
머신러닝의 기본 요소
| 기본 요소 | 설명 |
|---|---|
| 데이터와 데이터 분포 | |
| 특징과 특징 추출 | |
| 성능 평가 |
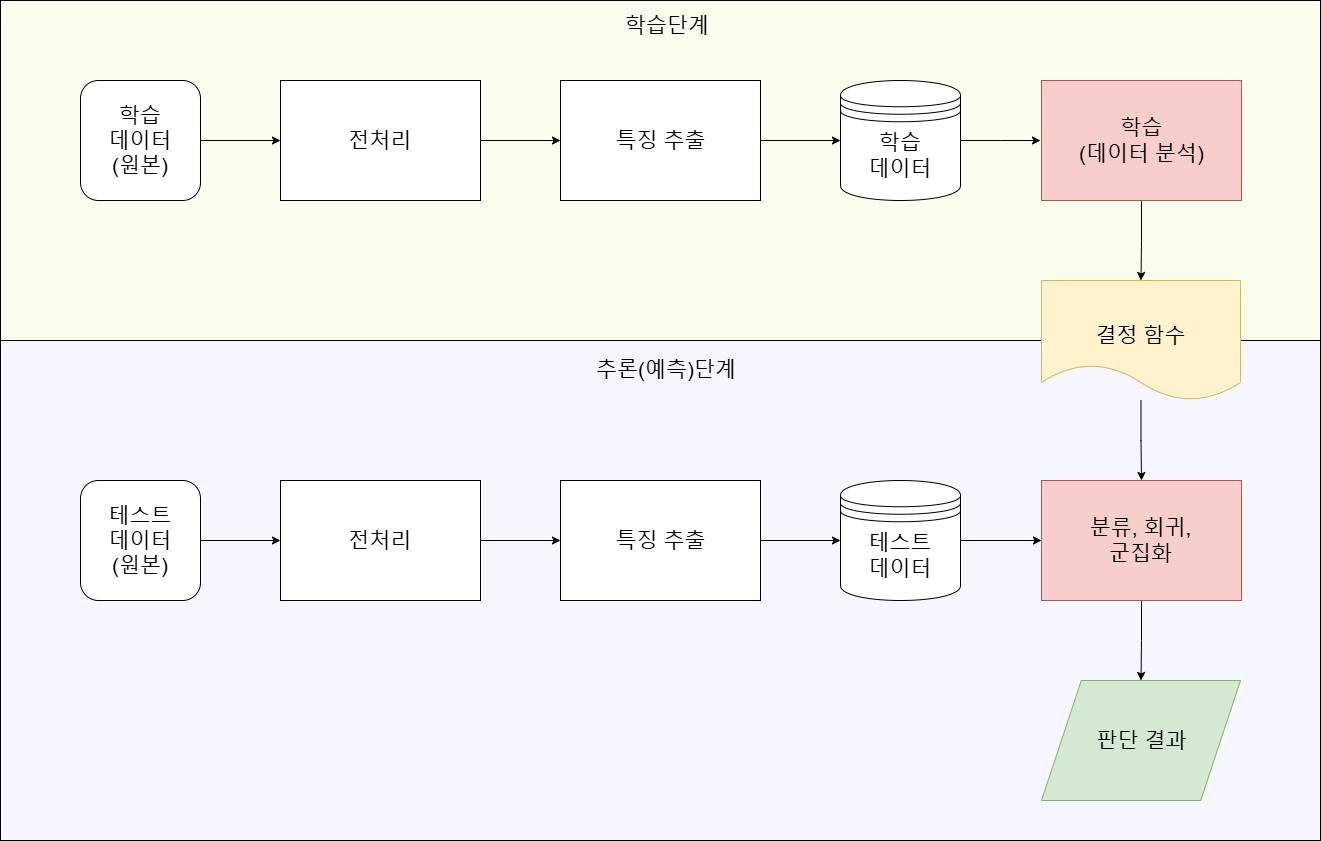
데이터와 데이터 분포
데이터
머신러닝에서 하나의 데이터는 n차원의 열벡터로 다루어진다. 이는 n 차원의 공간 상에 표현했을 때 하나의 점이 된다. 즉, 머신러닝에서 그래프를 그렸을 때의 점 하나는 보통 데이터 하나를 의미한다.
