
분류의 개념
분류
분류는 지도학습의 하나로, 주어진 데이터 집합에 대해 이미 정의된 몇 개의 클래스로 입력데이터를 구분짓는 문제를 뜻한다.
지도학습
학습 데이터의 집합이 {{x1, y1}, {x2,y2} … {xn, yn}}의 형태로 주어지며, 특징벡터 xi를 입력받아 원하는 출력yi로 매핑하는 함수를 찾는 학습 시스템. 즉, 입력데이터 xi에 대한 출력데이터 yi를 예측하는 함수를 찾는 학습 시스템.
분류의 예시
분류 모델은 숫자인식, 얼굴인식, 사물인식, 이미지 분류 등의 인식 문제가 대표적인 주제이다.

분류기
분류 문제를 다루는 학습 시스템을 지칭하는 말. 베이즈 분류기, K-최근접이웃 분류기 등이 있다.
분류의 학습 목표
최적의 결정경계를 찾아 분류율을 최대화하거나, 분류 오차를 최소화하는 것이 분류의 학습 목표이다.
분류율
주어진 결정경계를 이용해 분류를 수행했을 때, 전체 데이터 중 분류에 성공한 데이터의 비율
결정경계 (Decision Boundary)
학습 데이터 집합의 분포 특성을 분석하여, 데이터들을 클래스로 분류를 하는 기준 경계를 지칭하는 말. 최적의 결정경계를 얻기 위해 데이터의 분포 특성을 분석하는 방법을 머신러닝에서는 “학습” 이라고 지칭한다.
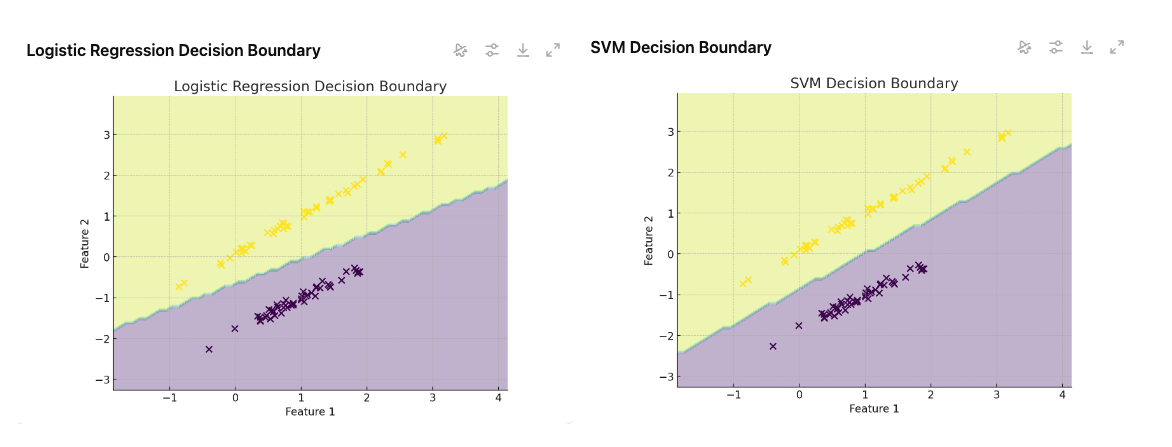
위 그래프는 데이터를 두 가지 집단으로 분류하는 것을 시각화한 것이다. 여기서 검은색 선은 결정 경계를 의미하며, 두 클래스를 구분하는 역할을 한다.
결정함수 (Decision Function)
분류 모델이 특정 입력데이터가 어느 클래스에 속하는지 판단하는 기준을 제공하는 함수. 입력 데이터의 특징을 활용해, 모델이 학습한 규칙에 따라 각 클래스에 속할 점수를 계산하여, 클래스에 속할 가능성을 평가한다.
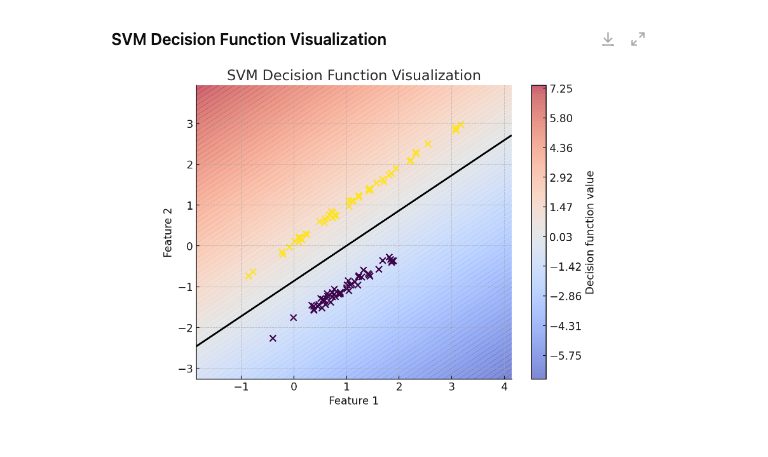
위 그래프는 SVM을 통한 분류를 시각화 한 것으로, 그래프에서 색상은의 농도는 결정 함수 값의 크기를 나타내며, 색이 진할수록 해당 클래스에 속할 가능성이 높은 영역을 의미한다. 검은색 선은 이전 이미지와 같이 결정 경계를 나타낸다.
