분포에 기반한 분류의 개념
새로운 데이터 Xnew 가 어떤 클래스에 속하는지를 판단하는 기준으로, 그 데이터가 각 클래스로부터 생성되었을 확률 P(Ci|Xnew) 을 계산하고, 그 중 가장 큰 확률을 가지는 클래스로 분류를 하는 것이다.
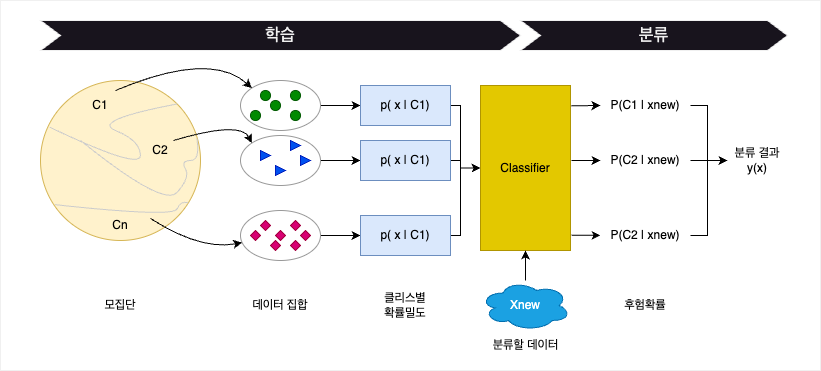
| 요소 | 설명 |
|---|---|
| 모집단 | 분류 주제와 관련된 현실 세계에 있는 데이터 |
| 데이터 집합 | 분류 모델 학습을 위해 추출된 데이터. 표본집합. |
| 클래스별 확률밀도 | 데이터가 각 클래스에 속할 확률 |
| classifier | 학습 데이터로부터 얻어진 클래스별 확률밀도를 통해 구축한 분류기 |
| Xnew | 학습데이터에 포함되지 않은, 분류가 필요한 새로운 데이터 |
| 후험확률 | 새로운 데이터가 각 클래스에 속할 확률 |
| 분류결과 | 새로운 데이터가 어느 클래스에 속하는지 예측한 결과 |
확률분포 기반 분류의 이진분류 예시
클래스에 속할 확률을 계산하는 판별함수
이진 분류란, 하나의 특징벡터 x 가 입력으로 주어졌을 때, 이 데이터가 서로 다른 두 클래스 C1과 C2 중 어느 클래스에 속할지 결정(예측)하는 것이다. 이를 위해서는 x가 각 클래스에 속할 확률을 알아야 하며, 따라서 C1에 속할 확률인 P(C1 | x) 와 C2에 속할 확률인 P(C2 | x)를 계산할 수 있어야 한다.
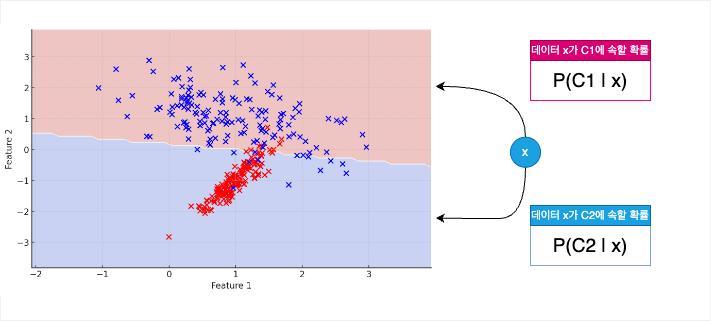
그림을 통해 조금 더 쉽게 이해해보자. 어느 클래스에 속하는지 아직 모르는 값 x에 대해 확률을 기반으로 분류를 진행하기 위해서는 값 x가 각 클래스에 속할 확률이 필요한 것이다. 그것을 간단하게 지칭하고자 x가 C1에 속할 확률은 P(C1 | x), x가 C2에 속할 확률은 P(C2 | x)라고 하는 것이다.

P(C1 | x) 가 P(C2 | x) 보다 큰 경우엔 데이터 x 가 C1 클래스로 분류되며, 그 반대의 경우에는 C2 클래스로 분류될 것이다. 이를 함수로 나타낸다면 판별함수 g(x) = P(C1 | x) - P(C2 | x)로 나타낼 수 있다. 판별함수 기준으로는 g(x) 의 출력값이 0보다 큰 경우에는 C1 클래스로, 반대의 경우에는 C2 클래스로 분류되는 것이다.