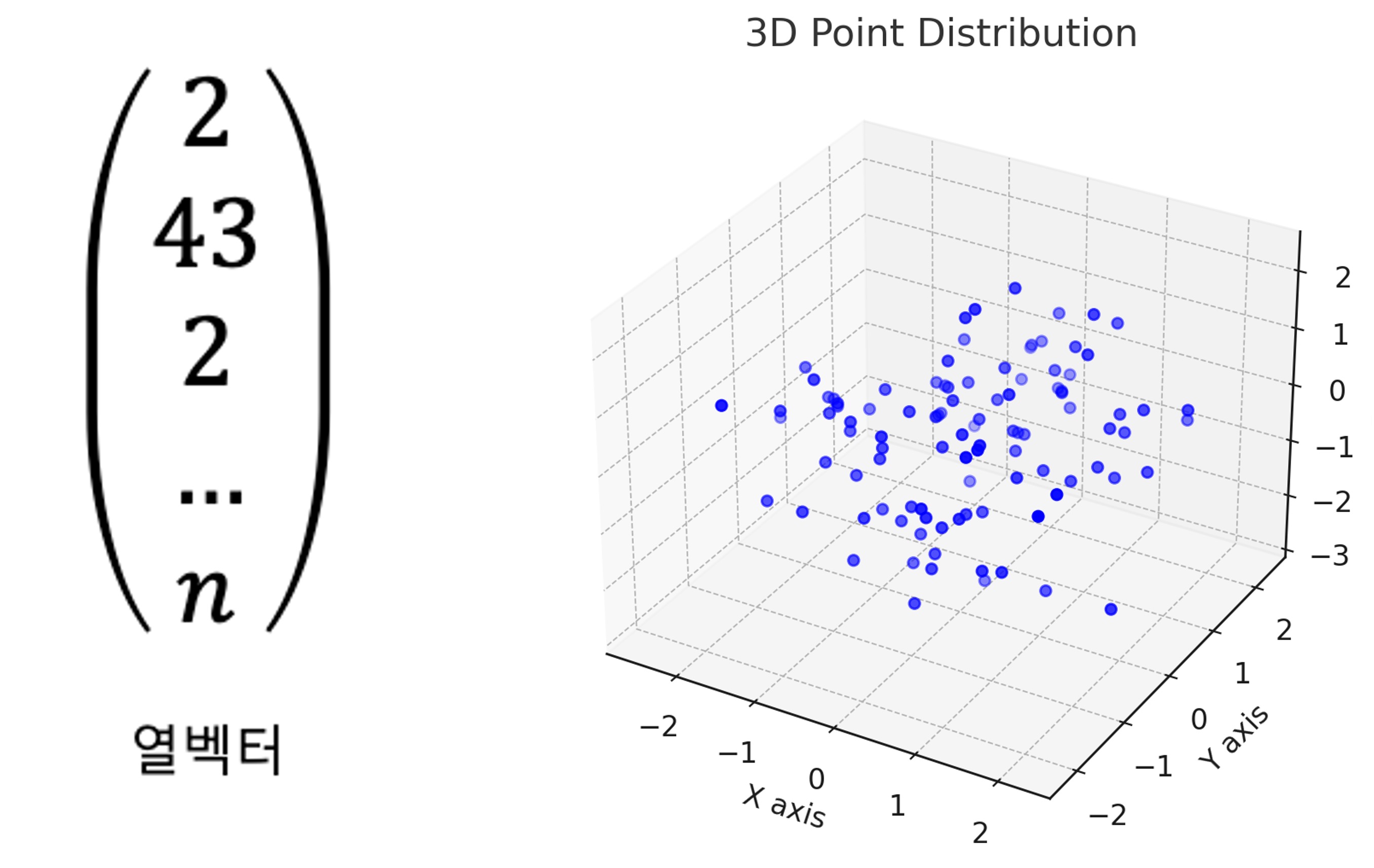
머신러닝에서는 데이터가 벡터로 표현되므로, 데이터에 대한 모든 처리 또한 벡터 연산으로 정의된다.
데이터 분포
머신러닝에서는 데이터 하나 하나가 가지는 특성 뿐 아니라, 전체 데이터 집합이 이루는 분포 특성을 고려해 특징을 추출하고 학습을 수행하게 된다. 여기서의 분포 특성이란, 공간상에서 점들이 분포된 모양을 뜻한다. 앞서 데이터가 n 차원 공간 상에 표현되는 “하나의 점” 이라고 표현을 했는데, 데이터의 분포는 공간상에서 점들(=데이터들)이 어떻게 위치하고 서로 떨어져있고 붙어있는지를 뜻하는 것이라고도 할 수 있다.