분류기의 입출력 관계
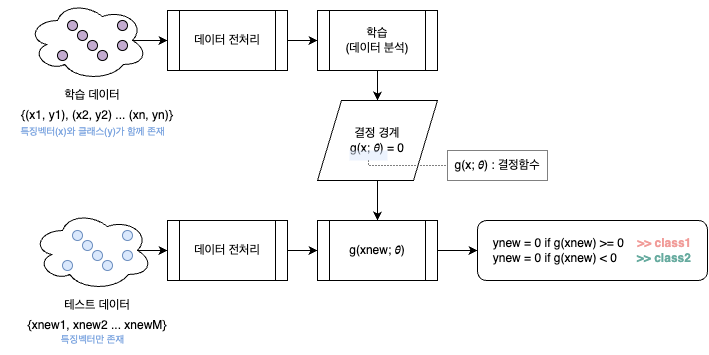
먼저, 학습 데이터 집합을 통해 학습을 진행하면 학습의 결과로 “결정 경계”와 “결정 함수”를 얻을 수 있다. 여기서 결정 함수는 g(x) 라는 형태로 정의를 하며, 예시가 되는 결정 경계면은 g(x) = 0이 되는 선으로 정의를 해보겠다.
이후 테스트 데이터 혹은 현실 세계에 있는 미분류 데이터를 학습한 모델 (=결정함수와 결정경계)에 대입을 했을 때, 출력되는 값이 결정 경계면을 기준으로 어느 쪽으로 속하는지에 따라 입력된 데이터에 대한 분류가 진행된다.
분류 모델의 종류
결정경계를 얻는 두 가지 접근법
| 방법론 | 설명 | 모델 | |
|---|---|---|---|
| 확률 기반 방법 | 데이터 x가 클래스 Ck에 속할 조건부 확률P(Ck | x)를 추정하여 분류를 진행한다. | - 베이즈 분류기 |
| 데이터 기반 방법 | 데이터 간의 관계(거리의 장단 등)를 바탕으로 분류를 진행한다. | - K최근접이웃 분류기 |
모델 종류
| 모델 | 설명 |
|---|---|
| 베이즈 분류기 | 조건부 확률에 기반한 분류 모델로, 특정 데이터가 주어졌을 때 특정 클래스에 속할 확률을 계산하여 예측합니다. 대표적인 예로 나이브 베이즈가 있으며, 독립 변수 가정을 바탕으로 매우 빠르고 간단하게 작동합니다. 주로 텍스트 분류에 많이 사용됩니다. |
| K최근접이웃 분류기(KNN) | 새로운 데이터 포인트의 클래스를 결정할 때, 가장 가까운 K개의 이웃 데이터를 참고하여 다수결로 클래스를 예측하는 모델입니다. 데이터의 분포에 민감하며, 적절한 K값 설정이 중요합니다. 주로 비선형 분류나 클러스터링에 사용됩니다. |
| 로지스틱 회귀 | 선형 회귀에 기반하여 데이터가 특정 클래스에 속할 확률을 예측하는 모델입니다. 시그모이드 함수를 사용하여 출력값을 0과 1 사이로 변환하고, 확률 기반으로 이진 분류 문제를 해결하는 데 유리합니다. |
| 결정 트리 | 데이터를 분할하여 트리 구조로 학습하는 분류 모델로, 각 노드에서 최적의 질문을 찾아 데이터를 두 그룹으로 나누어 예측합니다. 해석이 용이하고 시각화가 가능한 장점이 있지만, 과적합(overfitting)에 취약할 수 있습니다. |
| 서포트벡터머신(SVM) | 초평면을 사용해 데이터를 분리하는 선형 분류 모델입니다. 서포트 벡터라 불리는 중요한 데이터 포인트를 통해 두 클래스 사이의 간격을 최대화하는 방식으로 결정 경계를 형성합니다. 비선형 분류에도 커널을 사용하여 확장할 수 있습니다. |
| 신경망(딥러닝 모델) | 여러 개의 뉴런을 층(layer)으로 연결하여 복잡한 패턴을 학습하는 모델입니다. 깊은 층을 가진 심층 신경망(Deep Neural Network)은 이미지, 음성 인식 등 복잡한 문제에서 높은 성능을 보이며, 학습을 위해 대량의 데이터와 연산이 요구됩니다. |
Comments