판별함수와 결정함수
-판별함수 : 데이터가 어떤 클래스에 속할 가능성이 높은지 판별하는 함수. 주로 확률적 분류 모델(베이즈, LDA 등)에서 많이 사용된다.
-결정함수 : 모델이 학습한 결정 경계를 바탕으로 새로운 데이터가 어느 클래스에 속하는지 결정하는 함수. 특히 비확률적 분류 모델(SVM, 로지스틱 회귀 등)에서 많이 사용된다.
선험확률과 후험확률
하지만 P(C1 | x)나 P(C2 | x)와 같이 새로운 데이터 x가 각 클래스에 속할 확률은 바로 계산할 수 없는 값이다. 이는 위의 두 확률 계산이 “후험 확률”이기 때문이다.
| 구분 | 뜻 |
|---|---|
| 선험 확률 Prior Probability |
- 어떤 사건이 발생하기 전에 기존 지식이나 경험, 또는 기존의 통계를 바탕으로 추정한 확률. - 새로운 데이터나 정보가 주어지기 전의 초기 확률로, 사전 확률이라고도 한다. |
| 후험 확률 Posterior Probability |
- 새로운 데이터나 정보가 반영되어 갱신된 확률. - 선험 확률에 더해, 관측된 정보를 적용해 업데이트된 확률 - 사후 확률이라고도 한다. |
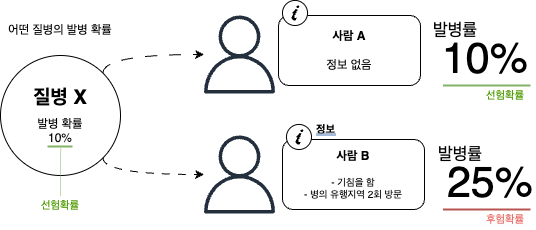
예를 들어서, 어떤 질병의 발병률이 10%라고 가정해본다면, 기존의 경험과 통계를 바탕으로 계산된 발병 선험 확률은 10%라고 할 수 있다. 여기에 어떤 사람이 병의 증상을 보일 경우 그 사람이 병에 걸렸을 확률이 바로 후험 확률이다.
여기서 주의해야할 점은, 그냥 사람 A가 병에 걸릴 확률이 후험 확률이 아니라는 것이다. A가 병에 걸릴 확률운 선험 확률인 10%와 동일하다. 후험 확률이란 선험 확률에 더해, 특정한 정보나 증거가 주어졌을 때, 그 정보에 따라 확률을 갱신하는 값을 의미하는 것이기 때문이다. 발병율을 예로 들자면 사람 A가 병의 증상을 보였다거나, 병이 유행한 지역에 2회 방문했다거나 하는 등의 것이 확률값을 갱신하는 “정보”가 되는 것이며, 이러한 정보가 주어졌을 때 갱신된 사람 A의 발병 확률이 바로 후험 확률이다.
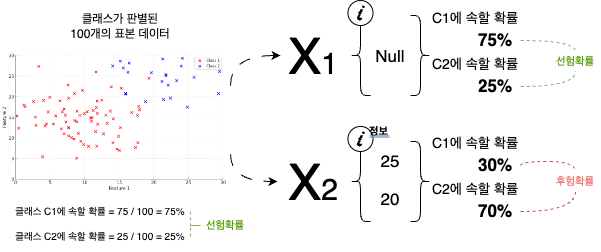
다시 분류 문제로 돌아와보자. 먼저 주어진 1,000개의 데이터가 있고, 이 중 750개는 C1 클래스에 속하고, 250개는 C2 클래스에 속한다고 해보자. 그렇다면 C1 클래스에 속할 선험 확률은 75%, C2 클래스에 속할 선험 확률은 25% 이다.
여기에 새로운 데이터 x가 추가되어 어느 클래스에 속하게 될지 분류를 기다리고 있다. (불가능하지만) 데이터 x가 분류와 관련된 아무런 정보도 가지고 있지 않으면, 분류의 확률은 선험 확률만이 계산될 수 있다.
그런데 이 데이터 x가 feature1=25 이라는 값과 feature2=20이라는 값 즉, “정보(특성)”를 가지고 있다면, 이 정보(특성)를 바탕으로 x가 어느 클래스에 속할지 “후험 확률”을 계산할 수 있는 것이다. 이 후험 확률을 구하는 방법은 다음 섹션에서 알아볼 것이다.