학습 데이터와 전체 데이터, 표본집단과 모집단
모집단이란 연구나 분석의 대상으로 삼는 모든 개체나 데이터를 포함하는 전체 집단을 의미하는 것이다. 쉽게 말해 통계에서 “데이터 전체”를 가리키는 말이다. 그리고 표본집단은 이러한 모집단에서 추출한 일부의 데이터 집단을 의미하는 말이다.
머신러닝 학습 데이터는 개발 시스템이 실제로 다루게 될 데이터의 일부에 지나지 않는다. 즉, 머신러닝 학습 시스템에서 사용되는 학습 데이터는 “표본집단”에 해당한다는 것이다.
그런데도 현재의 학습 데이터를 이용해 시스템을 개발할 수 있는 것은, 학습 데이터가 앞으로 주어질 데이터들과 동일한 분포 특성을 가진다고 기대하기 때문이다.
특징과 특징추출
특징
특징이란 데이터의 중요한 속성이나 설명(독립)변수로 정의할 수 있다. 이러한 특징은 머신러닝 모델이 학습을 하고 예측하는 데 필요한 정보로, 각 데이터를 구성하는, 혹은 각 데이터를 표현하는 개별적인 요소나 값 들을 의미한다.
특징추출
주어진 데이터를 그대로 사용할 경우, 계산량이 많아지고 데이터를 저장할 메모리 비용이 비효율적일 수 있다. 계산량을 줄이고, 메모리를 절약하기 위해서 머신러닝에 필요한 데이터를 추출하거나 필요 없는 데이터를 버리는 작업이 필요한데, 이것을 바로 특징 추출이라고 한다.
성능 평가
머신러닝 모델 학습의 궁극적인 목표는 “앞으로 주어질 새로운 데이터에 대한 성능을 최대화 하는 것” 이라고 할 수 있다. 이를 위해서는 모델의 성능을 평가하는 작업이 필요하다.
목적함수
목적함수란 학습 시스템의 평가를 위해 주어진 데이터 집합을 이용해 학습 시스템이 달성해야 하는 목표를 기계가 알 수 있는 수학적 함수로 정의한 것이다. 즉, 목적함수는 모델이 학습을 통해 최소화 하거나 최대화 하려는 수식이 된다.
오차함수
오차함수는 모델의 예측값과 실제값 간의 차이(=오차)를 계산하는 함수로, 대표적인 목적함수 중 하나이다. 즉, 오차함수를 목적함수로 할 경우, 학습의 목적은 “오차를 최소화 하는 것” 이 될 것이다.
오차함수를 이용한 성능 평가 기준
| 오차 함수의 종류 | 원어 | 설명 |
|---|---|---|
| 학습 오차 | training error | - 학습에 사용된 데이터 집합에 대해 계산된 오차 |
| 테스트 오차 | test error | - 학습에 사용되지 않은 새로운 데이터 집합에 대해 계산된 오차 |
| 일반화 오차 | generalization error | - 현실 세계의 모든 데이터 분포 전체에 대해 정의되는 오차 - 현실적으로 계산이 불가능한 궁극적인 개념으로, - 일반화 오차 대신 테스트 오차로 평가한다. |
일반화 오차의 추정
궁극적인 학습의 목표는 모든 데이터에 대한 오차를 최소화 하는, 즉 일반화 오차를 최소화 하는 것이다. 하지만 현실적으로 실제 존재하는 모든 데이터를 관찰하고 식별하는 것은 불가능하므로, 일반화 오차 대신 테스트 오차를 통해 모델의 성능을 평가하게 된다.