베이즈 정리를 이용한 분류 결정규칙 도출
다시 앞으로 돌아가서, 판별함수는 g(x) = P(C1 | x) - P(C2 | x) 와 같이 나타낼 수 있고, 판별함수를 이루는 P(C1 | x), P(c2 | x)는 후험확률이기 때문에 바로 계산을 할 수 없다고 했다.
그렇다면 x를 분류하기 위한 후험확률 계산 방법은 무엇일까? g(x) 를 베이즈 정리를 이용하여 다시 정리하면 아래와 같다.
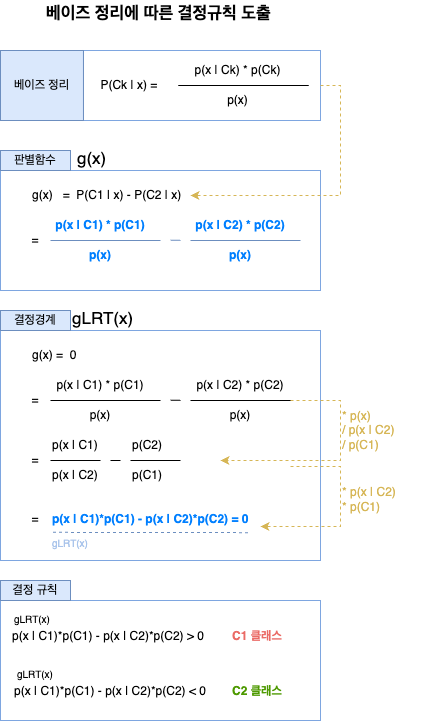
베이즈 분류기와 우도비 분류
앞서 정리한 결정경계를 기반으로 새로운 데이터 x의 클래스를 분류하는 것이 바로 베이즈 분류기의 원리이다. 베이즈 분류기의 핵심을 하나 더 짚어보기 위해 앞서 정리한 결정경계의 식을 다시 보면 아래와 같다.
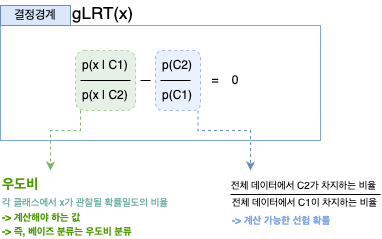
우도비라는 것은 각 클래스에서 x가 관찰될 확률밀도의 비율을 계산함으로써 얻을 수 있는데, 이 우도비에 의해 이뤄지는 분류를 우도비 분류라고 하며, 또한 후험확률에 대한 베이즈 정리로부터 유도된 것이므로 이 결정경계를 이용해 분류하는 것을 이진 분류 문제를 위한 베이즈 분류기라고 한다.
확률밀도함수
확률밀도함수란 연속 확률 분포에서 특정 값이 나타날 가능성을 설명하는 함수로, 쉽게 말해 어떤 값 근처에서 데이터가 얼마나 밀집해 있는지를 나타내는 함수이다. 확률이 아닌 밀도를 나타내는 것으로, 함수 값이 높다는 것은 해당 구간에 데이터가 많다는 뜻이고, 함수 값이 낮은 부분은 데이터가 적다는 의미이다.
-확률밀도함수는 확률이 아니라 밀도를 나타낸다.
-확률밀도함수의 값이 높으면 데이터가 많고, 낮으면 데이터가 적은 것이다.
-확률 밀도 함수를 적분하면 값이 1이 되도록(=데이터가 어디에나 존재할 수 있도록)한다.
-즉, 전체 구간 밀도의 합은 1이 되어야 한다.
클래스간 데이터량 비율
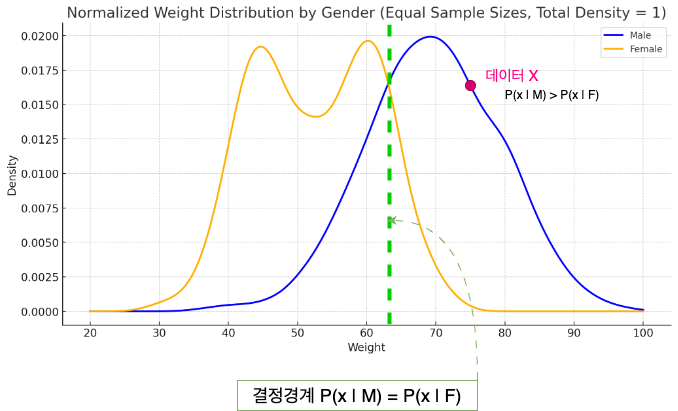
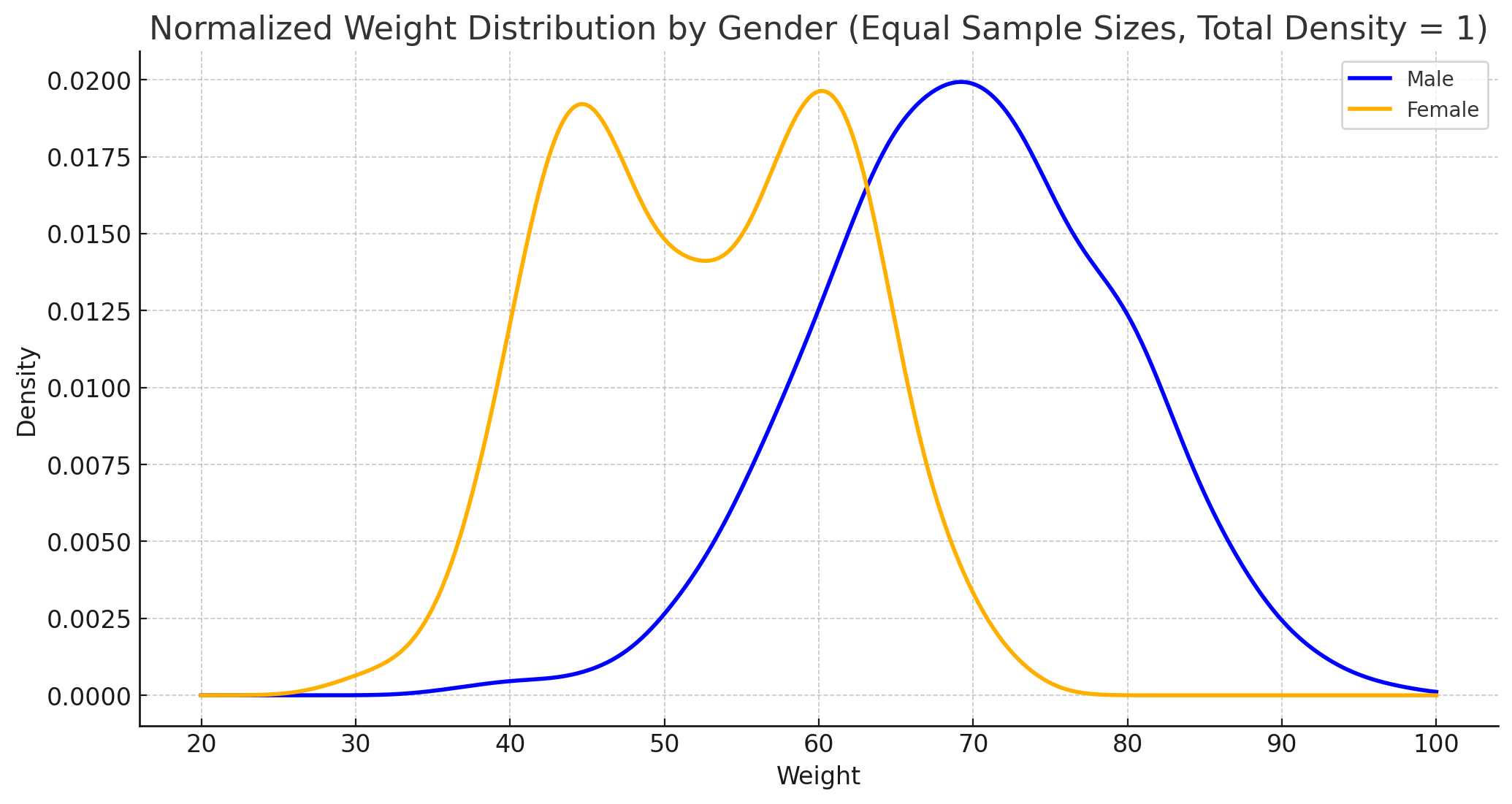
이제 베이즈 분류기는 우도비 분류기라고 볼 수 있으며, 우도비는 각 클래스의 확률밀도함수의 비율로 구할 수 있음을 알게 되었다. 위 그래프는 체중에 대한 확률분포 그래프로, 가상의 데이터를 남성과 여성 두 클래스로 나누어 표현한 것이다.