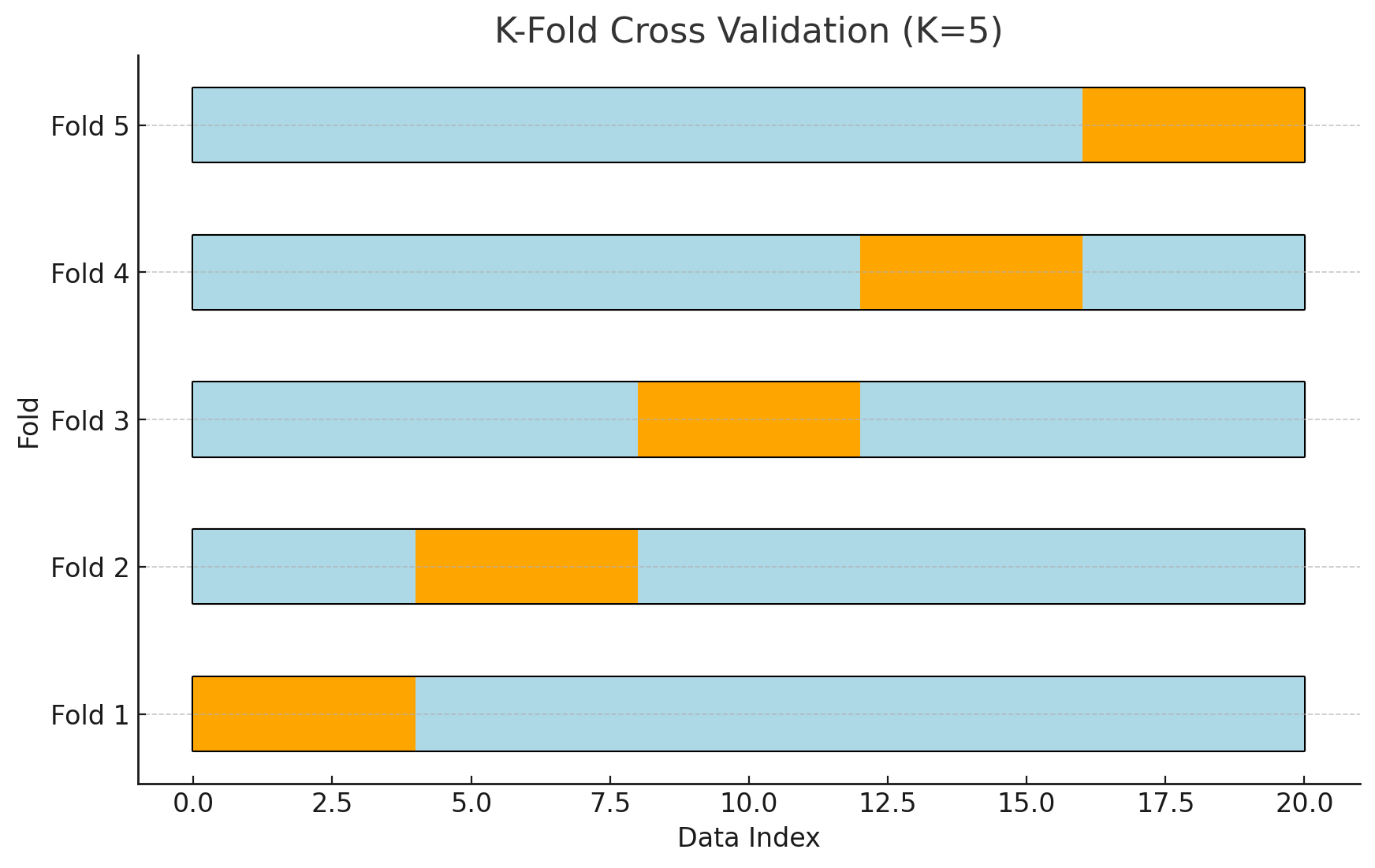
이러한 테스트 오차 계산에 있어서, 한정적인 테스트 데이터셋을 이용하 좀 더 일반화오차에 가까운 오차 계산을 하기 위한 여러 노력들이 있었다. 대표적인 것이 K-Fold 교차 검증법, 교차 검증법 등이 있다.
K-Fold 교차 검증법 (K-fold cross validation)은 “K-Fold” 와 “교차 검증”이라는 두 가지 개념을 나눠서 보면 쉽게 이해할 수 있다.
(1) K-Fold
주어진 데이터 집합을 K개의 부분집합으로 나누는 것.
(2) 교차 검증
K개로 나눠진 데이터셋을, 그 중 하나의 집합을 검증 데이터셋으로, 나머지 데이터셋을 학습 데이터셋으로 하여 모델을 훈련한 뒤 검증(테스트) 하는 것. 이를 각각의 나눠진 데이터셋 수만큼 교차해서 K번 진행하게 된다.
이러한 K-Fold 교차 검증을 통해 얻은 오차들을 평균을 내면, 단일 학습시보다 일반화 오차에 더 가까운 평가값을 얻게 된다고 알려져 있다.
Comments