이 그래프는 각 클래스의 데이터 수가 동일하다는 전제 하게 작성한 것으로, 각 클래스의 수가 동일할 경우에는 베이즈 분류기의 p(C2)/p(C1) 부분이 1이 되면서, 우도비에만 의한 분류가 된다. 따라서 각 클래스의 데이터 수가 동일한 경우엔 결정함수를 p(x | C1) - p(x | C2) = 0 이라고 할 수 있으며, 결정경계면은 p(x | C1) = p(x | C2) 라고 할 수 있다.
그래프에서 데이터 x는 80 ~ 90kg 사이의 값을 가진 1차원 데이터로, 이 구간에 대한 남성 클래스의 확률밀도함수의 값이 여성 클래스의 확률밀도함수의 값보다 많으므로, 남성으로 분류되는 것이 이번 포스팅 확률분포에 따른 분류의 결과값이 될 것이다.
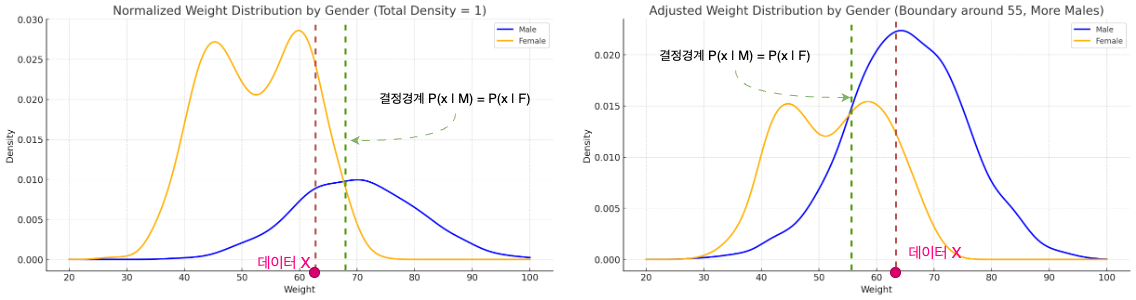
만약 각 클래스의 데이터 수에 불균형이 있다면, 각 클래스에 속한 데이터 수의 비율도 분류 결과에 영향을 미치는 주요한 원인이 된다. 즉, 데이터 수의 불균형이 커질 수록 베이즈 분류기의 선험확률 부분의 영향력이 커지게 되는 것이다.
위 그래프는 각각 여성의 데이터가 많은 경우, 남성의 데이터가 많은 경우의 그래프들이다. 각 클래스 내의 분포가 같은 모양을 가지고 있더라도, 클래스간의 데이터량 차이에 의해 결정경계가 달라짐을 볼 수 있다. 즉, 베이즈 분류기는 확률밀도와 함께 클래스에 속한 데이터 수의 영향도 함께 받음을 그래프를 통해 명확하게 살펴볼 수 있다.
수식으로 나타낸다면, 두 클래스 간 데이터 수가 동일하다고 했을 때의 결정경계면을 p(x | C1) = p (x | C2) 라고 해보자. 만약 C1 클래스에 속한 데이터량이 C2 클래스에 속한 데이터량의 2배라고 하면, 결정경계면은 p(x | C1)p(C1) = 0.5 * p(x | C2)p(C1) 이 된다.
확률분포 기반 분류의 다중분류 예시
이제 어려운 개념과 설명은 끝났다. 이진 분류의 원리를 이해한다면 다중(3개 이상) 분류 또한 동일한 원리이므로 이해하기 쉬울 것이다.
이진 분류에서는 각 클래스에 대한 판별함수가 결정경계면의 이상인지 이하인지, 바꿔서 말해 p(x | C1) * p(C1)과 p(x | C2) * p(C2) 중 어떠한 값이 더 큰지에 따라 클래스 분류를 하였다.
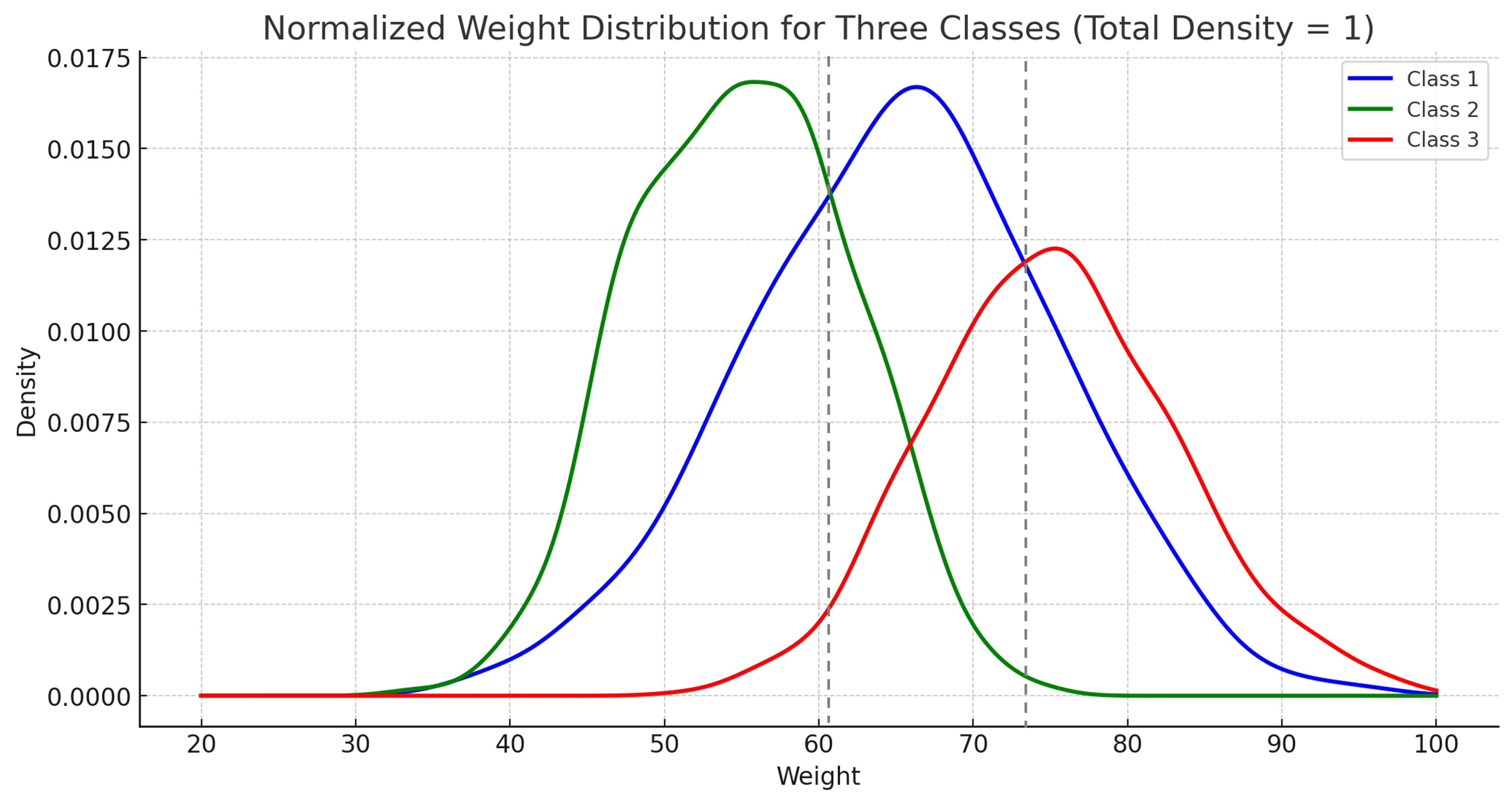
이러한 함수 p(x | Ci) * p(Ci)를 클래스 i에 대한 판별함수라고 했을 때, 다중 클래스 분류의 경우 또한 이진분류와 동일하게 데이터 x에 대한 각 클래스의 판별함수 값 중 “가장 큰 값”을 가지는 클래스를 x의 클래스로 도출하게 된다. 이를 수식으로 나타내면 아래와 같다.
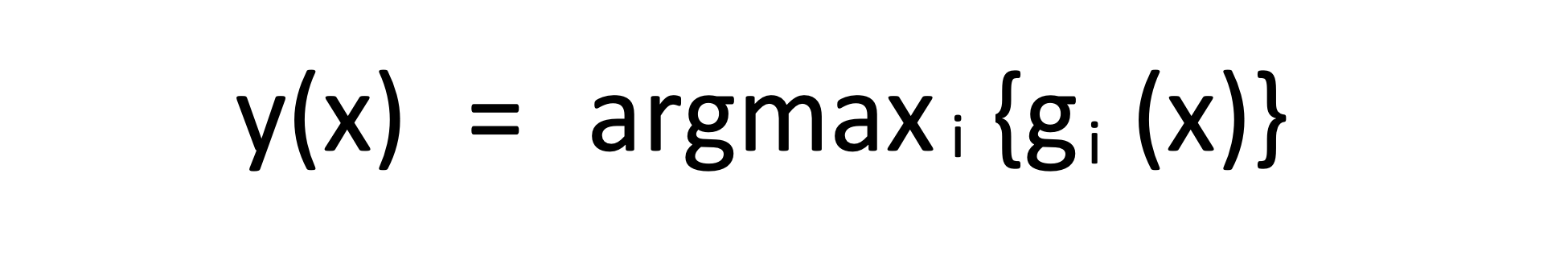
분류기의 오분류 확률과 최소 오류확률 결정경계
분류기의 오분류 확률
- 오류 : 주어진 입력 x가 어떤 클래스에 속할지 판단할 때, 그 판단이 잘못되어 실제와는 다른 클래스로 할당하는 경우
- 오류 확률(probability of error) : 결정경계를 이용해 얻어진 결정규칙이 오류를 일으킬 확률
- 결정영역 Ri : 판별함수에 따라 정해진 결정규칙에 따라, 클래스 Ci에 대응되는 영역
오류의 경우와 전체 오류
이진 분류를 예로 들었을 때에는 두 가지 경우의 오류가 있을 수 있다.
(1) 클래스 C1에 속하는 데이터 x 를 클래스 C2에 속한다고 판단하는 경우
=> rob{x∈R2, x∈C1}
(2) 클래스 C2에 속하는 데이터 x 를 클래스 C1에 속한다고 판단하는 경우
=> Prob{x∈R1, x∈C2}
그리고 전체 오류 Perr는 두 오류를 더한 값으로 나타낼 수 있다.
Perr = Prob{x∈R2, x∈C1} + Prob{x∈R1, x∈C2}
확률밀도함수 그래프에서 보는 오류
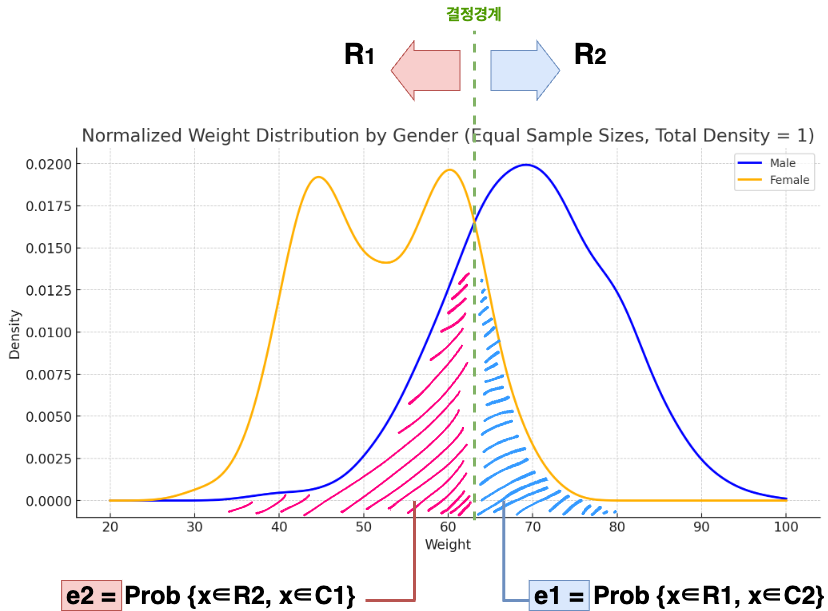
오류는 확률밀도함수 그래프에서 살펴봤을 경우에 더 쉽게 이해할 수 있다. 두 가지 오류 중 첫 번째인 Prob{x∈R2, x∈C1} 는 데이터 중 C1 클래스에 속하는 데이터가 R2에 속할 확률이고, 이는 곧 결합확률밀도함수 p(x, C1) 을 영역 R2상에서 적분한 값이 된다. (그래프에서는 분홍색으로 칠해진 영역) 결합확률밀도함수 p(x, C1)이란, 데이터 x가 주어졌을 때, 그 데이터가 C1에 속할 확률을 의미한다. 따라서 p(x, C1)은 아래와 같이 다시 정리할 수 있다.
p(x, C1) = p(x | C1) * P(C1)
p(x | C1): 클래스 C1이 주어졌을 때, 데이터 x가 관측될 확률p(C1): 전체 데이터에서 클래스 C1의 비율(=전체 데이터 중 C1에 속할 확률)
위에서 재정리한 수식을 이용해 전체 오류율을 정의해보자면 Prob{x∈R2, x∈C1} 는 위 수식의 R2 영역에서의 적분값이 되고, Prob{x∈R1, x∈C2} 는 p(x | C2) * P(C2) 의 R1 영역에서의 적분값이 되므로, 최종적으로 확률밀도함수에서의 전체 오류율은 아래와 같이 정리할 수 있다.
즉 전체 오류율은, 전체 C1의 비율 * C1의 결정영역 R1에서 발생하는 오분류 면적 + 전체 C2의 비율 * C2의 결정영역 R2에서 발생하는 오분류 면적으로 정의할 수 있다.
다중 클래스일 경우
앞서 확률밀도함수 그래프를 이용해 이진분류에서 전체 오류율의 수식을 정리하였다. 전체 오류율을 구할 수 있다는 것은, 정분류율(옳게 분류할 확률) 또한 구할 수 있다는 말과 같다. 클래스가 세 개 이상인 다중 클래스일 경우에는 오류확률보다는 정분류 확률(알맞게 분류할 확률)을 생각하는 편이 더 쉽다.
다중분류에서 오분류을은 “클래스 Ci에 속하는 데이터 x가, Ci클래스의 결정영역 Ri가 아닌 영역에서 보일 확률” 이라고 정의할 수 있으므로, 그 반대인 정분류율은 "클래스 Ci에 속하는 데이터 x가, Ci클래스의 결정영역 Ri에서 보일 확률" 이라고 정의할 수 있다. 이를 수식으로 정리하면 아래와 같다.
최소 오류확률 결정경계
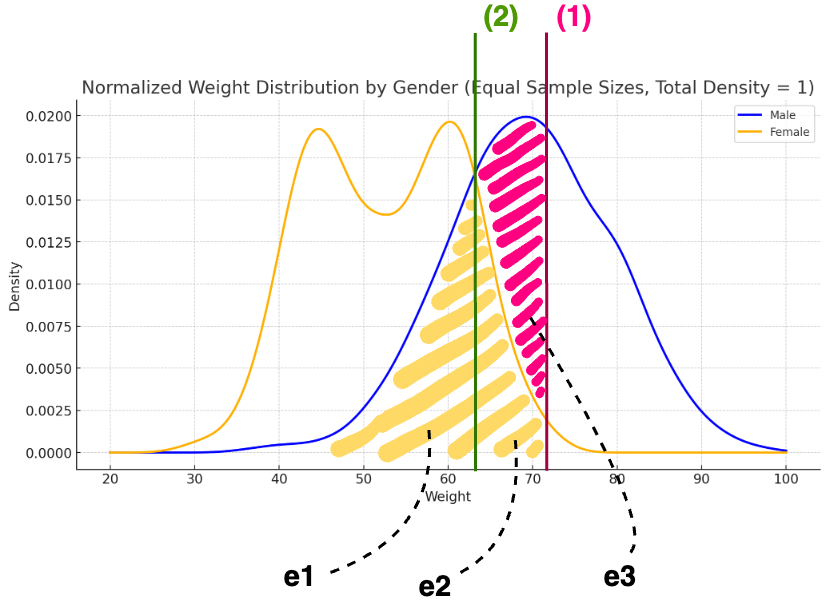
오류확률을 계산할 수 있는 경우, 이를 이용해서 오류확률을 최소로 하는 결정경계를 찾을 수 있을 것이다. 쉬운 이해를 위해 위 그래프를 살펴보면, (1) 일 때의 오류 확률보다 (2) 일 때의 오류 확률이 적은 것을 볼 수 있으며, 오류를 최소화할 수 있는 지점은 바로 두 확률밀도함수의 곡선 p(x | C1)과 p(x | C2)가 만나는 곳임을 알 수 있다.
- (1) 에서의 오류율 : e1 + e2 + e3
- (2) 에서의 오류율 : e1 + e2
최소 오류확률을 갖는 결정경계는 베이즈 분류기에 의해 얻어지는 결정경계가 되고, 이 때 발생하는 오류확률을 베이즈 오류율이라고 한다.
최소 오류확률을 갖는 결정경계 => 베이즈 분류기에 의해 얻어지는 결정경계
최소 오류확률을 갖는 결정경계에서 발생하는 오류확률 => 베이즈 오류율
Comments